Подумайте, не сделать ли приложение событийно-управляемым (2)
| | |
Здесь будет продолжено обсуждение, начатое в совете 20, а также проиллюстрировано использование функции tselect в приложениях и рассмотрены некоторые другие аспекты событийно-управляемого программирования. Вернемся к архитектуре с двумя соединениями из совета 19.
Взглянув на программу xout2 (листинг 3.13), вы увидите, что она не управляется событиями. Отправив сообщение удаленному хосту, вы не возвращаетесь к чтению новых данных из стандартного ввода, пока не придет подтверждение Причина в том, что таймер может сбросить новое сообщение. Если бы вы взвели таймер для следующего сообщения, не дождавшись подтверждения, то никогда не узнали бы, подтверждено старое сообщение или нет.
Проблема, конечно, в том, что в программе xout2 только один таймер и поэтому она не может ждать более одного сообщения в каждый момент. Воспользовавшись t select, вы сможете получить несколько таймеров из одного, предоставляемого select.
Представьте, что внешняя система из совета 19 - это шлюз, отправляющий сообщение третьей системе по ненадежному протоколу. Например, он мог бы посылать датаграммы в радиорелейную сеть. Предположим, что сам шлюз не дает информации о том, было ли сообщение успешно доставлено. Он просто переправляет сообщение и возвращает подтверждение, полученное от третьей системы.
Чтобы в какой-то мере обеспечить надежность, новый писатель xout3 повторно посылает сообщение (но только один раз), если в течение определенного времени не получает подтверждения. Если и второе сообщение не подтверждено, xout3 протоколирует этот факт и отбрасывает сообщение. Чтобы ассоциировать подтверждение с сообщением, на которое оно поступило, xout 3 включает в каждое сообщение некий признак. Конечный получатель сообщения возвращает этот признак в составе подтверждения. Начнем с рассмотрения секции объявлений xout3 (листинг 3.18)
Листинг 3.18. Объявления для программы xout3
1 #define ACK 0x6 /* Символ подтверждения АСК. */
2 #define MRSZ 128 /* Максимальное число неподтвержденных сообщений.*/
3 #define T1 3000 /* Ждать 3 с до первого АСК */
4 #define T2 5000 /* и 5 с до второго АСК. */
5 #define ACKSZ ( sizeof ( u_int32_t ) + 1 )
6 typedef struct /* Пакет данных. */
7 {
8 u_int32_t len; /* Длина признака и данных. */
9 u_int32_t cookie; /* Признак сообщения. */
10 char buf[ 128 ]; /* Сообщение. */
11 } packet_t;
12 typedef struct /* Структура сообщения. */
13 {
14 packet_t pkt; /* Указатель на сохраненное сообщение.*/
15 int id; /* Идентификатор таймера. */
16 } msgrec_t;
17 static msgrec_t mr[ MRSZ ];
18 static SOCKET s;
Объявления
5 Признак, включаемый в каждое сообщение, — это 32- разрядный порядковый номер сообщения. Подтверждение от удаленного хоста определяется как ASCII-символ АСК, за которым следует признак подтверждаемого сообщения. Поэтому константа ASCZ вычисляется как длина признака плюс 1.
6-11 Тип packet_t определяет структуру посылаемого пакета. Поскольку сообщения могут быть переменной длины, в каждый пакет включена длина сообщения. Удаленное приложение может использовать это поле для разбиения потока данных на отдельные записи (об этом шла речь в совете 6). Поле len - это общая длина самого сообщения и признака. Проблемы, связанные с упаковкой структур, рассматриваются в замечаниях после листинга 2.15.
12-16 Структура msgrec_t содержит структуру packet_t, посланную удаленному хосту. Пакет сохраняется на случай, если придется послать его повторно. Поле id - это идентификатор таймера, выступающего в роли таймера ретрансмиссии для этого сообщения.
17 С каждым неподтвержденным сообщением связана структура msgrec_t. Все они хранятся в массиве mr.
Теперь обратимся к функции main программы xout3 (листинг 3.19).
Листинг 3.19. Функция main программы xout3
1 int main( int argc, char **argv )
2 {
3 fd_set allreads;
4 fd_set readmask;
5 msgrec_t *mp;
6 int rc;
7 int mid;
8 int cnt = 0;
9 u_int32_t msgid = 0;
10 char ack[ ACKSZ ];
11 INIT();
12 s = tcp_client( argv[ 1 ], argv[ 2 ] );
13 FD_ZERO( &allreads );
14 FD_SET( s, &allreads );
15 FD_SET( 0, &allreads );
16 for ( mp = mr; mp < mr + MRSZ; mp++ )
17 mp->pkt.len = -1;
18 for ( ; ; )
19 {
20 readmask = allreads;
21 rc-= tselectf s + 1, &readmask, NULL, NULL );
22 if ( rc < 0 )
23 error( 1, errno, "ошибка вызова tselect" );
24 if ( rc == 0 )
25 error( 1, 0, "tselect сказала, что нет событий\n")
26 if ( FD_ISSET( s, &readmask ) )
27 {
28 rc = recv( s, ack + cnt, ACKSZ - cnt, 0 );
29 if ( rc == 0 )
30 error( 1, 0, "сервер отсоединился\n");
31 else if ( rc < 0 )
32 error( 1, errno, "ошибка вызова recv" );
33 if ( ( cnt += rc ) < ACKSZ ) /* Целое сообщение? */
34 continue; /* Нет, еще подождем. */
35 cnt =0; /* В следующий раз новое сообщение. */
36 if ( ack[ 0 ] != ACK)
37 {
38 error ( 0,0," предупреждение: неверное подтверждение\n");
39 continue;
40 }
41 memcpy( &mid, ack + 1, sizeof( u_int32_t ) );
42 mp = findmsgrec( mid );
43 if ( mp != NULL)
44 {
45 untimeout( mp->id ); /* Отменить таймер.*/
46 freemsgrecf mp ); /* Удалить сохраненное сообщение. */
47 }
48 }
49 if ( FD_ISSET( 0, &readmask ) )
50 {
51 mp = getfreerec ();
52 rc = read( 0, mp->pkt.buf, sizeoft mp->pkt.buf )
53 if ( rc < 0 )
54 error( 1, errno, "ошибка вызова read" );
55 mp->pkt.buf[ rc ] = '\0';
56 mp->pkt.cookie = msgid++;
57 mp->pkt.len = htonl( sizeof( u_int32_t ) + rc );
58 if ( send( s, &mp->pkt,
59 2 * sizeof( u_int32_t ) + rc, 0 ) < 0 )
60 error( 1, errno, "ошибка вызова send" );
61 mp->id = timeout( ( tofunc_t )lost_ACK, mp, Tl );
62 }
63 }
64 }
Инициализация
11-15 Так же, как и в программе xout2, соединяемся с удаленным хостои и инициализируем маски событий для tselect, устанавливая в них биты для дескрипторов stdin и сокета, который возвратилa tcp_client
16-17 Помечаем все структуры msgrec_t как свободные, записывая в поле длины пакета
18-25 Вызываем tselect точно так же, как select, только не передаем последний параметр (времени ожидания). Если tselect возвращает ошибку или нуль, то выводим диагностическое сообщение и завершаем программу. В отличие от select возврат нуля из tselect - свидетельство ошибки, так как все тайм-ауты обрабатываются внутри.
Обработка входных данных из сокета
26-32 При получении события чтения из сокета ожидаем подтверждение. В совете 6 говорилось о том, что нельзя применить recv в считывании ASCZ байт, поскольку, возможно, пришли еще не все данные. Нельзя воспользоваться и функцией типа readn, которая не возвращает управления до получения указанного числа байт, так как это противоречило бы событийно-управляемой архитектуре приложения, - ни одно событие не может быть обработано, пока readn не вернет управления. Поэтому пытаемся прочесть столько данных, сколько необходимо для завершения обработки текущего подтверждения. В переменной cnt хранится число ранее прочитанных байт, поэтому ASCZ - cnt - это число недостающих байт.
33-35 Если общее число прочитанных байт меньше ASCZ, то возвращаемся к началу цикла и назначаем tselect ожидание прихода следующей партии данных или иного события. Если после только что сделанного вызова recv подтверждение получено, то сбрасываем cnt в нуль в ожидании следующего подтверждения (к этому моменту не было прочитано еще ни одного байта следующего подтверждения).
36-40 Далее, в соответствии с советом 11, выполняем проверку правильности полученных данных. Если сообщение - некорректное подтверждение, печатаем диагностическое сообщение и продолжаем работу. Возможно, здесь было бы правильнее завершить программу, так как удаленный хост послал неожиданные данные.
41- 42 Наконец, извлекаем из подтверждения признак сообщения, вызываем findmsgrec для получения указателя на структуру msgrec_t, ассоциированную с сообщением, и используем ее для отмены таймера, после чего освобождаем msgrec_t. Функции findmsgrec и freemsgrec приведены в листинге 3.20.
Обработка данных из стандартного ввода
51-57 Когда tselect сообщает о событии ввода из stdin, получаем структуру msgrec_t и считываем сообщение в пакет данных. Присваиваем сообщению порядковый номер, пользуясь счетчиком msgid, и сохраняем его в поле cookie пакета. Обратите внимание, что вызывать htonl не нужно, так как удаленный хост не анализирует признак, а возвращает его без изменения. Записываем в поля пакета полную длину сообщения вместе с признаком. На этот раз вызываем htonl, так как удаленный хост использует это поле для чтения оставшейся части сообщения (совет 28).
55-61 Посылаем подготовленный пакет удаленному хосту и взводим таймер ретрансмиссии, обращаясь к функции timeout.
Оставшиеся функции программы xout3 приведены в листинге 3.20.
Листинг 3.20. Вспомогательные функции программы xout3
1 msgrec_t *getfreerec( void )
2 {
3 msgrec_t *mp;
4 for ( mp = mr; mp < mr + MRSZ; mp++ )
5 if ( mp->pkt.len == -1 ) /* Запись свободна? */
6 return mp;
7 error(1,0, "getfreerec: исчерпан пул записей сообщений\n" );
8 return NULL; /* "Во избежание предупреждений компилятора.*/
9 }
10 msgrec_t *findmsgrec( u_int32_t mid )
11 {
12 msgrec_t *mp;
13 for ( mp = mr; mp < mr + MRSZ; mp++ )
14 if ( mp->pkt.len != -1 && mp->pkt.cookie == mid )
15 return mp;
16 error (0, 0,"findmsgrec: нет сообщения, соответствующего ACK %d\n", mid);
17 return NULL;
18 }
19 void freemsgrec( msgrec_t *mp )
20 {
21 if ( mp->pkt.len == -1 )
22 error(1,0, "freemsgrec: запись сообщения уже освобождена\n" };
23 mp->pkt.len = -1;
24 }
25 gtatic void drop( msgrec_t *mp )
26 {
27 error( 0, 0, "Сообщение отбрасывается: %s", mp->pkt.buf );
28 freemsgrec( mp );
29 }
30 static void lost_ACK( msgrec_t *mp )
31 {
32 error( 0, 0, "Повтор сообщения: %s", mp->pkt.buf );
33 if ( send( s, &mp->pkt,
34 sizeof( u_int32_t ) + ntohl( mp->pkt.len ), 0 ) < 0 )
35 error ( 1, errno, " потерян АСК: ошибка вызова send" );
36 mp->id = timeout) ( tofunc_t )drop, mp, T2 );
37 }
getfreerec
1-9 Данная функция ищет свободную запись в таблице mr. Просматриваем последовательно весь массив, пока не найдем пакет с длиной -1. Это означает, что запись свободна. Если бы массив mr был больше, то можно было бы завести список свободных, как было сделано для записей типа tevent_t в листинге 3.15.
findmsgrec
10-18 Эта функция почти идентичная get f reerec, только на этот раз ищем запись с заданным признаком сообщения.
freemsgrec
19-24 Убедившись, что данная запись занята, устанавливаем длину пакета в -1, помечая тем самым, что теперь она свободна.
drop
25-29 Данная функция вызывается, если не пришло подтверждение на второе посланное сообщение (см. lost_ACK). Пишем в протокол диагностику и отбрасываем запись, вызывая freemsgrec.
lost_ACK
30-37 Эта функция вызывается, если не пришло подтверждение на первое сообщение. Посылаем сообщение повторно и взводим новый таймер ре-трансмиссии, указывая, что при его срабатывании надо вызвать функцию drop.
Для тестирования xout3 напишем серверное приложение, которое случайным образом отбрасывает сообщения. Назовем этот сервер extsys (сокращение от external system - внешняя система). Его текст приведен в листинге 3.21.
Листинг 3.21. Внешняя система
extsys.c
1 #include "etcp.h"
2 #define COOKIESZ 4 /* Так установлено клиентом. */
3 int main ( int argc, char **argv )
4 {
5 SOCKET s;
6 SOCKET s1;
7 int rc;
8 char buf[ 128 ] ;
9 INIT();
10 s = tcp_server( NULL, argv[ 1 ] );
11 s1 = accept( s, NULL, NULL );
12 if ( !isvalidsock) s1 ) )
13 error( 1, errno, "ошибка вызова accept" );
!4 srand( 127 );
15 for ( ;; )
16 {
17 rc = readvrec( s1, buf, sizeof( buf ) );
18 if ( rc == 0 )
19 error( 1, 0, "клиент отсоединился\n" );
20 if ( rc < 0 )
21 error( 1, errno, "ошибка вызова recv" );
22 if ( rand() % 100 < 33 )
23 continue;
24 write! 1, buf + COOKIESZ, rc - COOKIESZ );
25 memmove( buf + 1, buf, COOKIESZ );
26 buf[ 0 ] = ' \006';
27 if ( send( s1, buf, 1 + COOKIESZ, 0 ) < 0 )
28 error( 1, errno, "ошибка вызова send" );
29 }
30 }
Инициализация
9- 14 Выполняем обычную инициализацию сервера и вызываем функцию srand для инициализации генератора случайных чисел.
Премечание: Функция rand из стандартной библиотеки С работает быстрои проста в применении, но имеет ряд нежелательных свойств. Хотя для демонстрации xout3 она вполне пригодна, но для серьезного моделирования нужно было бы воспользоваться более развитым генератором случайных чисел [Knuth 1998].
17-21 Вызываем функцию readvrec для чтения записи переменной длины, посланной xout3.
22-23 Случайным образом отбрасываем примерно треть получаемых сообщений.
24-28 Если сообщение не отброшено, то выводим его на stdout, сдвигаем в буфере признак на один символ вправо, добавляем в начало символ АСК и возвращаем подтверждение клиенту.
Вы тестировали xout3, запустив extsys в одном окне и воспользовавшись конвейером из совета 20 в другом (рис. 3.7).
Можно сделать следующие замечания по поводу работы xout3:
доставка сообщений по порядку не гарантирована. На примере сообщении 17 и 20 на рис. 3.8 вы видите, что повторно посланное сообщение нарушило порядок;
можно было увеличить число повторных попыток, добавив счетчик попыток в структуру msgrec_t и заставив функцию lost_ACK продолжать попытки отправить сообщение до исчерпания счетчика;
легко модифицировать xout3 так, чтобы она работала по протоколу UDP а не TCP. Это стало бы первым шагом на пути предоставления надежного UDP-сервиса (совет 8);
если бы приложение работало с большим числом сокетов (и использовало функцию tselect), то имело бы смысл вынести встроенный код геаdn в отдельную функцию. Такая функция могла бы получать на входе структуру, содержащую cnt, указатель на буфер ввода (или сам буфер) и адрес функции, которую нужно вызвать после получения полного сообщения; р в качестве примера xout3, пожалуй, выглядит чересчур искусственно, особенно в контексте совета 19, но так или иначе она иллюстрирует, как можно решить задачу, часто возникающую на практике.
|
bsd $ mp I xout3 localhost 9000 xout3: Повтор сообщения: message 3 xout3: Повтор сообщения: message 4 xout3: Повтор сообщения: message 5 xoutS: Сообщение отбрасывается: message 4 xout3: Сообщение отбрасывается: message 5 xout3: Повтор сообщения: message 11 xout3: Повтор сообщения: message 14 xout3: Сообщение отбрасывается: message 11 xout3: Повтор сообщения: message 16 xout3: Повтор сообщения: message 17 xout3: Сообщение отбрасывается: message 14 xout3: Повтор сообщения: message 19 xout3: Повтор сообщения: message 20 xout3: Сообщение отбрасывается: message 16 xout3: Сервер отсоединился Broken pipe bsd $ |
bsd $ extsys 9000 message 1 message 2 message 3 message 6 message 7 message 8 message 9 message 10 message 12 message 13 message 15 message 18 message 17 message 21 message 20 message 23 ^C сервер остановлен bsd $ |
Рис. 3.7. Демонстрация xout 3
Не прерывайте состояние TIME-WAIT для закрытия соединения
| | |
В этом разделе рассказывается о том, что такое состояние TIME-WAIT в протоколе TCP, для чего оно служит и почему не следует пытаться обойти его.
Поскольку состояние TIME-WAIT запрятано глубоко в недрах конечного автомата, управляющего работой TCP, многие программисты только подозреваю о его существовании и смутно представляют себе назначение и важность этого с стояния. Писать приложения TCP/IP можно, ничего не зная о состоянии ТIME-WAIT, но необходимо разобраться в странном, на первый взгляд, поведении приложения (совет 23). Это позволит избежать непредвиденных последствий.
Рассмотрим состояние TIME-WAIT и определим, каково его место в работе TCP-соединения. Затем будет рассказано о назначении этого состояния и его важности, а также, почему и каким образом некоторые программисты пытаются обойти это состояние. В конце дано правильное решение этой задачи.
Сервер должен устанавливать опцию SO_REUSEADDR
| | |
В сетевых конференциях очень часто задают вопрос: «Когда сервер «падает» или нормально завершает сеанс, я пытаюсь его перезапустить и получаю ошибку «Address already in use». А через несколько минут сервер перезапускается нормаль но. Как сделать так, чтобы сервер рестартовал немедленно?» Чтобы проиллюстрировать эту проблему, напишем сервер эхо-контроля, который будет работа именно так (листинг 3.22).
Листинг 3.22. Некорректный сервер эхо-контроля
1 #include "etcp.h"
2 int main( int argc, char **argv)
3 {
4 struct sockaddr_in local;
5 SOCKET s;
6 SOCKET s1;
7 int rc;
8 char buf[ 1024 ];
9 INIT();
10 s = socket( PF_INET, SOCK_STREAM, 0 );
11 if ( !isvalidsock( s ) )
12 error( 1, errno, "He могу получить сокет" ) ;
13 bzero( &local, sizeof( local ) );
14 local.sin_family = AF_INET;
15 local.sin_port = htons( 9000 );
16 local.sin_addr.s_addr = htonl( INADDR_ANY );
17 if ( bind( s, ( struct sockaddr * )&local,
18 sizeof( local ) ) < 0 )
19 error( 1, errno, "He могу привязать сокет" );
20 if ( listen) s, NLISTEN ) < 0 )
21 error( 1, errno, "ошибка вызова listen" );
22 si = accept! s, NULL, NULL );
23 if ( !isvalidsock( s1 ) )
24 error( 1, errno, "ошибка вызова accept" );
25 for ( ;; )
26 {
27 rc = recv( s1, buf, sizeof( buf ), 0 );
28 if ( rc < 0 )
29 error( 1, errno, "ошибка вызова recv" );
30 if ( rc == 0 )
31 error( 1, 0, "Клиент отсоединился\n" );
32 rc = send( s1, buf, rc, 0 );
33 if ( rc < 0 )
34 error( 1, errno, "ошибка вызова send" );
35 }
36 }
На первый взгляд, сервер выглядит вполне нормально, только номер порта «зашит» в код. Если запустить его в одном окне и соединиться с ним с помощью программы telnet, запущенной в другом окне, то получится ожидаемый результат. (На рис. 3.9 опущены сообщения telnet об установлении соединения.)
Проверив, что сервер работает, останавливаете клиента, переходя в режим команд telnet и вводя команду завершения. Обратите внимание, что если немедленно повторить весь эксперимент, то будет тот же результат. Таким образом, adserver перезапускается без проблем.
А теперь проделайте все еще раз, но только остановите сервер. При попытке перезапустить сервер вы получите сообщение «Address already in use» (сообщение Разбито на две строчки). Разница в том, что во втором эксперименте вы остановили сервер, а не клиент рис. 3.10.
|
bsd $ badserver badserver: Клиент отсоединился bsd $ : badserver badserver : Клиент отсоединился bsd $ |
bsd $ telnet localhost 9000 hello hello ^] telnet> quit Клиент завершил сеанс. Connection closed. Сервер перезапущен. bsd $ telnet localhost 9000 world world ^] telnet> quit Клиент завершил сеанс. Connection closed bsd $ |
Рис. 3.9. Завершение работы клиента
|
bsd $ badeerver ^C Сервер остановлен bsd $ badserver badserver: He могу привязать сокет: Address already in use (48) bsd $ |
bsd $ telnet localhost 9000 hello again hello again Connection closed by foreign host bsd $ |
Рис. 3.10. Завершение работы сервера
Чтобы разобраться, что происходит, нужно помнить о двух вещах:
состоянии TIME-WAIT протокола TCP;
TCP-соединение полностью определено четырьмя факторами (локальный адрес, локальный порт, удаленный адрес, удаленный порт).
Как было сказано в совете 22, сторона соединения, которая выполняет активное закрытие (посылает первый FIN), переходит в состояние TIME-WAIT и остается в нем в течение 2MSL. Это первый ключ к пониманию того, что вы наблюдали в двух предыдущих примерах: если активное закрытие выполняет клиент, то можно перезапустить обе стороны соединения. Если же активное закрытие выполняет сервер, то его рестартовать нельзя. TCP не позволяет это сделать, так как предыдущее соединение все еще находится в состоянии TIME-WAIT.
Если бы сервер перезапустился и с ним соединился клиент, то возникло новое соединение, возможно, даже с другим удаленным хостом. Как было сказано, TCP-соединение полностью определяется локальными и удаленными адресами и номерами портов, так что даже если с вами соединился клиент с того же у ленного хоста, проблемы не возникнет при другом номере удаленного порта.
Примечание: Даже если клиент с того же удаленного хоста воспользуется тем же номером порта, проблемы может и не возникнуть. Традиционно реализация BSD разрешает такое соединение, если только порядковый номер посланного клиентом сегмента SYN больше последнего порядкового номера, зарегистрированного соединением, которое находится в состоянии TIME- WAIT.
Возникает вопрос: почему TCP возвращает ошибку, когда делается попытка перезапустить сервер? Причина не в TCP, который требует только уникальности указанных факторов, а в API сокетов, требующем двух вызовов для полного определения этой четверки. В момент вызова bind еще неизвестно, последует ли за ним connect, и, если последует, то будет ли в нем указано новое соединение, или он попытается повторно использовать существующее. В книге [Torek 1994] автор - и не он один - предлагает заменить вызовы bind, connect и listen одной функцией, реализующей функциональность всех трех. Это даст возможность TCP выявить, действительно ли задается уже используемая четверка, не отвергая попыток перезапустить закрывшийся сервер, который оставил соединение в состоянии TIME-WAIT. К сожалению, элегантное решение Терека не было одобрено.
Но существует простое решение этой проблемы. Можно разрешить TCP привязку к уже используемому порту, задав опцию сокета SO_REUSEADDR. Чтобы проверить, как это работает, вставим между строками 7 и 8 файла badserver. с строку
const int on = 1;
а между строками 12 и 13 - строки
if (setsockopt(s, SOL_SOCKET, SO_REUSEADDR, &on, sizeoff on ) ) )
error( 1, errno, "ошибка вызова setsockopt");
Заметьте, что вызов setsockopt должен предшествовать вызову bind. Если назвать исправленную программу goodserver и повторить эксперимент (рис. 3.11), то получите такой результат:
|
bsd $ goodserver ^С Сервер остановлен. bsd $ |
bsd $ telnet localhost 9000 hello once again hello once again Connection closed by foreign host Сервер перезапущен. bsd $ telnet localhoet 9000 hello one last time hello one last time |
Рис. 3.11. Завершение работы сервера, в котором используется опция SO_REUSEADDR
Теперь вы смогли перезапустить сервер, не дожидаясь выхода предыдущего соединения из состояния TIME-WAIT. Поэтому в сервере всегда надо устанавливать опцию сокета SO_REUSEADDR. Обратите внимание, что в предлагаемом каркасе в функции tcp_server это уже делается.
Некоторые, в том числе авторы книг, считают, что задание опции SO_REUSEADDR опасно, так как позволяет TCP создать четверку, идентичную уже используемой, и таким образом создать проблему. Это ошибка. Например, если попытаться создать два идентичных прослушивающих сокета, то TCP отвергнет операцию привязки даже если вы зададите опцию SO_REUSEADDR:
bsd $ goodserver &
[1] 1883
bsd $ goodserver
goodserver: He могу привязать сокет: Address already in use (48)
bsd $
Аналогично если вы привяжете одни и те же локальный адрес и порт к двум разным клиентам, задав SO_REUSEADDR, то bind для второго клиента завершится успешно. Однако на попытку второго клиента связаться с тем же удаленным хостом и портом, что и первый, TCP ответит отказом.
Помните, что нет причин, мешающих установке опции SO_REUSEADDR в сервере. Это позволяет перезапустить сервер сразу после его завершения. Если же этого не сделать, то сервер, выполнявший активное закрытие соединения, не перезапустится.
Примечание: В книге [Stevens 1998] отмечено, что с опцией SO_REUSEADDR связана небольшая проблема безопасности. Если сервер привязывает универсальный адрес INADDR_ANY, как это обычно и делается, то другой сервер может установить опцию SO_REUSEADDR и привязать тот же порт, но с конкретным адресом, «похитив» тем самым соединение у первого сервера. Эта проблема действительно существует, особенно для сетевой файловой системы (NFS) даже в среде UNIX, поскольку NFS привязывает порт 2049 из открытого всем диапазона. Однако такая опасность существует не из-за использования NFS опции SO_REUSEADDR, а потому что это может сделать другой сервер. Иными словами, эта опасность имеет место независимо от установки SO_REUSEADDR,так что это не причина для отказа от этой опции.
Следует отметить, что у опции SO_REUSEADDR есть и другие применения. Предположим, например, что сервер работает на машине с несколькими сетевыми интерфейсами и ему необходимо иметь информацию, какой интерфейс клиент указал в качестве адреса назначения. При работе с протоколом TCP это легко, так как серверу достаточно вызвать getsockname после установления соединения. Но, если реализация TCP/IP не поддерживает опции сокета IP_RECVDSTADDR, то UDP-сервер так поступить не может. Однако UDP-сервер может решить эту задачу, установив опцию SO_REUSEADDR и привязав свой хорошо известный порт к конкретным, интересующим его интерфейсам, а универсальный адрес INADDR_ANY - ко всем остальным интерфейсам. Тогда сервер определит указанный клиентом адрес по сокету, в который поступила датаграмма.
Аналогичная схема иногда используется TCP- и UDP-серверами, которые хотят предоставлять разные варианты сервиса в зависимости от адреса, указанного клиентом. Допустим, вы хотите использовать свою версию tcpmux (совет 18) Для предоставления одного набора сервисов, когда клиент соединяется с интерфейсов
По адресу 198.200.200.1, и другого - при соединении клиента с иным интерфейсом. Для этого запускаете экземпляр tcpmux со специальными сервисами на интерфейсе 198.200.200.1, а экземпляр со стандартными сервисами - на всех остальных интерфейсах, указав универсальный адрес INADDR_ANY. Поскольку tcpmux устанавливает опцию SO_REUSEADDR, TCP позволяет повторно привязать порт 1, хотя при второй привязке указан универсальный адрес.
И, наконец, SO_REUSEADDR используется в системах с поддержкой группового вещания, чтобы дать возможность одновременно нескольким приложениям прослушивать входящие датаграммы, вещаемые на группу. Подробнее это рассматривается в книге [Stevens 1998].
По возможности пишите один большой блок вместо нескольких маленьких
| | |
Для этой рекомендации есть несколько причин. Первая очевидна и уже обсуждалась выше: каждое обращение к функциям записи (write, send и т.д.) требует, по меньшей мере, двух контекстных переключений, а это довольно дорогая операция. С другой стороны, многократные операции записи (если не считать случаев типа записи по одному байту) не требуют заметных накладных расходов в приложении. Таким образом, совет избегать лишних системных вызовов- это, скорее, «правила хорошего тона», а не острая необходимость.
Есть, однако, и более серьезная причина избегать многократной записи мелких блоков - эффект алгоритма Нейгла. Этот алгоритм кратко рассмотрен в совете 15. Теперь изучим его взаимодействие с приложениями более детально. Если не принимать в расчет алгоритм Нейгла, то это может привести к неправильному решению задач, так или иначе связанных с ним, и существенному снижению производительности некоторых приложений.
К сожалению, алгоритм Нейгла, равно как и состояние TIME-WAIT, многие программисты понимают недостаточно хорошо. Далее будут рассмотрены причины появления этого алгоритма, способы его отключения и предложены эффективные решения, которые обеспечивают хорошую производительность приложению, оказывая негативного влияния на сеть в целом.
Алгоритм был впервые предложен в 1984 году Джоном Нейглом (RFC 896 [Nagle 1984]) для решения проблем производительности таких программ, как telnet и ей подобных. Обычно эти программы посылают каждое нажатие клавиши в отдельном сегменте, что приводит к засорению сети множеством крохотных датаграмм (tinygrams). Если принять во внимание, что минимальный размер ТСР-сегмента (без данных) равен 40 байт, то накладные расходы при посылке одного байта в сегменте достигают 4000%. Но важнее то, что увеличивается число пакетов в сети. А это приводит к перегрузке и необходимости повторной передачи, из-за чего перегрузка еще более увеличивается. В неблагоприятном случае в сети находится несколько копий каждого сегмента, и пропускная способность резко снижается по сравнению с номинальной.
Соединение считается простаивающим, если в нем нет неподтвержденных данных (то есть хост на другом конце подтвердил все отправленные ему данные). В первоначальном виде алгоритм Нейгла должен был предотвращать описанные выше проблемы. При этом новые данные от приложения не посылаются до тех пор, пока соединение не перейдет в состояние простоя. В результате в соединении не может находиться более одного небольшого неподтвержденного сегмента.
Процедура, описанная в RFC 1122 [Braden 1989] несколько ослабляет это требование, разрешая посылать данные, если их хватает для заполнения целого сегмента. Иными словами, если можно послать не менее MSS байт, то это разрешено, даже если соединение не простаивает. Заметьте, что условие Нейгла при этом по-прежнему выполняется: в соединении находится не более одного небольшого неподтвержденного сегмента.
Многие реализации не следуют этому правилу буквально, применяя алгоритм Нейгла не к сегментам, а к операциям записи. Чтобы понять, в чем разница, предположим, что MSS составляет 1460 байт, приложение записывает 1600 байт, в окнах приема и передачи свободно, по меньшей мере, 2000 байт и соединение простаивает. Если применить алгоритм Нейгла к сегментам, то следует послать 1460 байт, а затем ждать подтверждения перед отправкой следующих 140 байт – алгоритм Нейгла применяется при посылке каждого сегмента. Если же использовать алгоритм Нейгла к операциям записи, то следует послать 1460 байт, а вслед за ними еще 140 байт - алгоритм применяется только тогда, когда приложение передаете TCP новые данные для доставки.
Алгоритм Нейгла работает хорошо и не дает приложениям забить сеть крохотными пакетами. В большинстве случае производительность не хуже, чем в реализации TCP, в которой алгоритм Нейгла отсутствует.
Примечание: Представьте, например, приложение, которое передает ТСP один байт каждые 200 мс. Если период кругового обращения (RTT, для соединения равен одной секунде, то TCP без алгоритма Нейгла будет посылать пять сегментов в секунду с накладными расходами 4000%. При наличии этого алгоритма первый байт отсылается сразу, а следующие четыре байта, поступившие от приложения, будут задержаны, пока не придет подтверждены на первый сегмент. Тогда все четыре байта посылаются сразу. Таким образом, вместо пяти сегментов послано только два, за счет чего накладные расходы уменьшились до 1600% при сохранении той же скорости 5 байт/с.
К сожалению, алгоритм Нейгла может плохо взаимодействовать с другой, добавленной позднее возможностью TCP - отложенным подтверждением.
Когда прибывает сегмент от удаленного хоста, TCP задерживает отправку АСК в надежде, что приложение скоро ответит на только что полученные данные. Поэтому АСК можно будет объединить с данными. Традиционно в системах, производных от BSD, величина задержки составляет 200 мс.
Примечание: В RFC 1122 не говорится о сроке задержки, требуется лишь, чтобы она была не больше 500 мс. Рекомендуется также подтверждать, по крайней мере, каждый второй сегмент.
Отложенное подтверждение служит той же цели, что и алгоритм Нейгла - уменьшить число повторно передаваемых сегментов.
Принцип совместной работы этих механизмов рассмотрим на примере типичного сеанса «запрос/ответ». Как показано на рис. 3.12, клиент посылает короткий запрос серверу, ждет ответа и посылает следующий запрос.
Заметьте, что алгоритм Нейгла не применяется, поскольку клиент не посылает новый сегмент, не дождавшись ответа на предыдущий запрос, вместе с которым приходит и АСК. На стороне сервера задержка подтверждения дает серверу время ответить. Поэтому для каждой пары запрос/ответ нужно всего два сегмента. Если через RTT обозначить период кругового обращения сегмента, а через Тp - время, необходимое серверу для обработки запроса и отправки ответа (в миллисекундах), то на каждую пару запрос/ответ уйдет RTT + Тp мс.
А теперь предположим, что клиент посылает свой запрос в виде двух последовательных операций записи. Часто причина в том, что запрос состоит из заголовка, за которым следуют данные. Например, клиент, который посылает серверу запросы переменной длины, может сначала послать длину запроса, а потом сам запрос.
Примечание: Пример такого типа изображен на рис. 2.17, но там были приняты меры для отправки длины и данных в составе одного сегмента.
На рис. 3.13. показан поток данных.

|
Рис. 3.12. Поток данных из одиночных сегментов сеанса «запрос.ответ» |
Рис. 3.13. Взаимодействие алгоритма Нейгла и отложенного подтверждения |
На этот раз алгоритмы взаимодействуют так, что число сегментов, посланных на каждую пару запрос/ответ, удваивается, и это вносит заметную задержку.
Данные из первой части запроса посылаются немедленно, но алгоритм Нейгла не дает послать вторую часть. Когда серверное приложение получает первую часть запроса, оно не может ответить, так как запрос целиком еще не пришел. Это значит, что перед посылкой подтверждения на первую часть должен истечь тайм-аут установленный таймером отложенного подтверждения. Таким образом, алгоритмы Нейгла и отложенного подтверждения блокируют друг друга: алгоритм Нейгла мешает отправке второй части запроса, пока не придет подтверждение на первую а алгоритм отложенного подтверждения не дает послать АСК, пока не сработает таймер, поскольку сервер ждет вторую часть. Теперь для каждой пары запрос/ответ нужно четыре сегмента и 2 X RTT + Тp + 200 мс. В результате за секунду можно обработать не более пяти пар запрос/ответ, даже если забыть о времени обработки запроса сервером и о периоде кругового обращения.
Примечание: Для многих систем это изложение чрезмерно упрощенное. Например, системы, производные от BSD, каждые 200 мс проверяют все соединения, для которых подтверждение было отложено. При этом АСК посылается независимо от того, сколько времен прошло в действительности. Это означает, что реальная задержка может составлять от 0 до 200 мс, в среднем 100 мс. Однако часто задержка достигает 200мс из-за «фазового эффекта состоящего в том, что ожидание прерывается следующим тактом таймера через 200 мс. Первый же ответ синхронизирует ответы с тактовым генератором. Хороший пример такого поведения см. в работе [Minshall et al. 1999]. I
Последний пример показывает причину проблемы: клиент выполняет последовательность операций «запись, запись, чтение». Любая такая последовательность приводит к нежелательной интерференции между алгоритмом Нейгла и алгоритмом отложенного подтверждения, поэтому ее следует избегать. Иными словами приложение, записывающее небольшие блоки, будет страдать всякий раз, когда хост на другом конце сразу не отвечает.
Представьте приложение, которое занимается сбором данных и каждые 50 мс посылает серверу одно целое число. Если сервер не отвечает на эти сообщения, а просто записывает данные в журнал для последующего анализа, то будет наблюдаться такая же интерференция. Клиент, пославший одно целое, блокируется алгоритмом Нейгла, а затем алгоритмом отложенного подтверждения, например на 200 мс, после чего посылает по четыре целых каждые 200 мс.
Научитесь организовывать тайм-аут для вызова connect
| | |
В совете 7 отмечалось, что для установления TCP-соединения стороны обычно должны обменяться тремя сегментами (это называется трехсторонним квитированием). Как показано на рис. 3.14, эта процедура инициируется вызовом connect со стороны клиента и завершается, когда сервер получает подтверждение АСК на посланный им сегмент SYN.
Примечание: Возможны, конечно, и другие варианты обмена сегментами. Например, одновременный connect, когда сегменты SYN передаются навстречу друг другу. Но в большинстве случаев соединение устанавливается именно так, как показано на рис. 3.14.

Рис. 3.14 Обычная процедура трехстороннего квитирования
При использовании блокирующего сокета вызов connect не возвращает управления, пока не придет подтверждение АСК на посланный клиентом SYN. Поскольку для этого требуется, по меньшей мере, время RTT, а при перегрузке сети или недоступности хоста на другом конце - даже больше, часто бывает полезно прервать вызов connect. Обычно TCP делает это самостоятельно, но время ожидания (как правило, 75 с) может быть слишком велико для приложения. В некоторых реализациях, например в системе Solaris, есть опции сокета для управления величиной тайм-аута connect, но, к сожалению, они имеются не во всех системах.
Избегайте копирования данных.
| | |
Во многих сетевых приложениях, занимающихся, прежде всего, переносом данных между машинами, большая часть времени процессора уходит на копирование данных из одного буфера в другой. В этом разделе будет рассмотрено несколько способов уменьшения объема копирования, что позволит «бесплатно» повысить производительность приложения. Предложение избегать копирования больших объемов данных в памяти оказывается не таким революционным, поскольку именно так всегда и происходит. Массивы передаются не целиком, используются только указатели на них.
Конечно, обычно данные между функциями, работающими внутри одного процесса, не копируются. Но в многопроцессных приложениях часто приходится передавать большие объемы данных от одного процесса другому с помощью того или иного механизма межпроцессного взаимодействия. И даже в рамках одного процесса часто доводится заниматься копированием, если сообщение состоит более чем из двух частей, которые нужно объединить перед отправкой другому процессу или другой машине. Типичный пример такого рода, обсуждавшийся в совете 24, -это добавление заголовка в начало сообщения. Сначала копируется в буфер заголовок, а вслед за ним - само сообщение.
Стремление избегать копирования данных внутри одного процесса - признак хорошего стиля программирования. Если заранее известно, что сообщению будет предшествовать заголовок, то надо оставить для него место в буфере. Иными словами, если ожидается заголовок, описываемый структурой struct hdr, то прочитать данные можно было бы так:
rc = read( fd, buf + sizeof( struct hdr ) ),
sizeoft ( buf ) - sizeof( struct hdr );
Пример применения такой техники содержится в листинге 3.6.
Еще один прием - определить пакет сообщения в виде структуры, одним из элементов которой является заголовок. Тогда можно просто прочитать заголовок в одном из полей:
struct {
struct hdr header; /* Структура определена в другом месте.*/
char data[ DATASZ ];
} packet ;
rc = read( fd, packet, data. sizeof( packet data ) );
Пример использования этого способа был продемонстрирован в листинге 2.15. Там же говорилось, что при определении такой структуры следует проявлять осмотрительность.
Третий, очень гибкий, прием заключается в применении операции записи со сбором - листинги 3.23 (UNIX) и 3.24 (Winsock). Он позволяет объединять части сообщения с различными размерами.
Избежать копирования данных намного труднее, когда есть несколько процессов. Эта проблема часто возникает в системе UNIX, где многопроцессные приложения-распространенная парадигма (рис. 3.4). Обычно в этой ситуации проблема даже острее, так как механизмы IPC, как правило, копируют данные отправляющего процесса в пространство ядра, а затем из ядра в пространство принимающего процесса, то есть копирование происходит дважды. Поэтому необходимо применять хотя бы один из вышеупомянутых методов, чтобы избежать лишних операций копирования.
Обнуляйте структуру sockaddr_in
| | |
Хотя обычно используется только три поля из структуры sockaddr_in: sin_family, sin_port и sin_addr, но, как правило, в ней есть и другие поля. Например, во многих реализациях есть поле sin_len, содержащее длину структуры. В частности, оно присутствует в системах, производных от версии 4.3BSD Reno и более поздних. Напротив, в спецификации Winsock этого поля нет.
Если сравнить структуры sockaddr_in в системе FreeBSD
struct sockaddr_in {
u_char sin_len;
u_char sin_family;
u_char sin_port;
struct in_addr sin_addr;
char sin_zero[8];
};
и в Windows
struct sockaddr_in {
short sin_family;
u_short sin_port;
struct in_addr sin_addr;
char sin_zero[8];
}
то видно, что в обеих структурах есть дополнительное поле sin_zero. Хотя это поле и не используется (оно нужно для того, чтобы длина структуры sockaddr_in была равна в точности 16 байт), но тем не менее должно быть заполнено нулями.
Примечание: Причина в том, что в некоторых реализациях во время привязки адреса к сокету производится двоичное сравнение этой адресной структуры с адресами каждого интерфейса.Такой код будет работать только в том случае, если поле sin_zero заполнено нулями.
Поскольку в любом случае необходимо обнулить поле sin_zero, обычно перед использованием адресной структуры ее полностью обнуляют. В этом случае заодно очищаются и все дополнительные поля, так что не будет проблем из-за недокументированных полей. Посмотрите на листинг 2.3 - сначала в функции set_address Делается вызов bzero для очистки структуры sockaddrjn.
| | |
Не забывайте о порядке байтов
| | |
В современных компьютерах целые числа хранятся по-разному, в зависимости от архитектуры. Рассмотрим 32-разрядное число 305419896 (0x12345678). Четыре байта этого числа могут храниться двумя способами: сначала два старших байта {такой порядок называется тупоконечным - big endian)
12 34 56 78
или сначала два младших байта (такой порядок называется остроконечным - little endian)
78 56 34 12
Примечание: Термины «тупоконечный» и «остроконечный» ввел Коэн [Cohen П1981], считавший, что споры о том, какой формат лучше, сродни распрям лилипутов из романа Свифта «Путешествия Гулливера», которые вели бесконечные войны, не сумев договориться, с какого конца следует разбивать яйцо — с тупого или острого. Раньше были в ходу и другие форматы, но практически во все современных машинах применяется либо тупоконечный, либо остроконечный порядок байтов.
Определить формат, применяемый в конкретной машине, можно с помощью следующей текстовой программы, показывающей, как хранится число 0х12345б78 (листинг 3.34).
Листинг 3.34. Программа для определения порядка байтов
endian.c
1 #include <stdio.h>
2 #include <sys/types.h>
3 #include "etcp.h"
4 int main( void )
5 {
6 u_int32_t x = 0x12345678; /* 305419896 */
7 unsigned char *xp = ( char * )&x;
9 printf( "%0x %0x %0x %0x\n",
10 xp[ 0 ], xp[ 1 ], xp[ 2 ], xp[ 3 ] );
11 exit( 0 );
12 }
Если запустить эту программу на компьютере с процессором Intel, то получится:
bsd: $ endian
78 56 34 12
bsd: $
Отсюда ясно видно, это - остроконечная архитектура.
Конкретный формат хранения иногда в шутку называют полом байтов. Он важен, поскольку остроконечные и тупоконечные машины (а равно те, что используют иной порядок) часто общаются друг с другом по протоколам TCP/IP- Поскольку такая информация, как адреса отправления и назначения, номера портов, длина датаграмм, размеры окон и т.д., представляется в виде целых чисел, необходимо, чтобы обе стороны интерпретировали их одинаково.
Чтобы обеспечить взаимодействие компьютеров с разными архитектурами» все целочисленные величины, относящиеся к протоколам, передаются в сетевом порядке байтов, который по определению является тупоконечным. По большей части, обо всем заботятся сами протоколы, но сетевые адреса, номера портов, а иногда и другие данные, представленные в заголовках, вы задаете сами. И всякий раз необходимо преобразовывать их в сетевой порядок.
Для этого служат две функции, занимающиеся преобразованием из машинного порядка байт в сетевой и обратно. Представленные ниже объявления этих функций заимствованы из стандарта POSIX. В некоторых версиях UNIX эти объявления находятся не в файле netinet/in.h. Типы uint32_t и uint16_t приняты в POSIX соответственно для без знаковых 32- и 16-разрядных целых. В некоторых реализациях эти типы могут отсутствовать. Тем не менее функции htonl и ntohl всегда принимают и возвращают беззнаковые 32-разрядные целые числа, будь то UNIX или Winsock. Точно так же функции htons и ntohs всегда принимают и возвращают беззнаковые 16-разрядные целые.
Примечание: Буквы «l» и «s» в конце имен функций означают long (длинное) и short (короткое). Это имело смысл, так как первоначально данные функции появились в системе 4.2BSD, разработанной для 32-разрядной машины, где длинное целое принимали равным 32 бит, а короткое - 16. С появлением 64-разрядных машин это уже не так важно, поэтому следует помнить, что 1-функции работают с 32-разрядными числами, которые не обязательно представлены как long, а s-функции - с 16разрядными числами, которые не обязательно представлены в виде short. Удобно считать, что 1-функции предназначены для преобразования длинных полей в заголовках протокола, а s-функции - коротких полей.
#include <netinet/in.h> /* UNIX */
#include <winsock2 .h> /* Winsock */
uint32_t htonl( uint32_t host32 );
uint16_t htons( uint16_t host16 );
Обе функции возвращают целое число в сетевом порядке.
uint32_t ntohl( uint32_t network32 ) ;
uint16_t ntohs( uint16_t network16 );
Обе функции возвращают целое число в машинном порядке.
Функции htonl и htons преобразуют целое число из машинного порядка байт в сетевой, тогда как функции ntohl и ntohs выполняют обратное преобразование. Заметим, что на «тупоконечных» машинах эти функции ничего не делают И обычно определяются в виде макросов:
#define htonl(x) (x)
На «остроконечных» машинах (и для иных архитектур) реализация функций зависит от системы. Не надо задумываться, на какой машине вы работаете, поскольку эти функции всегда делают то, что нужно.
Применение этих функций обязательно только для полей, используемых протоколами. Пользовательские данные для протоколов IP, UDP и TCP выглядят как множество неструктурированных байтов, так что неважно, записаны целые числа в сетевом или машинном порядке. Тем не менее функции ntoh* и hton* стоит применять при передаче любых данных, поскольку тем самым вы обеспечиваете возможность совместной работы машин с разной архитектурой. Даже если сначала предполагается, что приложение будет работать только на одной платформе обязательно настанет день, когда его придется переносить на другую платформу. Тогда дополнительные усилия окупятся с лихвой.
Примечание: В общем случае проблема преобразования данных между машинами с разными архитектурами сложна. Многие программисты решают ее, преобразуя все числа в код ASCII (или, возможно, в код EBCDIC для больших машин фирмы IBM). Другой подход связан с использованием компоненты XDR (External Data Representation -внешнее представление данных), входящей в состав подсистемы вызова удаленных процедур (RFC - remote procedure call), разработанной фирмой Sun. Компонента XDR определена в RFC 1832 [Srinivasan 1995] и представляет собой набор правил для кодирования данных различных типов, а также язык, описывающий способ кодирования. Хотя предполагалось, что XDR будет применяться как часть RPC, можно пользоваться этим механизмом в ваших программах. В книге [Stevens 1999] обсуждается XDR и его применение без RPC.
И, наконец, следует помнить, что функции разрешения имен, такие как gethostbyname и getservbyname (совет 29), возвращают значения, представленные в сетевом порядке. Поэтому следующий неправильный код
struct servant *sp;
struct sockaddr_in *sap;
sp = getservbyname( name, protocol );
sap->sin_port = htons( sp->s_port );
приведет к ошибке, если исполняется не на «тупоконечной» машине.
Не «зашивайте» IP-адреса и номера портов в код
| | |
У программы есть только два способа получить IP-адрес или номер порта:
из аргументов в командной строке или, если программа имеет графический интерфейс пользователя, с помощью диалогового окна либо аналогичного механизма;
с помощью функции разрешения имен, например gethostbyname или getservbyname.
Примечание: Строго говоря, getservbyname — это не функция разрешения имени (то есть она не входит в состав DNS-клиента, который отображает имена на IP-адреса и наоборот). Но она рассмотре на вместе с остальными, поскольку выполняет похожие действия.
Никогда не следует «зашивать» эти параметры в текст программы или помещать их в собственный (не системный) конфигурационный файл. И в UNIX, и в Windows есть стандартные способы получения этой информации, ими и надо пользоваться.
Теперь IP-адреса все чаще выделяются динамически с помощью протокола DHCP (dynamic host configuration protocol - протокол динамической конфигурации хоста). И это убедительная причина избегать их задания непосредственно в тексте программы. Некоторые считают, что из-за широкой распространенности DHCP и сложности адресов в протоколе IPv6 вообще не нужно передавать приложению числовые адреса, а следует ограничиться только символическими именами хостов, которые приложение должно преобразовать в IP-адреса, обратившись к функции gethostbyname или родственным ей. Даже если протокол DHCP не используется, управлять сетью будет намного проще, если не «зашивать» эту информацию в код и не помещать ее в нестандартные места. Например, если адрес сети изменяется, то все приложения с «зашитыми» адресами просто перестанут работать.
Всегда возникает искушение встроить адрес или номер порта непосредственно в текст программы, написанной «на скорую руку», и не возиться с функциями типа getXbyY. К сожалению, такие программы начинают жить своей жизнью, а иногда даже становятся коммерческими продуктами. Одно из преимуществ каркасов и библиотечных функций на их основе (совет 4) состоит в том, что код уже написан, так что нет необходимости «срезать углы».
Рассмотрим некоторые функции разрешения имен и порядок их применения. Вы уже не раз встречались с функцией gethostbyname:
#include <netdb.h> /* UNIX */
#include <winsock2.h> /* Winsock */
struct hostent *gethostbyname( const char *name );
Возвращаемое значение: указатель на структуру hostent в случае успеха, h_errno и код ошибки в переменной h_errno - в случае неудачи.
Функции gethostbyname передается имя хоста, а она возвращает указателя на структуру ho в tent следующего вида:
struct hostent {
char *h_name; /* Официальное имя хоста.*/
char **h_aliases; /* Список синонимов.*/
int h_addrtype; /* Тип адреса хоста.*/
int h_length; /* Длина адреса.*/
char **h_addr_list; /* Список адресов, полученных от DNS.*/
#define h_addr h_addr_list[0]; /* Первый адрес.*/
};
Поле h_name указывает на «официальное» имя хоста, а поле h_aliases — на список синонимов имени. Поле h_addrtype содержит либо AF_INET, либо AF_INET6 в зависимости от того, составлен ли адрес в соответствии с протоколом IPv4 или IPv6. Аналогично поле h_length равно 4 или 16 в зависимости от типа адреса. Все адреса типа h_addrtype возвращаются в списке, на который указывает поле h_addr_list. Макрос h_addr выступает в роли синонима первого (возможно, единственного) адреса в этом списке. Поскольку gethostbyname возвращает список адресов, приложение может попробовать каждый из них, пока не установит соединение с нужным хостом.
Работая с функцией gethostbyname нужно учитывать следующие моменты:
если хост поддерживает оба протокола IPv4 и IPv6, то возвращается только один тип адреса. В UNIX тип возвращаемого адреса зависит от параметра RES_USE_INET6 системы разрешения имен, который можно явно задать, обратившись к функции res_init или установив переменную среду, а также с помощью опции в конфигурационном файле DNS. В соответствии с Win-sock, всегда возвращается адрес IPv4;
структура hostent находится в статической памяти. Это означает, что функция gethostbyname не рентабельна;
указатели, хранящиеся в статической структуре hostent, направлены на другую статическую или динамически распределенную память, поэтому при желании скопировать структуру необходимо выполнять глубокое копирование. Это означает, что помимо памяти для самой структуры hostent необходимо выделить память для каждой области, на которую указывают поля структуры, а затем скопировать в нее данные;
как говорилось в совете 28, адреса, хранящиеся в списке, на который указывает поле h_addr_list, уже приведены к сетевому порядку байтов, так что применять к ним функцию htonl не надо.
Вы можете также выполнить обратную операцию - отобразить адреса хосто на их имена. Для этого служит функция gethostbyaddr.
#include <netdb.h> /* UNIX. */
#include <winsock2.h> /* Winsock. */
struct hostent *gethostbyaddr(const char *addr, int len, int type);
Возвращаемое значение: указатель на структуру hostent в случае успеха, NULL и код ошибки в переменной h_errno - в случае неудачи.
Несмотря на то, что параметр addr имеет тип char*, он указывает на структуру in_addr (или in6_addr в случае IPv6). Длина этой структуры задается параметром len, а ее тип (AF_INET или AF_INET6) - параметром type. Предыдущие замечания относительно функции gethostbyname касаются и gethostbyaddr.
Для хостов, поддерживающих протокол IPv6, функции gethostbyname недостаточно, так как нельзя задать тип возвращаемого адреса. Для поддержки IPv6 (и других адресных семейств) введена общая функция gethostbyname2, допускающая получение адресов указанного типа.
#include <netdb.h>/* UNIX */
struct hostent *gethostbyname2(const char *name, int af );
Возвращаемое значение: указатель на структуру hostent в случае успеха, NULL и код ошибки в переменной h_errno - в случае неудачи.
Параметр af - это адресное семейство. Интерес представляют только возможные значения AF_INET или AF_INET6. Спецификация Winsock не определяет функцию gethostbyname2, а использует вместо нее функционально более богатый (и сложный) интерфейс WSALookupServiceNext.
Примечание: Взаимодействие протоколов IPv4 и IPv6 - это в значительной мере вопрос обработки двух разных типов адресов. И функция gethostbyname2 предлагает один из способов решения этой проблемы. Эта тема подробно обсуждается в книге [Stevens 1998], где также приведена реализация описанной в стандарте POSIX функции getaddrinfo. Эта функция дает удобный, не зависящий от протокола способ работы с обоими типами адресов. Спомощъю getaddrinfo можно написать приложение, которое будет одинаково работать и с IPv4, и с IPv6.
Раз системе (или службе DNS) разрешено преобразовывать имена хостов в IP-адреса, почему бы ни сделать то же и для номеров портов? В совете 18 рассматривался один способ решения этой задачи, теперь остановимся на другом. Так же, как gethostbyname и gethostbyaddr выполняют преобразование имени хоста в адрес и обратно, функции getservbyname и getservbyport преобразуют символическое имя сервиса в номер порта и наоборот. Например, сервис времени дня daytime прослушивает порт 13 в ожидании TCP-соединений или UDP-дата-грамм. Можно обратиться к нему, например, с помощью программы telnet:
telnet bsd 13
Однако необходимо учитывать, что номер порта указанного сервиса равен 13. К счастью, telnet понимает и символические имена портов:
telnet bsd daytime
Telnet выполняет отображение символических имен на номера портов, вызывая функцию getservbyname; вы сделаете то же самое. В листинге 2.3 выувидите, что в предложенном каркасе этот вызов уже есть. Функция set_addres сначала оперирует параметром port как представленным в коде ASCII целым числом, то есть пытается преобразовать его в двоичную форму. Если это не получается, то вызывается функция getservbyname, которая ищет в базе данных символическое имя порта и возвращает соответствующее ему числовое значение.
Прототип функции getservbyname похож на gethostbyname:
#include <netdb.h> /* UNIX */
#include <winsock2.h> /* Winsock */
struct servant *getservbyname(const char *name, const char *proto );
Возвращаемое значение: указатель на структуру servent в случае успеха, NULL - в случае неудачи.
Параметр name - это символическое имя сервиса, например «daytime». Если параметр pro to не равен NULL, то возвращается сервис, соответствующий заданным имени и типу протокола, в противном случае - первый найденный сервис с именем name. Структура servent содержит информацию о найденном сервисе:
struct servent {
char *s_name; /*Официальное имя сервиса. */
char **s_aliases; /*Список синонимов. */
int s_port; /*Номер порта. */
char *s_proto; /*Используемый протокол. */
};
Поля s_name и s_aliases содержат указатели на официальное имя сервиса и его синонимы. Номер порта сервиса находится в поле s_port. Как обычно, этот номер уже представлен в сетевом порядке байтов. Протокол (TCP или UDP), иcпользуемый сервисом, описывается строкой в поле s_proto.
Вы можете также выполнить обратную операцию - найти имя сервиса по номеру порта. Для этого служит функция getservbyport:
#include <netdb.h> /* UNIX. */
#include <winsock2.h> /* Winsock. */
struct servent *getservbyport( int port, const char *proto);
Возвращаемое значение: указатель на структуру servent в случае успеха, NULL - в случае неудачи
Передаваемый в параметре port номер порта должен быть записан в сетевом порядке. Параметр pro to имеет тот же смысл, что и раньше.
С точки зрения программиста, данный каркас и библиотечные функции решают задачи преобразования имен хостов и сервисов. Они сами вызывают нужные функции, а как это делается, не должно вас волновать. Однако нужно знать, как ввести в систему необходимую информацию.
Обычно это делается с помощью одного из трех способов:
DNS;
сетевой информационной системы (NIS) или NIS+;
файлов hosts и services.
DNS (Domain Name System - служба доменных имен) - это распределенная база данных для преобразования имен хостов в адреса.
Примечание: DNS используется также для маршрутизации электронной почты. Когда посылается письмо на адрес jsmithesomecompany. com, с помощью DNS ищется обработчик (или обработчики) почтыдля компании somecompany.com. Подробнее это объясняетсяв книге [Albitz and Lin 1998].
Ответственность за хранение данных распределяется между зонами (грубо говоря, они соответствуют адресным доменам) и подзонами. Например, bigcompany.com может представлять собой одну зону, разбитую на несколько подзон, соответствующих отделам или региональным отделениям. В каждой зоне и подзоне работает один или несколько DNS-серверов, на которых хранится вся информация о хостах в этой зоне или подзоне. Другие DNS-серверы могут запросить информацию у данных серверов для разрешения имен хостов, принадлежащих компании BigCompany.
Примечание: СистемаDNS -этохороший пример UDP-приложения. Как правило, обмен с DNS-сервером происходит короткими транзакциями. Клиент (обычно одна из функций разрешения имен) посылает UDP-датаграмму, содержащую запрос к DNS-cepeepy.Если в течение некоторого времени ответ не получен, то пробуется другой сервер, если таковой известен. В противном случае повторно посылается запрос первому серверу, но с увеличенным тайм-аутом.
На сегодняшний день подавляющее большинство преобразований между именами хостов и IP-адресами производится с помощью службы DNS. Даже сети, не имеющие выхода вовне, часто пользуются DNS, так как это упрощает администрирование. При добавлении в сеть нового хоста или изменении адреса существующего нужно обновить только базу данных DNS, а не файлы hosts на каждой машине.
Система NIS и последовавшая за ней NIS+ предназначены для ведения централизованной базы данных о различных аспектах системы. Помимо имен хостов и IP-адресов, NIS может управлять именами сервисов, паролями, группами и другими данными, которые следует распространять по всей сети. Стандартные функции разрешения имен (о них говорилось выше) могут опрашивать и базы данных NIS. В некоторых системах NIS-сервер при получении запроса на разрешение имени хоста, о котором у него нет информации, автоматически посылает запрос DNS-серверу В других системах этим занимается функция разрешения имен.
Преимущество системы NIS в том, что она централизует хранение всех распространяемых по сети данных, упрощая тем самым администрирование больших сетей. Некоторые эксперты не рекомендуют NIS, так как имеется потенциальная угроза компрометации паролей. В системе NIS+ эта угроза снята, но все равно многие опасаются пользоваться ей. NIS обсуждается в работе [Brown 1994].
Последнее и самое неудобное из стандартных мест размещения информации об именах и IP-адресах хостов - это файл hosts, обычно находящийся в каталоге /etc на каждой машине. В этом файле хранятся имена, синонимы и IP-адреса хостов в сети. Стандартные функции разрешения имен просматривают также и этот файл. Обычно при конфигурации системы можно указать, когда следует просматривать файл hosts - до или после обращения к службе DNS.
Другой файл - обычно /etc/services - содержит информацию о соответствии имен и портов сервисов. Если NIS не используется, то, как правило, на каждой машине имеется собственная копия этого файла. Поскольку он изменяется редко, с его администрированием не возникает таких проблем, как с файлом hosts. В совете 17 было сказано о формате файла services.
Основной недостаток файла hosts - это очевидное неудобство его сопровождения. Если в сети более десятка хостов, то проблема быстро становится почти неразрешимой. В результате многие эксперты рекомендуют полностью отказаться от такого метода. Например, в книге [Lehey 1996] советуется следующее: «Есть только одна причина не пользоваться службой DNS - если ваш компьютер не подсоединен к сети».
Разберитесь, что такое подсоединенный UDP-сокет
| | |
Здесь рассказывается об использовании вызова connect применительно к протоколу UDP. Из совета 1 вам известно, что UDP - это протокол, не требующий установления соединений. Он передает отдельные адресованные конкретному получателю датаграммы, поэтому кажется, что слово «connect» (соединить) тут неуместно. Следует, однако, напомнить, что в листинге 3.6 вы уже встречались с примером, где вызов connect использовался в запускаемом через inetd UDP-сервере, чтобы получить (эфемерный) порт для этого сервера. Только так inetd мог продолжать прослушивать датаграммы, поступающие в исходный хорошо известный порт.
Прежде чем обсуждать, зачем нужен вызов connect для UDP-сокета, вы должны четко представлять себе, что собственно означает «соединение» в этом контексте. При использовании TCP вызов connect инициирует обмен информацией о состоянии между сторонами с помощью процедуры трехстороннего квитирования (рис. 3.14). Частью информации о состоянии является адрес и порт каждой стороны, поэтому можно считать, что одна из функций вызова connect в протоколе TCP - это привязка адреса и порта удаленного хоста к локальному сокету.
Хотя полезность вызова connect в протоколе UDP может показаться сомнительной, но вы увидите, что, помимо некоторого повышения производительности, он позволяет выполнить такие действия, которые без него были бы невозможны. Рассмотрим причины использования соединенного сокета UDP сначала с точки зрения отправителя, а потом - получателя.
Прежде всего, от подсоединенного UDP-сокета вы получаете возможность ис-Щользования вызова send или write (в UNIX) вместо sendto.
Примечание: Для подсоединенного UDP-сокета можно использовать и вызов sendto, но в качестве указателя на адрес получателя надо задавать NULB, а в качестве его длины - нуль. Возможен, конечно, и вызов sendmsg, но и в этом случае поле msg_name в структуре msghdr должно содержать NULL, а поле msg_namel en - нуль.
Само по себе это, конечно, немного, но все же вызов connect действительно дает заметный выигрыш в производительности.
В реализации BSD sendto - это частный случай connect. Когда датаграмма посылается с помощью sendto, ядро временно соединяет сокет, отправляет датаграмму, после чего отсоединяет сокет. Изучая систему 4.3BSD и тесно связанную с ней SunOS 4.1.1, Партридж и Пинк [Partridge and Pink 1993] заметили, что такой способ соединения и разъединения занимает почти треть времени, уходящего на передачу датаграммы. Если не считать усовершенствования кода, который служит для поиска, управляющего блока протокола (РСВ - protocol control block) и ассоциирован с сокетом, исследованный этими авторами код почти без изменений вошел в систему 4.4BSD и основанные на ней, например FreeBSD. В частности, эти стеки по-прежнему выполняют временное соединение и разъединение. Таким образом, если вы собираетесь посылать последовательность UDP-дата-грамм одному и тому же серверу, то эффективность можно повысить, предварительно вызвав connect.
Этот выигрыш в производительности характерен только для некоторых реализаций. А основная причина, по которой отправитель UDP-датаграмм подсоединяет сокет, - это желание получать уведомления об асинхронных событиях. Представим, что надо послать UDP-датаграмму, но никакой процесс на другой стороне не прослушивает порт назначения. Протокол UDP на другом конце вернет ICMP-сообщение о недоступности порта, информируя тем самым ваш стек TCP/IP, но если сокет не подсоединен, то приложение не получит уведомления. Когда вы вызываете sendto, в начало сообщения добавляется заголовок, после чего оно передается уровню IP, где инкапсулируется в IP-датаграмму и помещается в выходную очередь интерфейса. Как только датаграмма внесена в очередь (или отослана, если очередь пуста), sendto возвращает управление приложению с кодом нормального завершения. Иногда через некоторое время (отсюда и термин асинхронный) приходит ICMP-сообщение от хоста на другом конце. Хотя в нем есть копия UDP-заголовка, у вашего стека нет информации о том, какое приложение посылало датаграмму (вспомните совет 1, где говорилось, что из-за отсутствия установленного соединения система сразу забывает об отправленных датаграммах). Если же сокет подсоединен, то этот факт отмечается в управляющем блоке протокола, связанном с сокетом, и стек TCP/IP может сопоставить полученную копию UDP-заголовка с тем, что хранится в РСВ, чтобы определить, в какой сокет направить ICMP-сообщение.
Можно проиллюстрировать данную ситуацию с помощью вашей программы udpclient (листинг 3.5) из совета 17 - следует отправить датаграмму в порт, который не прослушивает ни один процесс:
bsd: $ udpclient bed 9000
Hello, World!
^C Клиент "зависает" и прерывается вручную.
bsd: $
Теперь модифицируем клиент, добавив такие строки
if ( connect! s, ( struct sockaddr * )&peer, sizeof( peer ) ) ) error( 1, errno, "ошибка вызова connect" );
сразу после вызова функции udp_client. Если назвать эту программу udpcona и запустить ее, то вы получите следующее:
bsd: $ udpconnl bed 9000
Hello, World!
updconnl: ошибка вызова sendto: Socket is already connected (56)
bsd: $
Ошибка произошла из-за того, что вы вызвали sendto для подсоединенного сокета. При этом sendto потребовал от UDP временно подсоединить сокет. Но UDP определил, что сокет уже подсоединен и вернул код ошибки EISCONN.
Чтобы исправить ошибку, нужно заменить обращение к sendto на
rс = send( s, buf, strlen( buf ), 0 );
Назовем новую программу udpconn2. После ее запуска получится такой результат:
bsd: $ udpconnl bed 9000
Hello, World!
updconn2: ошибка вызова recvfrom: Connection refused (61)
bsd: $
На этот раз ошибку ECONNREFUSED вернул вызов recvfrom. Эта ошибка - результат получения приложением ICMP-сообщения о недоступности порта.
Обычно у получателя нет причин соединяться с отправителем (если, конечно, ему самому не нужно стать отправителем). Однако иногда такая ситуация может быть полезна. Вспомним аналогию с телефонным разговором и почтой (совет 1) TCP-соединение похоже на частный телефонный разговор - в нем только два участника. Поскольку в протоколе TCP устанавливается соединение, каждая сторона знает о своем партнере и может быть уверена, что всякий полученный байт действительно послал партнер.
С другой стороны, приложение, получающее UDP-датаграммы, можно сравнить с почтовым ящиком. Как любой человек может отправить письмо по данному адресу, так и любое приложение или хост может послать приложению-получателю датаграмму, если известны адрес и номер порта.
Иногда нужно получать датаграммы только от одного приложения. Получающее приложение добивается этого, соединившись со своим партнером. Чтобы увидеть, как это работает, напишем UDP-сервер эхо-контроля, который соединяется с первым клиентом, отправившим датаграмму (листинг 3.35).
Листинг 3.35. UDP-сервер эхо-контроля, выполняющий соединение
1 #include "etcp.h" :
2 int main( int argc, char **argv )
3 {
4 struct sockaddr_in peer;
5 SOCKET s;
6 int rс;
7 int len;
8 char buf[ 120 ];
9 INIT();
10 s = udp_server( NULL, argv[ 1 ] ) ;
11 len = sizeof( peer );
12 rс = recvfrom( s, buf, sizeoff buf ),
13 0, ( struct sockaddr * )&peer, &len );
14 if ( rс < 0 )
15 error( 1, errno, "ошибка вызова recvfrom" );
16 if ( connect( s, ( struct sockaddr * )&peer, len ) )
17 error( 1, errno, "ошибка вызова connect" );
18 while ( strncmp( buf, "done", 4 ) != 0 )
19 {
20 if ( send( s, buf, rс, 0 ) < 0 )
21 error( 1, errno, "ошибка вызова send" );
22 rc = recv( s, buf, sizeof( buf ), 0 );
23 if ( rс < 0 )
24 error( 1, errno, "ошибка вызова recv" );
25 }
26 EXIT( 0 );
27 }
9-15 Выполняем стандартную инициализацию UDP и получаем первую датаграмму, сохраняя при этом адрес и порт отправителя в переменной peer.
16-17 Соединяемся с отправителем.
18-25 В цикле отсылаем копии полученных датаграмм, пока не придет датаграмма, содержащая единственное слово «done».
Для экспериментов с сервером udpconnserv можно воспользоваться клиентом udpconn2. Сначала запускается сервер для прослушивания порта 9000 в ожидании датаграмм:
udpconnserv 9000
а затем запускаются две копии udpconn2, каждая в своем окне.
|
bsd: $ udpconn2 bsd 9000 one one three three done ^C bsd: $ |
bsd: $ udpconn2 bsd 9000 two udpconn2: ошибка вызова recvfroin: Connection refused (61) bsd: $ |
Когда в первом окне вы набираете one, сервер udpconnserv возвращает копию датаграммы. Затем во втором окне вводите two, но recvf rom возвращает код ошибки ECONNREFUSED. Это происходит потому, что UDP вернул ICMP-сообщение о недоступности порта, так как ваш сервер уже соединился с первым экземпляром udpconn2 и не принимает датаграммы с других адресов.
Примечание: Адреса отправителя у обоих экземпляров udpconn2, конечно, одинаковы, но эфемерные порты, выбранные стеком TCP/IP, различны. В первом окне вы набираете three, дабы убедиться, что udpconnserv все еще функционирует, а затем — done, чтобы остановить сервер. В конце прерываем вручную первый экземпляр udpconn2.
Как видите, udpconnserv не только отказывается принимать датаграммы от другого отправителя, но также информирует приложение об этом факте, посылая ICMP-сообщение. Разумеется, чтобы получить это сообщение, клиент также должен подсоединиться к серверу. Если бы вы прогнали этот тест с помощью первоначальной версии клиента udpclient вместо udpconn2, то второй экземпляр клента просто «завис» после ввода слова «done».
Помните, что С - не единственный язык программирования
| | |
До сих пор все примеры в этой книге были написаны на языке С, но, конечно, это не единственно возможный выбор. Многие предпочитают писать на C++, Java или даже Pascal. В этом разделе будет рассказано об использовании языков сценарИ" ев для сетевого программирования и приведено несколько примеров на языке Perl Вы уже встречались с несколькими примерами небольших программ, написанных специально для тестирования более сложных приложений. Например, в совете 30 использованы простые и похожие программы udpclient, udpconnl и udpconn2 для проверки поведения подсоединенного UDP-сокета. В таких случаях имеет смысл воспользоваться каким-либо языком сценариев. Сценарии проще разрабатывать и модифицировать хотя бы потому, что их не надо компилировать и компоновать со специальной библиотекой, а также создавать файлы сборки проекта (Makefile)— достаточно написать сценарий и сразу же запустить его.
В листинге 3.36 приведен текст минимального Perl-сценария, реализующего функциональность программы udpclient.
Хотя я не собираюсь писать руководство по языку Perl, но этот пример стоит изучить подробнее.
Примечание: Глава 6 стандартного учебника по Perl [Wall et al. 1996] посвящена имеющимся в этом языке средствам межпроцессного взаимодействия и сетевого программирования. Дополнительную информацию о языке Perl можно найти на сайте http://www.perl.com.
Листинг 3.36. Версия программы udpclient на языке Perl
1 #! /usr/bin/perl5
2 use Socket;
3 $host = shift "localhost";
4 $port = shift "echo";
5 $port = getservbyname( $port, "udp" ) if $port =~ /\D/;
6 $peer = sockaddr_in( $port, inet_aton( $host ) );
7 socket(S,PF_INET,SOCK_DGRAM,0) die "ошибка вызова socket $!";
8 while ( $line = <STDIN> )
9 {
10 defined) send(S,$line,0,$peer)) die "ошибка вызова send $!";
11 defined) recv(S, $line, 120, 0)) die "ошибка вызова recv $!";
12 print $line;
13 }
Инициализация
2 В этой строке Perl делает доступными сценарию определения некоторых констант (например, PF_INET).
Получение параметров командной строки
3-4 Из командной строки читаем имя хоста и номер порта. Обратите внимание, что этот сценарий делает больше, чем программа на языке С, так как по умолчанию он присваивает хосту имя localhost, а порту -echo, если один или оба параметра не заданы явно.
Заполнение структуры sockaddr_in и получение сокета
5-6 Этот код выполняет те же действия, что и функция set_address в листинге 2.3 в совете 4. Обратите внимание на простоту кода. В этих двух строчках IP-адрес хоста принимается как числовой и его имя символическое, а равно числовое или символическое имя сервиса.
7 Получаем UDP-сокет.
Определите, на что влияют размеры буферов
| | |
Здесь приводятся некоторые эвристические правила для задания размеров буферов приема и передачи в TCP. В совете 7 обсуждалось, как задавать эти размеры с помощью функции setsockopt. Теперь вы узнаете, какие значения следует устанавливать.
Необходимо сразу отметить, что выбор правильного размера буфера зависит от приложения. Для интерактивных приложений типа telnet желательно устанавливать небольшой буфер. Этому есть две причины:
обычно клиент посылает небольшой блок данных серверу и ждет ответа. Поэтому выделять большой буфер для таких соединений - пустая трата системных ресурсов;
при большом буфере реакция на действия пользователя происходит не сразу. Например, если пользователь выводит на экран большой файл и нажимает комбинацию клавиш прерывания (Ctrl+C), то вывод не прекратится, пока в буферах есть данные. Если буфер велик, то до реального прерывания просмотра может пройти заметное время.
Знать размер буфера необходимо для расчета максимальной производительности. Например, это относится к приложениям, которые передают большие объемы данных преимущественно в одном направлении. Далее будут рассматриваться именно такие приложения.
Как правило, для получения максимальной пропускной способности рекомендуется, чтобы размеры буферов приема и передачи были не меньше произведения полосы пропускания на задержку. Как вы увидите, это правильный, но не слишком полезный совет. Прежде чем объяснять причины, разберемся, что представляет собой это произведение и почему размер буферов «правильный».
Вы уже несколько раз встречались с периодом кругового обращения (RTT). Это время, которое требуется пакету на «путешествие» от одного хоста на другой и обратно. Оно и представляет собой множитель «задержки», поскольку определяет время между моментом отправки пакета и подтверждением его получателем. Обычно RTT измеряется в миллисекундах.
Другой множитель в произведении - полоса пропускания (bandwidth). Это количество данных, которое можно передать в единицу времени по данному физическому носителю.
Примечание: Технически это не совсем корректно, но этот термин уже давно используется.
Полоса пропускания измеряется в битах в секунду. Например, для сети Ethernet полоса пропускания (чистая) равна 10 Мбит/с.
Произведение полосы пропускания на задержку BWD вычисляется по формуле:
BWD = bandwidth X RTT.
Если RTT выражается в секундах, то единица измерения BWD будет следующей:
бит
BWD = --------- X секунда = бит.
секунда
Если представить коммуникационный канал как «трубу», то произведение полосы пропускания на задержку - это объем трубы в битах (рис. 3.15), то есть количество данных, которые могут находиться в сети в любой момент времени

Рис. 3.15. Труба емкостью BWD бит
А теперь представим, как выглядит эта труба в установившемся режиме (после завершения алгоритма медленного старта) при массовой передаче данных, занимающей всю доступную полосу пропускания. Отправитель слева на рис. 3.16 заполнил трубу TCP-сегментами и должен ждать, пока сегмент п покинет сеть. Только после этого он сможет послать следующий сегмент. Поскольку в трубе находится столько же сегментов АСК, сколько и сегментов данных, при получении подтверждения на сегмент п - 8 отправитель может заключить, что сегмент п покинул сеть.
Это иллюстрирует феномен самосинхронизации (self-clocking property) TCP-соединения в установившемся режиме [Jacobson 1988]. Полученный сегмент АСК служит сигналом для отправки следующего сегмента данных.

Рис. 3.16. Сеть в установившемся режиме
Примечание: Этот механизм часто называют АСК-таймером (АСК clock).
Если необходимо, чтобы механизм самосинхронизации работал и поддерживал трубу постоянно заполненной, то окно передачи должно быть достаточно велико для обеспечения 16 неподтвержденных сегментов (от п - 8 до п + 7). Это означает, что буфер передачи на вашей стороне и буфер приема на стороне получателя Должны иметь соответствующий размер для хранения 16 сегментов. В общем случае необходимо, чтобы в буфере помещалось столько сегментов, сколько находится в заполненной трубе. Значит, размер буфера должен быть не меньше произведения полосы пропускания на задержку.
Выше было отмечено, что это правило не особенно полезно. Причина в том, что обычно трудно узнать величину этого произведения. Предположим, что вы пишете приложение типа FTP. Насколько велики должны быть буферы приема и передачи? Во время написания программы неясно, какая сеть будет использоваться, а поэтому Неизвестна и ее полоса пропускания. Но даже если это можно узнать во время выполнения, опросив сетевой интерфейс, то остается еще неизвестной величина задержки. ° Принципе, ее можно оценить с помощью какого-нибудь механизма типа ping, но, скорее всего, задержка будет варьироваться в течение существования соединения.
Примечание: Одно из возможных решений этой проблемы предложено в п боте [Semke et al.]. Оно состоит в динамическом изменении па. меров буферов. Авторы замечают, что размер окна перегризк можно рассматривать как оценку произведения полосы пропиг кания на задержку. Подбирая размеры буферов в соответствии с текущим размером окна перегрузки (конечно, применяя подходящее демпфирование и ограничения, обеспечивающие справедливый режим для всех приложений), они сумели получить очень высокую производительность на одновременно установленных соединениях с разными величинами BWD. К сожалению, такоерешение требует изменения в ядре операционной системы, так что прикладному программисту оно недоступно.
Как правило, размер буферов назначают по величине, заданной по умолчанию или большей. Однако ни то, ни другое решение не оптимально. В первом случае может резко снизиться пропускная способность, во втором, как сказано в работе [Semke et al. 1998], - исчерпаны буферы, что приведет к сбою операционной системы.
В отсутствии априорных знаний о среде, в которой будет работать приложение, наверное, лучше всего использовать маленькие буферы для интерактивных приложений и буферы размером 32-64 Кб - для приложений, выполняющих массовую передачу данных. Однако не забывайте, что при работе в высокоскоростных сетях следует задавать намного больший размер буфера, чтобы использовать всю доступную полосу пропускания. В работе [Mahdavi 1997] приводятся некоторые рекомендации по оптимизации настройки стеков TCP/IP.
Есть одно правило, которое легко применять на практике, позволяющее повысить общую производительность во многих реализациях. В работе [Comer and Lin 1995] описывается эксперимент, в ходе которого два хоста были соединены сетью Ethernet в 10 Мбит и сетью ATM в 100 Мбит. Когда использовался размер буфера 16 Кб, в одном и том же сеансе FTP была достигнута производительность 1,313 Мбит/с для Ethernet и только 0,322 Мбит/с для ATM.
В ходе дальнейших исследований авторы обнаружили, что размер буфера, величина MTU (максимальный размер передаваемого блока), максимальный размер сегмента TCP (MSS) и способ передачи данных уровню TCP от слоя сокетов влияли на взаимодействие алгоритма Нейгла и алгоритма отложенного подтверждения (совет 24).
Примечете: MTU (максимальный блок передачи) - это максимальный размер фрейма, который может быть передан по физической сети. Для Ethernet эта величина составляет 1500 байт. Для сети АТМ описанной в работе [Comer and Lin 1995], - 9188 байт.
Хотя эти результаты были получены для локальной сети ATM и конкретно реализации TCP (SunOS 4.1.1), они применимы и к другим сетям и реализациям. Самые важные параметры: величина MTU и способ обмена между сокетами TCP, который в большинстве реализаций, производных от TCP, один и тот же.
Авторы нашли весьма элегантное решение проблемы. Его привлекательность в том, что изменять надо только размер буфера передачи, а размер буфера приема не играет роли. Описанное в работе [Comer and Lin 1995] взаимодействие не имеет места, если размер буфера передачи, по крайней мере, в три раза больше, чем MSS.
Примечание: Смысл этого решения в том, что получателя вынуждают послать информацию об обновлении окна, а, значит, иАСК, предотвращая тем самым откладывание подтверждения и нежелательную интерференцию с алгоритмом Нейгла. Причины обновления информации о размере окна, различны для случаев, когда буфер приема меньше или больше утроенного MSS, но в любом случае обновление посылается.
Поэтому неинтерактивные приложения всегда должны устанавливать буфер приема не менее чем 3 X MSS. Вспомните совет 7, где сказано, что это следует делать до вызова listen или connect.
Используйте утилиту ping
| | |
Один из самых главных и полезных инструментов отладки сетей и работающих в них приложений - это утилита ping. Ее основное назначение - проверить наличие связи между двумя хостами.
Прежде необходимо разъяснить несколько моментов, касающихся ping. Во-первых, по словам Майка Муусса, слово «ping» не расшифровывается как «packet internet groper» (проводящий межсетевые пакеты). Своим названием эта программа обязана звуку, который издает сонар, устанавливаемый на подводных лодках. История создания программы ping изложена в статье «The Story of the Ping Program» Муусса на Web-странице http://ftp.arl.mil/-mike/ping/html. Там же приведен и ее исходный текст.
Во-вторых, эта утилита не использует ни TCP, ни UDP, поэтому для нее нет никакого хорошо известного порта. Для проверки наличия связи ping пользуется функцией эхо-контроля, имеющейся в протоколе ICMP. Помните (совет 14), что, хотя сообщения ICMP передаются в IP-датаграммах, ICMP считается не отдельным протоколом, а частью IP.
Примечание: В RFC 792 [Postel 1981] на первой странице сказано: «1СМР использует базовую поддержку IP, как если бы это был протокол более высокого уровня, однако в действительности ICMP является неотъемлемой частью IP и должен быть реализован в каждом IP-модуле».
Таким образом, структура пакета, посылаемого ping, имеет такой вид, как на рис. 4.1. Показанная на рис. 4.2 ICMP-часть сообщения состоит из восьмибайтного ICMP-заголовка и n байт дополнительной информации.
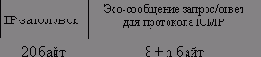
Рис. 4.1. Формат пакета ping
Обычно в качестве значения n- числа дополнительных байтов в пакете ping выбирается 56 (UNIX) или 32 (Windows), но эту величину можно изменить с помощью флагов -s (UNIX) или -l (Windows).
В некоторых версиях ping пользователь может задавать значения дополнительных данных или даже указывать, что они должны генерироваться псевдослучайным образом. По умолчанию в большинстве версий дополнительные данные циклически переставляемый по кругу набор байтов.
Примечание: Задание конкретных данных бывает полезно при отладке ошибок, зависящих от данных.
UNIX - версия ping помещает временной штамп (структуру timeval) в первые восемь байт дополнительных данных (при условии, конечно, что пользователь не задал меньшее количество). Когда программа ping получает эхо-ответ, она использует этот временной штамп для вычисления периода кругового обращения (RTT). Windows-версия ping этого не делает (вывод основан на анализе информации, полученной с помощью программы tcpdump), но в тексте примера ping, поставляемого в составе компилятора Visual C++, этот алгоритм присутствует.

Рис. 4.2. Пакет эхо – сообщения запрос/ответ протокола ICMP
Поскольку поля идентификатор и порядковый номер не задействованы ни в эхо-запросе, ни в эхо-ответе, ping использует их для идентификации полученных ICMP-ответов. Так как для IP-датаграмм нет специального порта, они доставляются каждому процессу, который открыл простой (raw) сокет с указанием протокола ICMP (совет 40). Поэтому ping помещает свой идентификатор процесса в поле идентификатор, так что каждый запущенный экземпляр способен отличить ответы на свои запросы. Таким образом, поле идентификатор в этом случае можно представить как аналог номера порта.
Таким же образом ping помещает в поле порядковый номер значение счетчика для того, чтобы связать ответ с запросом. Именно это значение ping показывает как icmp_seq.
Обычно первое ваше действие при пропадании связи с удаленным хостом - это запуск ping с указанием адреса этого хоста (хост «пингуется»). Предположим, что нужно связаться с хостом А с помощью программы telnet, но соединение не устанавливается из-за истечения тайм-аута. Причин может быть несколько: проблема в сети между двумя хостами, не работает сам хост А, проблема в удаленном стеке TCP/IP или не запущен сервер telnet.
Сначала следует проверить, «пингуя» хост А, что он достижим. Если работа ping Проходит нормально, то можно сказать, что с сетью все в порядке, а проблема, вероятно, связана с самим хостом А. Если же невозможно «достучаться» до хоста А с помощью ping, то требуется «пропинговать» ближайший маршрутизатор, чтобы понять, удается ли достичь хотя бы границы собственной сети. Если это получается, то воспользуйтесь программой traceroute (совет 35), чтобы выяснить, насколько далеко можно продвинуться по маршруту от вашего хоста к хосту А. Часто это помогает идентифицировать сбойный маршрутизатор или хотя бы сделать предположение о месте возникновения ошибки.
Поскольку ping работает на уровне протокола IP, она не зависит от правильности конфигурации TCP или UDP. Поэтому иногда полезно «пропинговать» свой собственный хост, чтобы проверить правильность установки сетевого программного обеспечения. Сначала можно указать ping возвратный адрес localhost (127.0.0.1), чтобы убедиться в работе хотя бы части сетевой поддержки. Если при этом проблем не возникает, то следует «пропинговать» один или несколько сетевых интерфейсов и удостовериться, что они правильно сконфигурированы.
Попробуйте «пропинговать» хост netcom4.netcom.com, который находится от вас в десяти переходах (рис. 4.3).
bsd: $ ping netcom4.netcom.com
PING netcom4.netcom.com (199.183.9.104): 56 data bytes
64 bytes from 199.183.9.104: icmp_seq=0 tt1=245 time=598.554 ms
64 bytes from 199.183.9.104: icmp_seq=1 tt1=245 time=550.081 ms
64 bytes from 199.183.9.104: icmp_seq=2 tt1=245 time=590.079 ms
64 bytes from 199.183.9.104: icmp_seq=3 tt1=245 time=530.114 ms
64 bytes from 199.183.9.104: icmp_seq=5 tt1=245 time=480.137 ms
64 bytes from 199.183.9.104: icmp_seq=6 tt1=245 time=540.081 ms
64 bytes from 199.183.9.104: icmp_seq=7 tt1=245 time=580.084 ms
64 bytes from 199.183.9.104: icmp_seq=8 tt1=245 time=490.078 ms
64 bytes from 199.183.9.104: icmp_seq=9 tt1=245 time=560.090 ms
64 bytes from 199.183.9.104: icmp_seq=10 tt1=245 time=490.090 ms
^C завершили ping вручную
- - - netcom4.netcom.com ping statistics - - -
12 packets transmitted, 10 packets received, 16% packet loss
round-trip min/avg/max/stddev = 480.137/540.939/598.554/40.871 ms
bsd: $
Рис. 4.З. Короткий прогон ping
Прежде всего, RTT для разных пакетов мало меняется и остается в пределах 500 мс. Как следует из последней строки, RTT модифицируется в диапазоне от 480,137 мс до 598,554 мс со стандартным отклонением 40,871 мс. Тест слишком рано прерван, чтобы можно было сделать какие-то выводы, но и при более длительном прогоне (около 2 мин) результат существенно не изменится. Так что можно предположить, что нагрузка на сеть постоянная. Значительный разброс RTT это, как правило, признак изменяющейся загрузки сети. При повышенной загрузке возрастает длина очереди в маршрутизаторе, а вместе с ней - и RTT. При уменьшении загрузки очередь сокращается, что приводит к уменьшению RTT.
Далее из рис. 4.3 видно, что на эхо-запрос ICMP с порядковым номером 4 не пришел ответ. Это означает, что запрос либо ответ был потерян одним из промежуточных маршрутизаторов. По данным сводной статистики, было послано 12 запросов (0-11) и получено лишь, 10 ответов. Один из пропавших ответов имеет порядковый номер 4, второй - 11 (вероятно, он был засчитан как пропавший, поскольку не вовремя прервана работа ping).
Используйте программу tcpdump или аналогичное средство
| | |
Из всех имеющихся в нашем распоряжении мощных и полезных средств отладки сетевых приложений и поиска неисправностей в сети наиболее интересны сетевые анализаторы (их еще называют сниферами). Традиционно сетевой анализатор - дорогое специализированное устройство, но современные рабочие станции вполне способны выполнять их функции в рамках отдельного процесса.
Сегодня сниферы есть для большинства сетевых операционных систем. Иногда в операционную систему входит снифер, предлагаемый поставщиком (программа snoop в Solaris или программы iptrace/ipreport в AIX), а иногда пользуются программами третьих фирм, например tcpdump.
Из инструментов, предназначенных только для диагностики, сниферы постепенно превратились в средства для исследований и обучения. Например, они постоянно используются для изучения динамики и взаимодействий в сетях. В книгах [Stevens 1994, Stevens 1996] рассказано, как использовать tcpdump, чтобы разобраться в работе сетевых протоколов. Наблюдая за данными, которые посылает протокол, вы можете глубже понять его функционирование на практике, а заодно увидеть, когда некоторая конкретная реализация работает не в соответствии со спецификацией.
В этом разделе будет рассмотрена утилита tcpdump. Как уже отмечалось, есть и другие программно реализованные сетевые анализаторы. Некоторые из них лучше форматируют выходные данные, но у tcpdump есть одно неоспоримое преимущество - она работает практически во всех UNIX-системах и в Windows. Поскольку исходные тексты tcpdump опубликованы, ее можно при необходимости адаптировать для специальных целей или перенести на новую платформу.
Код tcpdump вы можете найти на сайте http://www-nrg.ee.lbl.gov/nrg.html, а исходные тексты и исполняемый код для Windows WinDump- http://netgroup-serv.polito.it/windump.
Применяйте программу traceroute
| | |
Утилита traceroute - это важный инструмент для нахождения ошибок маршрутизации, изучения трафика в Internet и исследования топологии сети. Как и многие другие распространенные сетевые инструменты, traceroute была разработана коллективом лаборатории Лоренса Беркли в Университете Калифорнии.
Примечание: В комментариях к исходному тексту Ван Джекобсон, автор программы traceroute, пишет: «Я пытался найти ошибку в работе алгоритма маршрутизации в течение 48 бессонных часов, и этот код родился как-то сам собой».
Идея traceroute проста. Программа пытается определить маршрут между двумя хостами в сети, заставляя каждый промежуточный маршрутизатор посылать ICMP-сообщение об ошибке хосту-отправителю. Далее об этом механизме будет сказано подробнее. Сначала нужно несколько раз запустить программу и посмотреть, что она выдает. Проследим маршрут между хостом bsd и компьютером в Университете города Тампа на юге Флориды (рис. 4.7). Как обычно, перенесены строки, не умещающиеся на странице.
Число слева в каждой строке - это номер промежуточного узла. За ним идет имя хоста или маршрутизатора в этом узле и далее - IP-адрес узла. Если узнать имя не удается, то traceroute печатает только IP-адрес. Такая ситуация наблюдается в узле 13. Как видно, по умолчанию программа пыталась определить имя хоста или маршрутизатора трижды, а три числа, следующие за IP-адресом, - это Периоды кругового обращения (RTT) для каждой из трех попыток. Если при оче-РеДной попытке на запрос никто не отвечает или ответ теряется, то вместо времена печатается «*».
Хотя компьютер ziggy.usf.edu расположен в соседнем городе, в Internet между ними находится 14 узлов. Сначала данные проходят через два маршрутизатора, в Тампе, относящихся к сети net com. net (это сервис-провайдер, через которого выходит в Internet), потом еще через два маршрутизатора, а затем через маршрутизатор netcom.net в узле МАЕ-EAST (узел 5) в сеть, находящуюся в Вашингтоне, округ Колумбия. Узел МАЕ-EAST - это точка пересечения сетей, в которой сервис-провайдеры передают друг другу Internet-трафик. Далее покидает узел МАЕ-EAST и попадает в сеть sprintlink.net. От маршрутизатора сети Sprintlink в узле MAE-EAST он пролегает вдоль восточного побережья до домена usf.edu (узел 13). И наконец на шаге 14 маршрут подходит к компьютеру ziggy.
bsd: $ tracerout ziggy, usf. edu
traceroute to ziggy. usf. edu (131. 247. 1. 40), 30 hops max,
40 byte packets
1 tam-f1-pm8. netcom. net (163. 179. 44. 15)
128. 960 ms 139. 230ms 129. 483 ms
2 tam-f1-qwl. netcom. net (163. 179. 44. 254)
139. 436 ms 129.226ms 129.570 ms
3 nl-0.mig-fl-qwl.Netcom.net (165.236.144.110)
279.582 ms 199.325 ms 289.611 ms
4 a5-0-0-6.was-dc-qwl.Netcom.net (163.179.235.121)
179.505 ms 229.543 ms 179.422 ms
5 h1-0.mae-east.netcom.net (163.179.220.182)
189.258 ms 179.211 ms 169.605 ms
6 s1-mae-e-f0-0.sprintlink.net (192.41.177.241)
189.999 ms 179.399 ms 189.472 ms
7 s1-bb4-dc-1-0-0.sprintlink.net (144.228.10.41)
180.048 ms 179.388 ms 179.562 ms
8 s1-bb10-rly-2-3.sprintlink.net (144.232.7.153)
199.433 ms 179.390 ms 179.468 ms
9 s1-bb11-rly-9-0.sprintlink.net (144.232.0.46)
199.259 ms 189.315 ms 179.459 ms
10 s1-bb10-orl-1-0.sprintlink.net (144.232.9.62)
189.987 ms 199.508 ms 219.252 ms
11 s1-qw3-orl-4-0-0.sprintlink.net (144.232.2.154)
219.307 ms 209.382 ms 209.502 ms
12 s1-usf-1-0-0.sprintlink.net (144.232.154.14)
209.518 ms 199.288 ms 219.495 ms
13 131.247.254.36 (131.247.254.36) 209.318ms 199.281ms 219.588ms
14 ziggy.usf.edu (131.247.1.40) 209.591 ms * 210.159 ms
Рис. 4.7. Маршрут до хостаziggy.usf.edu, прослеженный traceroute
Посмотрим, как далеко от bsd отстоит Калифорнийский университет в Лос-Анджелесе. Понятно, что географически он находится на другом конце страны, в Калифорнии. А если выполнить traceroute до хоста panther в Калифорнийском университете, то получится результат, показанный на рис. 4.8.
На этот раз маршрут проходит только через 13 промежуточных узлов и достигает домена ucla. edu на шаге 11. Таким образом, топологически bsd ближе к Калифорнийскому университету, чем к Университету на юге Флориды.
Примечание: Университет Чепмена, расположенный также вблизи Лос-Анджелеса, находится всего в девяти промежуточных шагах от bsd. Это связано с тем, что домен chapman, edu, как и bsd, подключен к Internet через сеть netcom.net, и весь трафик проходи по этой опорной сети.
Используйте программу ttcp
| | |
Часто необходимо иметь утилиту, которая может посылать произвольный объем данных другой (или той же самой) машине по протоколу TCP или UDP и собирать статистическую информацию о полученных результатах. В этой книге уже написано несколько программ такого рода. В этом разделе вы познакомитесь с готовым инструментом, обладающим той же функциональностью. Подобное средство можно использовать для тестирования собственного приложения или для получения информации о производительности конкретного стека TCP/IP или сети. Такая информация может оказаться бесценной на этапе создания прототипа.
Этот инструмент - программа ttcp, бесплатно распространяемая Лабораторией баллистических исследований армии США (BRL - Ballistics Research Laboratory). Ее авторы Майк Муусс (автор программы ping) и Терри Слэттери. Эта утилита доступна на множестве сайтов в Internet. В книге будет использована версия, которую Джон Лин модифицировал с целью включения дополнительной статистики; ее можно получить по анонимному FTP с сайта gwen.cs.purdue.edu из каталога /pub/lin. Версия без модификаций Лина находится, например, на сайте ftp.sgi.com в каталоге sgi/ src/ttcp, в состав ее дистрибутива входит также страница руководства.
У программы ttcp есть несколько опций, позволяющих управлять: объемом Посылаемых данных, длиной отдельных операций записи и считывания, размерами буферов приема и передачи сокета, включением или отключением алгоритма Нейгла и даже выравниванием буферов в памяти. На рис. 4.11 приведена информация о порядке использования ttcp. Дается перевод на русский язык, хотя оригинальная программа, естественно, выводит справку по-английски.
Порядок вызова:ttcp -t [-опции] хост [ < in ]
ttcp -r [-опции > out]
Часто используемые опции:
-1 ## длина в байтах буферов, в которые происходит считывание из сети и запись в сеть (по умолчанию 8192)
-u использовать UDP, а не TCP
-p ## номер порта, в который надо посылать данные или прослушивать (по умолчанию 5001)
-s -t: отправить данные в сеть
-r: считать ( и отбросить) все данные из сети
-А выравнивать начало каждого буфера на эту границу(по умолчанию 16384)
-O считать, что буфер начинается с этого смещения относительно границы (по умолчанию 0)
-v печатать более подробную статистику
-d установить опцию сокета SO_DEBUG
-b ## установить размер буфера сокета (если поддерживает операционная система)
-f X формат для вычисления скорости обмена: к,К = кило (бит, байт);
m,М = мега; g,G = гига
Опции, употребляемые вместе с -t:
-n ## число буферов, записываемых в сеть (по умолчанию 2048)
-D не буферизовать запись по протоколу TCP (установить опцию сокета TCP_NODELAY)
Опции, употребляемые вместе с -r:
-В для -s, выводить только полные блоки в соответствии с опцией -1 (для TAR)
-Т "touch": обращаться к каждому прочитанному байту
Рис. 4.11. Порядок вызова ttcp
Поэкспериментируем с размером буфера передачи сокета. Сначала прогоним тест с размером буфера, выбранным по умолчанию, чтобы получить точку отсче В одном окне запустим экземпляр ttcp-потребителя:
bsd: $ ttcp –rsv
а в другом - экземпляр, играющий роль источника:
bsd: $ ttcp -tsv bsd
ttcp-t: buflen=8192, nbuf=2048, align=16384/0, port=5013 tcp -> bsd
ttcp-t: socket
ttcp-t: connect
ttcp-t: 16777216 bytes in 1.341030 real seconds
= 12217.474628 KB/sec (95.449021 Mb/sec)
ttcp-t: 16777216 bytes in 0.00 CPU seconds
= 16384000.000000 KB/cpu sec
ttcp-t: 2048 I/O calls, msec/call = 0.67, calls/sec = 1527.18
ttcp-t: buffer address 0x8050000
bsd: $
Как видите, ttcp дает информацию о производительности. Для передачи 16 Мб потребовалось около 1,3 с.
Примечание: Аналогичная статистика печатается принимающим процессом, но поскольку цифры, по существу, такие же, они здесь не приводятся.
Также был выполнен мониторинг обмена с помощью tcpdump. Вот типичная строка выдачи:
13:05:44.084576 bsd.1061 > bsd.5013: . 1:1449(1448)
ack Iwinl7376 <nop,nop,timestamp 11306 11306> (DF)
Из нее видно, что TCP посылает сегменты по 1448 байт. Теперь следует установить размер буфера передачи равным 1448 байт, и повторить эксперимент. Приемник данных нужно оставить без изменения.
bsd: $ ttcp -tsvb 1448 bsd
ttcp-t: socket
ttcp-t: sndbuf
ttcp-t: connect
ttcp-t: buflen=8192, nbuf=2048, align=16384/0, port=5013,
sockbufsize=1448 tcp -> bsd
ttcp-t: 16777216 bytes in 2457.246699 real seconds
= 6.667625 KB/sec (0.052091 Mb/sec)
ttcp-t: 16777216 bytes in 0.00 CPU seconds
= 16384000.000000 KB/cpu sec
ttcp-t: 2048 I/O calls, msec/call = 1228.62, calls/sec = 0.83 ttcp-t: buffer address 0x8050000
bds: $
На этот раз передача заняла почти 41 мин. Следует отметить, что, хотя по часам для передачи потребовалось больше 40 мин, время, затраченное процессором, Попрежнему очень мало, даже не поддается измерению. Поэтому, что бы ни произошло, это не связано с загрузкой процессора.
Теперь посмотрим, что показывает tcpdump. На рис. 4.12 приведены четыре типичные строки:
16:03:57.168093 bsd.1187 > bsd.5013: Р 8193:9641(1448)
ack 1 win 17376 <nор,ор,timestamp 44802 44802> (DF)
16:03:57.368034 bsd.5013 > bsd.1187: . ack 9641 win 17376
<nop,nор,timestamp 44802 44802> (DF)
16:03:57.368071 bsd.1187. > bsd.5013: P 9641:11089(1448)
ack 1 win;17376 <nop,nор,timestamp 44802 44802> (DF)
16:03:57.568038 bsd.5013 > bsd. 1187: .ack 11089 win 17376
<nop,nор,timestamp 44802 44802> (DF)
Рис. 4.12. Типичная выдача tcpdump для запуска ttcp -tsvb 1448 bsd
Обратите внимание, что время между последовательными сегментами составляет почти 200 мс. Возникает подозрение, что тут замешано взаимодействие между алгоритмами Нейгла и отложенного подтверждения (совет 24). И действительно именно АСК задерживаются.
Эту гипотезу можно проверить, отключив алгоритм Нейгла с помощью опции-D. Повторим эксперимент:
bsd: $ ttcp -tsvDb 1448 bsd
ttcp-t: buflen=8192, nbuf=2048, align=16384/0, port=5013,
sockbufsize=1448 tcp -> bsd ttcp-t socket ttcp-t sndbuf ttcp-t: connect
ttcp-t: nodelay
ttcp-t: 16777216 bytes in 2457.396882 real seconds
= 6.667218 KB/sec (0.052088 Mb/sec)
ttcp-t: 16777216 bytes in 0.00 CPU seconds
= 16384000.000000 KB/cpu sec
ttcp-t: 2048 I/O calls, msec/call = 1228.70, calls/sec = 0.83 ttcp-t: buffer address 0x8050000
bds: $
Как ни странно, ничего не изменилось.
Примечание: Это пример того, как опасно делать поспешные заключения. Стоило немного подумать и стало бы ясно, что алгоритм Нейгла тут ни при чем, так как посылаются заполненные сегменты. В частности, этому служит самый первый тест, - чтобы определить величину MSS.
В совете 39 будут рассмотрены средства трассировки системных вызовов. Тогда вы вернетесь к этому примеру и обнаружите, что выполняемая ttcp операция записи не возвращает управление в течение примерно 1,2 с. Косвенное указание на это видно и из выдачи ttcp, где каждый вызов операции ввода/вывода занимает приблизительно 1,228 мс. Но, как говорилось в совете 15, TCP обычно не блокирует операции записи, пока буфер передачи не окажется заполненным. Таким образом, становится понятно, что происходит. Когда ttcp записывает 8192 байта, ядро копирует первые 1448 байт в буфер сокета, после чего блокирует процесс, так как места в буфере больше нет. TCP посылает все эти байты в одном сегменте, но послать больше не может, так как в буфере ничего не осталось.
Примечание: Из рис. 4.12 видно, что дело обстоит именно так, поскольку в каждом отправленном сегменте задан флаг PSH, а стеки, берущие начало в системе BSD, устанавливают этот флаг только тогда, когда выполненная операция передачи опустошает буфер.
Поскольку приемник данных ничего не посылает в ответ, запускается механизм отложенного подтверждения, из-за которого АСК не возвращается до истечения тайм-аута в 200 мс.
В первом тесте TCP мог продолжать посылать заполненные сегменты данных, поскольку буфер передачи был достаточно велик (16 Кб на машине bsd) для сохранения нескольких сегментов. Трассировка системных вызовов для этого теста показывает, что на операцию записи уходит около 0,3 мс.
Этот пример наглядно демонстрирует, как важно, чтобы буфер передачи отправителя был, по крайней мере, не меньше буфера приема получателя. Хотя получатель был готов принимать данные и дальше, но в выходном буфере отправителя задержался последний посланный сегмент. Забыть про него нельзя, пока не придет АСК, говорящий о том, что данные дошли до получателя. Поскольку размер одного сегмента значительно меньше, чем буфер приема (16 Кб), его получение не приводит к обновлению окна (совет 15). Поэтому АСК задерживается на 200 мс. Подробнее о размерах буферов рассказано в совете 32.
Однако смысл этого примера в том, чтобы показать, как можно использовать ttcp для проверки эффекта установки тех или иных параметров TCP-соединения. Вы также видели, как анализ информации, полученной от ttcp, tcpdump и программы трассировки системных вызовов, может объяснить работу TCP.
Следует упомянуть о том, как использовать программу ttcp для организации «сетевого конвейера» между хостами. Например, скопировать всю иерархию каталогов с хоста А на хост В. На хосте В вводите команду
ttcp -rB | tar -xpf -
на хосте А - команду
tar -cf - каталог | ttcp -t A
Можно распространить конвейер на несколько машин, если на промежуточных запустить команду
ttcp -r | ttcp -t следующий_узел
Применяйте программу Isof
| | |
В сетевом (и не только) программировании часто необходимо определить, какой Процесс открыл файл или сокет. Особенно это важно в сетевом окружении, поскольку, как было показано в совете 16, при завершении процесса, работавшего с сокетом, FIN не будет послан, если другой процесс держит этот сокет открытым.
Хотя ситуация, когда другой процесс держит сокет открытым, выглядит странно, но она часто возникает, особенно при работе в UNIX. Происходит вот что: один процесс принимает соединение и запускает другой процесс, который будет работать с этим соединением (кстати, именно это и делает inetd - совет 17). Если процесс, принявший соединение, не закроет сокет после создания процесса - потомка, то счетчик ссылок на это сокет будет равен двум. Поэтому после того как потомок закроет сокет, соединение останется открытым, и FIN не будет послан. |
Та же проблема может возникнуть и по другой причине. Предположим, что хост клиента, работавшего с созданным процессом, аварийно остановился, в результате чего потомок «завис». Такая ситуация обсуждалась в совете 10. Если процесс, принимающий соединения, завершит работу, то перезапустить его будет невозможно (если, конечно, не была задана опция сокета SO_REUSEADDR, - совет 23), так как локальный порт уже привязан к созданному процессу.
В этих и некоторых других случаях необходимо знать, какой процесс (или процессы) держит сокет открытым. Утилита netstat (совет 38) сообщает, что некоторый процесс занимает данный порт или адрес, но что это за процесс, неизвестно. В некоторых версиях UNIX для ответа на этот вопрос есть программа f stat. Виктор Абель (Victor Abell) написал свободно распространяемую программу lsof, работающую почти во всех версиях UNIX.
Примечание: Дистрибутив Isof можно получить по анонимному FTP с сайта vic.cc.purdue.edu из каталога pub/tools/unix/lsof.
lsof - это исключительно гибкая программа; руководство по ней занимает 26 печатных страниц. С ее помощью можно получить "самую разнообразную информацию об открытых файлах. Как и в случае tcpdump, предоставление единого интерфейса к нескольким диалектам UNIX - это существенное достоинство.
Рассмотрим некоторые возможности lsof, полезные в сетевом программировании. В руководстве приводится подробная информация и о других ее применениях.
Предположим, что после выполнения команды netstat -af inet (совет 38) вы обнаруживаете, что некоторый процесс прослушивает порт 6000:
Active Internet connections (including servers)
Proto Recv-Q Send-Q Local Address Foreign Address (state)
Tcp 0 0 *.6000 *.* LISTEN
Порт 6000 не относится к хорошо известным (совет 18), поэтому возникает вопрос: что же его прослушивает? Как уже упоминалось, в netstat по этому поводу ничего не говорится - она лишь сообщает о наличии прослушивающего процесса. Зато программа lsof не испытывает никаких затруднений:
bsd# lsof -i TCP:6000
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
XF86_Mach 253 root 0u inetOxf5d98840 0t0 TCP *:6000 (LISTEN)
bsd#
Следует отметить, что вы запускали lsof от имени пользователя root. Это необходимо, потому что используемая версия lsof сконфигурирована для перечисления файлов, принадлежащих только данному пользователю, за исключением ситуации, когда ее запускает root. Это свойство направлено на обеспечение безопасности, но его можно отключить во время компиляции программы. Далее надо отмети, что процесс был запущен пользователем root с помощью команды XF86_Mach. Это ваш Х-сервер.
Опция -i TCP: 6000 означает, что lsof должна искать открытые ТСР-сокеты, привязанные к порту 6000. Можно было бы показать все ТСР-сокеты с помощью опции -i TCP или все TCP- и UDP-сокеты - с помощью опции -i.
Предположим, что вы еще раз запустили nets tat и обнаружили, что кто-то открыл FTP-соединение с хостом vie. ее. purdue. edu:
Active Internet connections
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp 0 0 bsd.1124 vie.cc.purdue.edu. ftp ESTABLISHED
Выяснить, кто это сделал, поможет lsof:
bsd# Isof -i @vic.cc.purdue.edu
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
ftp 450 jcs 3u inet 0xf5d99f00 0t0 TCP bsd:1124->
vie.cc.purdue.edu:ftp ESTABLISHED
bsd#
Как обычно, в имени машины bsd опущен домен и строка разбита на две. Из полученной выдачи видно, что FTP-соединение открыл пользователь jcs.
Необходимо подчеркнуть, что lsof может выдать информацию только об открытых файлах. Собственно говоря, название программы - аббревиатура list open files (перечислить открытые файлы). Это, в частности, означает, что с ее помощью нельзя получить информацию о TCP-соединениях, находящихся в состоянии TIME-WAIT (совет 22), поскольку с ними не связан никакой открытый сокет или файл.
Используйте программу netstat
| | |
Ядро операционной системы ведет разнообразную статистику об объектах, имеющих отношение к сети. Эту информацию можно получить с помощью программы netstat. Существует четыре вида запросов.
Применяйте средства трассировки системных вызовов
| | |
Иногда при отладке сетевых приложений нужно уметь трассировать обращения к ядру операционной системы. Вы уже встречались с подобной ситуацией в совете 36 и вскоре вернетесь к этому примеру.
В большинстве операционных систем есть разные способы трассировки системных вызовов. В BSD это утилита ktrace, в SVR4 (и Solaris) - truss, а в Linux- strace.
Все эти программы похожи, поэтому остановимся только на ktrace. Беглого знакомства с руководством по truss или strace должно быть достаточно для применения аналогичной методики в других системах.
Создание и применение программы для анализа ICMP-сообщений
| | |
Иногда необходимо знать, какие сообщения приходят в протоколе ICMP. Конечно, для их перехвата всегда можно воспользоваться программой tcpdump или Другим сетевым анализатором, но иногда простой инструмент оказывается более Удобным. Применение tcpdump влечет за собой некоторое снижение производительности, а также угрозу безопасности, хотя прослушивание ICMP-сообщений совершенно безобидно и ненакладно.
Во-первых, для работы такового сетевого анализатора, как tcpdump, нужно перевести сетевой интерфейс в режим пропускания. Это увеличивает нагрузку на центральный процессор, так как прерывание будет возникать при проходе через интерфейс каждого пакета Ethernet, даже если он адресован не той машине, на которой работает анализатор.
Во-вторых, во многих организациях применение сетевых анализаторов ограничено или вообще запрещено из-за потенциальной опасности перехвата информации и кражи паролей. Поэтому чтение ICMP-сообщений там более приемлемо.
В данном разделе разработан инструмент, который позволяет отслеживать ICMP-сообщения и не имеет недостатков, присущих сетевому анализатору общего назначения. Это позволит изучить простые сокеты, с которыми вы пока не сталкивались.
В совете 33 упоминалось, что ICMP-сообщения транспортируются в составе датаграмм. Обычно содержимое ICMP-сообщения зависит от его типа, но интерес представляют только поля icmp_type и icmp_code, показанные на рис. 4.20. Дополнительные поля будут рассмотрены в связи с сообщениями о недоступности ресурса.

Рис. 4.20. Общий формат ICMP-сообщения
Часто возникают недоразумения при ответе на вопрос, что такое простые сокеты и для чего они нужны. Простые сокеты нельзя использовать для перехвата TCP-сегментов или UDP-датаграмм, поскольку они таким сокетам не передаются. Не годятся они и для получения всех ICMP-сообщений. Например, в системах, производных от BSD, эхо-запросы ICMP, запросы о временном штампе и запросы маски адреса полностью обрабатываются ядром и не передаются простым сокетам. В общем случае простой сокет получает все IP-датаграммы, в заголовках которых указан неизвестный ядру протокол, большинство ICMP-сообщений и все без исключения ICMP-сообщения.
Важно также отметить, что в простой сокет поступает вся IP-датаграмма целиком, включая заголовок. Ваша программа должна будет пропускать IP-заголовок.
Читайте книги Стивенса
| | |
В сетевых конференциях чаще всего задают вопрос: «Какие книги нужно читать, чтобы освоить TCP/IP?». В подавляющем большинстве ответов упоминаются книги Ричарда Стивенса.
В этой книге много ссылок на работы Стивенса. Для сетевых программистов этот автор написал две серии книг: «TCP/IP Illustrated» в трех томах и «UNIX Network Programming» в двух. Они преследуют разные цели, поэтому рассмотрим их по отдельности.
Читайте тексты программ
| | |
Начинающие программисты часто спрашивают более опытных коллег, откуда тем столько всего известно. Конечно, знания и опыт приобретаются разными способами, но один из самых важных, хотя и недооцениваемых, - это чтение программ, написанных мастерами.
Расширяющееся движение за открытые исходные тексты облегчает эту задачу. Чтение и разбор высококачественного кода имеют множество плюсов, самое очевидное - это ознакомление с подходом, выбранным экспертом для решения задачи. Вы можете применить такую методику в своих программах, немного ее модифицировав и адаптировав. При этом вырабатываются собственные приемы. 1И когда-нибудь будут читать уже ваш код и восхищаться красивым решением.
Не так очевидно, хотя в некоторых отношениях более важно осознание того, что нет никакой магии. Начинающие программисты иногда склонны думать, что код операционной системы или реализации протоколов непостижим, он создается высшими силами, а простым смертным нечего и пытаться в нем разобраться. Но, читая код, вы понимаете, что это просто образец хорошей (по большей части, стандартной) практики инженерного проектирования, и вам это тоже под силу.
Короче говоря, изучая код, вы приходите к выводу, что глубокое и таинственное- в действительности вопрос применения стандартных приемов, овладеваете этими приемами и учитесь применять их на практике. Читать код нелегко. Для этого требуется высокая концентрация внимания, но усилия окупаются сторицей.
Есть несколько источников хорошего кода, но лучше получить еще и комментарии. Книга Лионса «A Commentary on the UNIX Operating System» [Lions 1977] давно уже ходила в списках. Недавно благодаря усилиям нескольких людей, в частности Денниса Ричи, и великодушию компании SCO, которая сейчас владеет исходными текстами UNIX, эта книга стала доступна широкой публике.
Примечание: Первоначально книгу могли приобрести только держатели лицензии на исходные тексты UNIX, но подпольная ксерокопия (или копия с ксерокопии) была вожделенным призом для многих программистов в дни становления UNIX.
В книге приведен код очень ранней (шестой) версии операционной системы UNIX, в которой не было сетевых компонент, кроме TTY-терминалов с разделением времени. Тем не менее стоит изучить этот код, даже если вы не интересуетесь системой UNIX, поскольку это прекрасный пример конструирования программного обеспечения.
Еще одна отличная книга по операционным системам, включающая исходные тексты, - это «Operating Systems: Design and Implementation» [Tanenbaum and Woodhull, 1997]. В ней описана операционная система MINIX. Хотя в самом тексте сетевой код не приводится, но он есть на прилагаемом компакт-диске.
Для тех, кого больше интересуют сетевые задачи, предназначен второй том книги «TCP/IP Illustrated» [Wright and Stevens 1995]. Она упоминалась в совете 41.
В этой книге описывается код из системы BSD, на базе которой создано несколько современных систем с открытыми исходными текстами (FreeBSD, OpenBSD, NetBSD). Она дает прекрасный материал для экспериментов с кодом. Оригинальный код системы 4.4BSD Lite можно получить с FTP-сервера компании Walnut Creek CD-ROM (ftp://ftp.cdrom.eom/pub/4.4BSD-Lite).
Во втором томе книги «Работа в сетях: TCP/IP» [Comer and Stevens 1999 описан другой стек TCP/IP. Как и в предыдущей, в ней приводится подробно! объяснение принципа работы кода. Код можно загрузить из сети.
Есть много и других источников кода, хотя, как правило, он не сопровождаете; пояснениями в виде книги. Начать можно с открытых систем UNIX или Linux. Для всех подобных проектов исходные тексты доступны на CD-ROM или через FTP.
В проекте GNU, основанном фондом Free Software Foundation, имеется исходный текст переписанных с нуля реализаций большинства стандартных утилит UNIX. Это тоже отличный материал для изучения.
Информацию об этих проектах можно найти на следующих сайтах:
домашняя страница FreeBSD http://www.freebsd.org/
проект GNU http://www.gnu.org/
архивы ядер Linux http://www.kernel.org/
домашняя страница NetBSD http://www.netbsd.org/
домашняя страница OpenBSD http://www.openbsd.org/
В каждом из этих источников есть огромное количество исходных текстов, связанных с сетевым программированием, и их стоит изучить, даже если UNIX не находится в сфере ваших интересов.
Изучайте RFC
| | |
Ранее говорилось, что спецификации семейства протоколов TCP/IP и связанные с ними архитектурные вопросы Internet содержатся в серии документов, объединенных названием Request for Comments (RFC - Предложения для обсуждения). На самом деле, RFC, впервые появившиеся в 1969 году, - это не только спецификации протоколов. Их можно назвать рабочими документами, в которых обсуждаются разнообразные аспекты компьютерных коммуникаций и сетей. Не все RFC чисто технические, в них встречаются забавные наблюдения, пародии стихи и просто различные высказывания. К концу 1999 года было более 2000 при своенных RFC номеров, правда, некоторые из них так и не были опубликованы.
Хотя не в каждом RFC содержится какой-либо стандарт Internet, любой стандарт Internet опубликован в виде RFC. Материалам, входящим в подсерию RFC дается дополнительная метка «STDxxxx». Текущий список стандартов и тех RFC которые находятся на пути принятия в качестве стандарта, опубликован в документе STD0001.
Не следует, однако, думать, что RFC, не упомянутые в документе STD0001 лишены технической ценности. В некоторых описываются идеи пока еще разрабатываемых протоколов или направления исследовательских работ. Другие содержат информацию или отчеты о деятельности многочисленных рабочих групп, созданных по решению IETF (Internet Engineering Task Force - проблемная группа проектирования Internet).
Участвуйте в конференциях Usenet
| | |
Одно из самых ценных мест в Internet в плане получения советов и информации- это конференции Usenet, посвященные сетевому программированию. Существуют конференции практически по любому аспекту сетевых технологий от прокладки кабелей (comp.dcom.cabling) до синхронизирующего сетевого протокола NTP (comp.protocols.time.ntp).
Замечательная конференция, относящаяся к протоколам семейства TCP/IP и программированию с их помощью, - comp.protocols.tcp-ip. Всего лишь несколько минут, ежедневно потраченных на просмотр сообщений в этой конференции, даст массу полезной информации, советов и приемов. Обсуждаемые темы варьируются от подключения к сети машины под управлением Windows до тонких технических вопросов по протоколам TCP/IP, их реализации и работы.
В самом начале знакомства с конференциями по сетям вызвать недоумение может даже простое их перечисление (а их не меньше 70). Лучше всего начать с конференции comp.protocols.tcp-ip и, возможно, одной из конференций по конкретной операционной системе, например, comp.os.linux.networking или comp.ms - windows.programmer.tools.winsock. Сообщения в этих конференциях могут содержать ссылки на другие, более специальные конференции, которые тоже могут быть вам интересны или полезны.
Один из лучших способов чему-то научиться в сетевых конференциях - это отвечать на вопросы. Изложив свои знания по конкретному вопросу в форме, понятной для других, вы сами глубже разберетесь в проблеме. Небольшое усилие, требуемое для составления ответа из 50-100 слов, окупится многократно.
Отличное введение в систему конференций Usenet находится на сайте Информационного центра Usenet (http://metalab.unc.edu/usenet-i/). На этом сайте есть статьи по истории и использованию Usenet, а также краткая статистика для большинства конференций, в том числе среднее число сообщений в день, среднее число читателей, адрес модератора (если таковой есть), где хранится архив (если он ведется) и ссылки на часто задаваемые вопросы (FAQ) для каждой конференции. На сайте Информационного центра Usenet есть поисковая система, позволяющая найти конференции, в которых обсуждается интересующая вас тема.
Выше упоминалось, что во многих конференциях ведутся FAQ, с которыми стоит ознакомиться, прежде чем задавать вопрос. Если задать вопрос, на который уже есть ответ в FAQ, то, скорее всего, вас к нему и отошлют, а, может быть, и пожурят за нежелание потрудиться самому.
Статистика протоколов
С помощью netstat можно получить статистику протоколов. Если задать опцию -s, то netstat напечатает статистические данные по протоколам IP, ICMP, IGMP, UDP и TCP. Если нужен какой-то один протокол, то его можно указать посредством опции -р. Так, для получения статистики по протоколу UDP следует ввести следующую команду:
bsd: $ netstat -sp udp
udp:
82 datagrams received
0 with incomplete header
0 with bad data length field
0 with bad checksum
1 dropped due to no socket
0 broadcast/multicast datagrams dropped due to no socket
0 dropped due to full socket buffers
0 not for hashed pcb
81 delivered
82 datagrams output
bsd: $
Ниже дается перевод на русский язык, программа netstat использует английский.
udp:
82 датаграмм получено
0 с неполным заголовком
0 с неправильным значением в поле длины данных
0 с неправильной контрольной суммой
1 отброшено из-за отсутствия сокета
0 отброшено широковещательных/групповых датаграмм
из-за отсутствия сокета
0 отброшено из-за переполнения буфера сокета О не для хэшированного блока
управления протоколом
81 доставлено
82 отправлено датаграмм
Можно отменить печать строк с нулевыми значениями, если дважды задать опцию -s:
bsd: $ netstat -ssp udp
udp:
82 datagrams received
1 dropped due to no socket
81 delivered
82 datagrams output
bsd: $
Периодический просмотр статистики TCP оказывает очень «отрезвляющее» действие. На машине bsd netstat выводит для TCP 45 статистических показателей. Вот строки с ненулевыми значениями, которые были получены при запуске netstat-ssp tcp:
tcp:
446 packets sent
190 data packets (40474 bytes)
213 ack-only packets (166 delayed)
18 window update packets
32 control packets
405 packets received
193 acks (for 40488 bytes)
12 duplicate acks
302 packets (211353 bytes) received in sequence
10 completely duplicate packets (4380 bytes)
22 out-of-order packets (16114 bytes)
2 window update packets
20 connection requests
2 connection accepts
13 connections established (including accepts)
22 connection closed (including 0 drops)
3 connections updated cached RTT on close
3 connections updated cached RTT variance on close
2 embryonic connections dropped
193 segments updated rtt (of 201 attempts)
31 correct ACK header predictions
180 correct data packet header predictions
Далее дается перевод статистической информации на русский язык.
tcp:
446 пакетов послано
190 пакетов данных (40474 байта)
213 пакетов, содержащих только ack (166 отложенных)
18 пакетов с обновлением окна
32 контрольных пакета
405 пакетов принято
193 ack (на 40488 байт)
12 повторных ack
302 пакета (211353 байта) получено по порядку
10 пакетов - полных дубликатов (4380 байт)
22 пакета не по порядку (16114 байта)
2 пакета с обновлением окна
20 запросов на соединение
2 приема соединения
13 соединений установлено (включая принятые)
22 соединения закрыто (включая 0 сброшенных)
3 соединения при закрытии обновили RTT в кэше
3 соединения при закрытии обновили дисперсию RTT в кэше
2 эмбриональных соединения сброшено
193 сегмента обновили rtt (из 201 попыток)
31 правильное предсказание заголовка АСК
180 правильных предсказаний заголовка пакета с данными
Эта статистика получена после перезагрузки машины bsd и последовавших за ней отправки и получения нескольких сообщений по электронной почте, а также чтения нескольких телеконференций. Если предположить, что такие события, как доставка пакетов не по порядку или получение дубликатов пакетов, происходят очень редко, то полученная информация полностью развеет эти иллюзии. Так, из 405 полученных пакетов 10 оказались дубликатами, а 22 пришли не по порядку.
Примечание: В работе [Bennett et al. 1999] показано, что приход пакетов не по порядку не обязательно свидетельствует о неисправности. Также объясняется, почему в будущем следует ожидать широкого распространения этого явления.
«TCP/IP illustrated»
Как следует из названия, серия «TCP/IP Illustrated» трактует работу наиболее распространенных протоколов из семейства TCP/IP и программ, в которых они применяются. В совете 14 говорилось, что основное средство для исследования - это программа tcpdump. Запуская небольшие тестовые программы и наблюдая за генерируемым ими сетевым трафиком, вы постепенно начинаете понимать, как на практике функционируют протоколы.
Используя различные операционные системы, Стивенс показывает, что реализации в них одного и того же протокола приводят к тонким отличиям в его работе. Еще важнее, что вы учитесь ставить собственные эксперименты, а затем интерпретировать их результаты, отвечая тем самым на возникающие вопросы.
Поскольку в каждом томе семейство протоколов TCP/IP рассматривается под разными углами зрения, имеет смысл кратко охарактеризовать каждую книгу.
Том 1: Протоколы
В этом томе описываются классические протоколы TCP/IP и их взаимосвязи. Сначала рассматриваются протоколы канального уровня, такие как Ethernet, SLIP и РРР. Далее автор переходит к протоколам АКР и RARP (Reverse Address Resolution Protocol- протокол определения адреса по местоположению узла сети) и рассматривает их в качестве связующего звена между канальным и межсетевым уровнями.
Несколько глав посвящено протоколу IP и его связям с ICMP и маршрутизацией. Также анализируются утилиты ping и traceroute, работающие на уровне IP.
Далее речь идет о протоколе UDP и смежных вопросах: широковещании и протоколе IGMP. Описываются также основанные на UDP протоколы: DNS, TFTP (Trivial File Transfer Protocol - тривиальный протокол передачи файлов) и ВООТР (Bootstrap Protocol - протокол начальной загрузки по сети).
Восемь глав посвящено протоколу TCP. В нескольких главах обсуждаются распространенные приложения на базе TCP, такие как telnet, rlogin, FTP, SMTP (электронная почта) и NFS.
Том 2: Реализация
Второй том, написанный в соавторстве с Гэри Райтом (Gary Wright), - это практически построчное описание сетевого кода из операционной системы 4.4BSD. Поскольку код из системы BSD широко признан как эталонная реализация, эта книга незаменима для тех, кто хочет лучше разбираться в реализации основных протоколов семейства TCP/IP.
В книге рассматривается реализация нескольких протоколов канального уровня (Ethernet, SLIP и возвратный интерфейс), протокола IP, маршрутизации, протоколов ICMP, IGMP, UDP и TCP, группового вещания, уровня сокетов, а также несколько смежных тем. Поскольку автор приводит реальный код, читатель может получить представление о том, какие проблемы возникают при реализации сложной сетевой системы, и на какие компромиссы приходится идти.
Том 3: TCP для транзакций, HTTP, NNTP и протоколы в адресном домене UNIX
Третий том - это продолжение первого и второго. Он начинается с описания протокола Т/ТСР и принципов его функционирования. Это описание построено так же, как и в первом томе. Далее приводится реализация Т/ТСР - по типу второго тома.
Во второй части рассматриваются два популярных прикладных протокола. HTTP (Hypertext Transfer Protocol - протокол передачи гипертекста) и NNTP (Network News Transfer Protocol - сетевой протокол передачи новостей), которые составляют основу сети World Wide Web и сетевых телеконференций Usenet соответственно.
И, наконец, исследуются сокеты в адресном домене UNIX и их реализация. По сути, это продолжение второго тома, не включенное в него из-за ограничений на объем издания.
TCP-серверы
Для TCP-серверов inetd прослушивает хорошо известные порты, ожидая запроса на соединение, затем принимает соединение, ассоциирует с ним файловые Дескрипторы stdin, stdout и stderr, после чего запускает приложение. Таким образом, сервер может работать с соединением через дескрипторы 0, 1 и 2. Если это допускается конфигурационным файлом inetd (/etc/ inetd.conf), то inetd продолжает прослушивать тот же порт. Когда в этот порт поступает запрос на новое соединение, запускается новый экземпляр сервера, даже если первый еще не завершил сеанс. Это показано на рис. 3.2. Обратите внимание, что серверу не нужно обслуживать нескольких клиентов. Он просто выполняет запросы одного клиента, а потом завершается. Остальные клиенты обслуживаются дополнительными экземплярами сервера.

Рис. 3.2. Действия inetd при запуске TCP-сервера
Применение inetd освобождает от необходимости самостоятельно устанавливать TCP или UDP-соединение и позволяет писать сетевое приложение почти так же, как обычный фильтр. Простой, хотя и не очень интересный пример приведен в листинге 3.3.
Листинг 3.3. Программа rlnumd для подсчета строк
1 #include <stdio.h>
2 void main( void )
3 {
4 int cnt = 0;
5 char line[ 1024 ];
6 /*
7 *Мы должны явно установить режим построчной буферизации,
8 *так как функции из библиотеки стандартного ввода/вывод
9 *не считают сокет терминалом. */
10 setvbuf( stdout, NULL, _IOLBF, 0 );
11 while ( fgets ( line, sizeof( line ) , stdin ) != NULL )
12 printf( "%3i: %s", ++cnt, line );
13 }
По поводу этой программы стоит сделать несколько замечаний:
в тексте программы не упоминается ни о TCP, ни вообще о сети. Это не значит, что нельзя выполнять связанные с сокетами вызовы (getpeername, [gs ] etsockopt и т.д.), просто в этом не всегда есть необходимость. Нет никаких ограничений и на использование read и write. Кроме того, можно пользоваться вызовами send, recv, sendto и recvfrom, как если бы inetd не было.
режим буферизации строк приходится устанавливать самостоятельно, поскольку стандартная библиотека ввода/вывода автоматически устанавливает подобный режим только в том случае, если считает, что вывод производится на терминал. Это позволяет обеспечить быстрое время реакции для интерактивных приложений;
стандартная библиотека берет на себя разбиение входного потока на строки. Об этом уже говорилось в совете 6;
предполагаем, что не будет строк длиннее 1023 байт. Более длинные строки будут разбиты на несколько частей, и у каждой будет свой номер;
Примечание: Этот факт, который указан в книге [Oliver 2000], служит еще одним примером того, как можно легко допустить ошибку переполнения буфера. Подробнее этот вопрос обсуждался в совете 11.
хотя это приложение тривиально, но во многих «настоящих» TCP-приложениях, например telnet, rlogin и ftp, используется такая же техника.
Программа в листинге 3.3 может работать и как «нормальный» фильтр, и как Удаленный сервис подсчета строк. Чтобы превратить ее в удаленный сервис, нужно только выбрать номер порта, добавить в файл /etc/ services строку с именем сервиса и номером порта и включить в файл /etc/inetd.conf строку, описывающую этот сервис и путь к исполняемой программе. Например, если вы назовете сервис rlnum, исполняемую программу для него –
rlnumd и назначите ему порт 8000, то надо будет добавить в /etc/services строку
rlnum 8000/tcp # удаленный сервис подсчета строк,
а в /etc/inetd.conf - строку
rlnum stream tcp nowait jcs /usr/home/jcs/rlnumd rlnumd.
Добавленная в /etc/services строка означает, что сервис rlnum использует протокол TCP по порту 8000. Смысл же полей в строке, добавленной в /etc/inetd.conf, таков:
имя сервиса, как он назван в /etc/services. Это имя хорошо известного порта, к которому подсоединяются клиенты данного сервера. В вашем примере - rlnum;
тип сокета, который нужен серверу. Для TCP-серверов это stream, a для UDP-серверов - dgram. Поскольку здесь сервер пользуется протоколом ТCP указан stream;
протокол, применяемый с сервером, - tcp или udp. В данном примере это tср;
флаг wait/nowait. Для UDP- серверов его значение всегда wait, а для ТСР-серверов - почти всегда nowait. Если задан флаг nowait, то inetd сразу после запуска сервера возобновляет прослушивание связанного с ним хорошо известного порта. Если же задан флаг wait, то inetd не производит никакой работы с этим сокетом, пока сервер не завершится. А затем он возобновляет прослушивание порта в ожидании запросов на новые соединения (для stream-серверов) или новых датаграмм (для dgram-серверов). Если для stream-сервера задан флаг wait, то inetd не вызывает accept для соединения, а передает сокет, находящийся в режиме прослушивания, самому серверу, который должен принять хотя бы одно соединение перед завершением. Как отмечено в сообщении [Kacker 1998], задание флага wait для TCP-приложения - это мощная, но редко используемая возможность. Здесь приводится несколько применений флага wait для TCP-соединений:
- в качестве механизма рестарта для ненадежных сетевых программ-демонов. Пока демон работает корректно, он принимает соединения от клиентов, но если по какой-то причине демон «падает», то при следующей попытке соединения inetd его рестартует;
- как способ гарантировать одновременное подключение только одного клиента;
- как способ управления многопоточным или многопроцессным приложением, зависящим от нагрузки. В этом случае начальный процесс запускается inetd, а затем он динамически балансирует нагрузку, создавая по мере необходимости дополнительные процессы или потоки. При уменьшении нагрузки, потоки уничтожаются, а в случае длительного простоя завершает работу и сам процесс, освобождая ресурсы и возвращая прослушивающий сокет inetd.
В данном примере задан флаг nowait, как и обычно для TCP-серверов.
имя пользователя, с правами которого будет запущен сервер. Это имя должно присутствовать в файле /etc/passwd. Большинство стандартных серверов, прописанных в inetd. conf, запускаются от имени root, но это совершенно необязательно. Здесь в качестве имени пользователя выбрано jcs;
полный путь к файлу исполняемой программы. Поскольку rlnumd находится в каталоге пользователя jcs, задан путь /usr/home/ jcs/rlnumd;
до пяти аргументов (начиная с argv [ 0 ]), которые будут переданы серверу. Поскольку в этом примере у сервера нет аргументов, оставлен только argv [ 0 ]
Чтобы протестировать сервер, необходимо заставить inetd перечитать свой конфигурационный файл (в большинстве реализаций для этого нужно послать ему сигнал SIGHUP) и соединиться с помощью telnet:
bsd: $ telnet localhost rlnum
Trying 127.0.0.1. . .
Connected to localhost
Escape character is "^]".
hello
1: hello
world
2: world
^]
telnet> quit
Connection closed.
bsd: $
Тексты RFC
Получить копии RFC можно разными путями, но самый простой - зайти на Web-страницу редактора RFC http://www.rfc-editor.org. На этой странице есть основанное на заполнении форм средство загрузки, значительно упрощающее поиск. Есть также поиск по ключевым словам, позволяющий найти нужные RFC, если их номер неизвестен. Там же можно получить документы из подсерий STD, FYI и ВСР (Best Current Practices - лучшие современные решения).
RFC можно также переписать по FTP с сайта ftp.isi.edu из каталога in-notes/ и из других FTP-архивов.
Если у вас нет доступа по протоколам HTTP или FTP, то можно заказать копии RFC по электронной почте. Подробные инструкции о том, как сделать заказ, а также список FTP-сайтов вы получите, послав электронное сообщение по адресу rfc-info@isi.edu, включив одну строку:
help: ways_to_get_rfcs
Какой бы способ вы ни выбрали, прежде всего надо загрузить текущий указатель RFC (файл rfс-index. txt). После публикации ни номер, ни текст RFC уже не изменяются, так что единственный способ модифицировать RFC - это выпустить другое RFC, заменяющее предыдущее. Для каждого RFC в указателе отмечено, есть ли для него заменяющее RFC и если есть, то его номер. Там же указаны RFC, которые обновляют, но не замещают прежние.
И, наконец, различные компании поставляют RFC на CD. Так, Walnut Creek CD-ROM (http://www.cdrom.com) и InfoMagic (http://www.infomagic.com) предлагают компакт-диски, на которых записаны как RFC, так и другие документы, относящиеся к Internet. Разумеется, перечень RFC на таких дисках быстро становится неполным, но, поскольку RFC сами по себе не подлежат изменению, диск может устареть только в том смысле, что не содержит последних RFC.
| | |
Текущее состояние организации подсетей и CIDR
Подсети в том виде, в каком они описаны в RFC 950 [Mogul and Postel 1985],-это часть Стандартного протокола (Std. 5). Это означает, что каждый хост, на котором установлен стек TCP/IP, обязан поддерживать подсети.
CIDR (RFC 1517 [Hinden 1993], RFC 1518, RFC 1519) - часть предложений к стандартному протоколу, и потому не является обязательной. Тем не менее CIDR применяется в Internet почти повсеместно, и все новые адреса выделяются этим способом. Группа по перспективным разработкам в Internet (IESG - Internet Engineering Steering Group) выбрала CIDR как промежуточное временное решение проблемы роста маршрутных таблиц.
В перспективе обе проблемы - исчерпания адресов и роста маршрутных таблиц - предполагается решать с помощью версии 6 протокола IP. IPv6 имеет большее адресное пространство (128 бит) и изначально поддерживает иерархию. Такое адресное пространство (включая 64 бита для идентификатора интерфейса) гарантирует, что вскоре IP-адресов будет достаточно. Иерархия IРv6-адресов позволяет держать размер маршрутных таблиц в разумных пределах.
UDP-серверы
Поскольку в протоколе UDP соединения не устанавливаются (совет 1), inetd нечего слушать. При этом inetd запрашивает операционную систему (с помощью вызова select) о приходе новых датаграмм в порт UDP-сервера. Получив извещение, inetd дублирует дескриптор сокета на stdin, stdout и stderr и запускает UDP-сервер. В отличие от работы с TCP-серверами при наличии флага nowait, inetd больше не предпринимает с этим портом никаких действий, пока сервер не завершит сеанс. В этот момент он снова предлагает системе извещать его о новых датаграммах. Прежде чем закончить работу, серверу нужно прочесть хотя бы одну датаграмму из сокета, чтобы inetd не «увидел» то же самое сообщение, что и раньше. В противном случае он опять запустит сервер, войдя в бесконечный цикл.
Пример простого UDP-сервера, запускаемого через inetd, приведен в листинге 3.4. Этот сервер возвращает то, что получил, добавляя идентификатор своего процесса.
Листинг 3.4. Простой сервер, реализующий протокол запрос-ответ
udpecho1.с
1 ttinclude "etcp.h"
2 int main( int argc, char **argv )
3 {
4 struct sockaddr_in peer;
5 int rc;
6 int len;
7 int pidsz;
8 char buf[ 120 ] ;
9 pidsz = sprintf( buf, "%d: ", getpid () ) ;
10 len = sizeof( peer );
11 rc = recvfromt 0, buf + pidsz, sizeof( buf ) - pidsz, 0,
12 ( struct sockaddr * )&peer, &len);
13 if ( rc <= 0 )
14 exit ( 1 ) ;
15 sendto( 1, buf, re + pidsz, 0,
16 (struct sockaddr * )&peer, len);
17 exit( 0 );
18 }
updecho1
9 Получаем идентификатор процесса сервера (PID) от операционной системы, преобразуем его в код ASCII и помещаем в начало буфера ввода/вывода.
10-14 Читаем датаграмму от клиента и размещаем ее в буфере после идентификатора процесса. 15-17 Возвращаем клиенту ответ и завершаем сеанс.
Для экспериментов с этим сервером воспользуемся простым клиентом, код которого приведен в листинге 3.5. Он читает запросы из стандартного ввода, отсылает их серверу и печатает ответы на стандартном выводе.
Листинг 3.5. Простой UDP-клиент
1 #include "etcp.h"
2 int main( int argc, char **argv )
з {
4 struct sockaddr_in peer;
5 SOCKET s;
6 int rc = 0;
7 int len;
8 char buf[ 120 ];
9 INIT();
10 s = udp_client( argv[ 1 ], argvf 2 ], &peer );
11 while ( fgets( buf, sizeof'( buf ), stdin ) != NULL )
12 {
13 rc = sendto( s, buf, strlenf buf ), 0,
14 (struct sockaddr * )&peer, sizeof( peer ) );
15 if ( rc < 0 )
16 error( 1, errno, "ошибка вызова sendto" );
17 len = sizeof( peer );
18 rc = recvfrom( s, buf, sizeof( buf ) - 1, 0,
19 (struct sockaddr * )&peer, &len );
20 if ( rc < 0 )
21 error( 1, errno, "ошибка вызова recvfrom" );
22 buff [rc ] = '\0';
23 fputsf (buf, stdout);
24 }
25 EXIT( 0 ) ;
26 }
10 Вызываем функцию udp_client, чтобы она поместила в структуру peer адрес сервера и получила UDP-сокет.
11-16 Читаем строку из стандартного ввода и посылаем ее в виде UDP-датаграммы хосту и в порт, указанные в командной строке.
17-21 Вызываем recvfrom для чтения ответа сервера и в случае ошибки завершаем сеанс.
22-23 Добавляем в конец ответа двоичный нуль и записываем строку на стандартный вывод.
В отношении программы udpclient можно сделать два замечания:
в реализации клиента предполагается, что он всегда получит ответ от сервера. Как было сказано в совете 1, нет гарантии, что посланная сервером датаграмма будет доставлена. Поскольку udpclient - это интерактивная программа, ее всегда можно прервать и запустить заново, если она «зависнет» в вызове recvfrom. Но если бы клиент не был интерактивным, нужно было бы взвести таймер, чтобы предотвратить потери датаграмм;
Примечание: В сервере udpechol об этом не нужно беспокоиться, так как точно известно, что датаграмма уже пришла (иначе inetd не запустил бы сервер). Однако уже в следующем примере (листинг 3.6) приходится думать о потере датаграмм, так что таймер ассоциирован с recvfrom.
при работе с сервером udpechol не нужно получать адрес и порт отправителя, так как они уже известны. Поэтому строки 18 и 19 можно было бы заменить на:
rc = recvfrom( s, buf, sizeof( buf ) - 1, 0, NULL, NULL );
Но, как показано в следующем примере, иногда клиенту необходимо иметь информацию, с какого адреса сервер послал ответ, поэтому приведенные здесь UDP-клиенты всегда извлекают адрес.
Для тестирования сервера добавьте в файл /etc/inetd.conf на машине bsd строку
udpecho dgram udp wait jcs /usr/home/jcs/udpechod udpechod,
а в файл /etc/services – строку
udpecho 8001/udp
Затем переименуйте udpechol в udpechod и заставьте программу inetd перечитать свой конфигурационный файл. При запуске клиента udpclient на машине sparc получается:
sparc: $ udpclient bed udpeoho
one
28685: one
two
28686: two
three
28687: three
^C
spare: $
Этот результат демонстрирует важную особенность UDP-серверов: они обычно ведут диалог с клиентом. Иными словами, сервер получает один запрос и посылает один ответ. Для UDP-серверов, запускаемых через inetd, типичными будут следующие действия: получить запрос, отправить ответ, выйти. Выходить нужно как можно скорее, поскольку inetd не будет ждать других запросов, направленных в порт этого сервера, пока тот не завершит сеанс.
Из предыдущей распечатки видно, что, хотя складывается впечатление, будто udpclient ведет с udpechol диалог, в действительности каждый раз вызывается новый экземпляр сервера. Конечно, это неэффективно, но важнее то, что сервер не запоминает информации о состоянии диалога. Для udpechol это несущественно так как каждое сообщение - это, по сути, отдельная транзакция. Но так бывает не всегда. Один из способов решения этой проблемы таков: сервер принимает сообщение от клиента (чтобы избежать бесконечного цикла), затем соединяется с ним, получая тем самым новый (эфемерный) порт, создает новый процесс и завершает работу. Диалог с клиентом продолжает созданный вновь процесс.
Примечание: Есть и другие возможности. Например, сервер мог бы обслуживать нескольких клиентов. Принимая датаграммы от нескольких клиентов, сервер амортизирует накладные расходы на свой запуск и не завершает сеанс, пока не обнаружит, что долго простаивает без дела. Преимущество этого метода в некотором упрощении клиентов за счет усложнения сервера.
Чтобы понять, как это работает, внесите в код udpechol изменения, представленные в листинге 3.6.
Листинг 3.6. Вторая версия udpechod
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 struct sockaddr_in peer;
5 int s;
6 int rc;
7 int len;
8 int pidsz;
9 char buf[ 120 ] ;
10 pidsz = sprintf( buf, "%d: ", getpid() );
11 len = sizeof( peer );
12 rc = recvfrom( 0, buf + pidsz, sizeof( buf ) - pidsz,
13 0, ( struct sockaddr * )&peer, &len );
14 if ( rc < 0 )
15 exit ( 1 );
16 s = socket( AF_INET, SOCK_DGRAM, 0 );
17 if ( s < 0 )
18 exit( 1 ) ;
19 if ( connect( s, ( struct sockaddr * )&peer, len ) < 0)
20 exit (1);
21 if ( fork() != 0 ) /* Ошибка или родительский процесс? */
22 exit( 0 ) ;
23 /* Порожденный процесс. */
24 while ( strncmp( buf + pidsz, "done", 4 ) != 0 )
25 {
26 if ( write( s, buf, re + pidsz ) < 0 )
27 break;
28 pidsz = sprintf( buf, "%d: ", getpid() );
29 alarm( 30 );
30 rc = read( s, buf + pidsz, sizeof( buf ) - pidsz );
31 alarm( 0 );
32 if ( re < 0)
33 break;
34 }
35 exit( 0 );
36 }
udpecho2
10-15 Получаем идентификатор процесса, записываем его в начало буфера и читаем первое сообщение так же, как в udpechol.
16-20 Получаем новый сокет и подсоединяем его к клиенту, пользуясь адресом в структуре peer, которая была заполнена при вызове recvfrom.
21-22 Родительский процесс разветвляется и завершается. В этот момент inetd может возобновить прослушивание хорошо известного порта сервера в ожидании новых сообщений. Важно отметить, что потомок использует номер порта new, привязанный к сокету s в результате вызова connect.
24-35 Затем посылаем клиенту полученное от него сообщение, только с добавленным в начало идентификатором процесса. Продолжаем читать сообщения от клиента, добавлять к ним идентификатор процесса-потомка и отправлять их назад, пока не получим сообщение, начинающееся со строки done. В этот момент сервер завершает работу. Вызовы alarm, окружающие операцию чтения на строке 30, - это защита от клиента, который закончил сеанс, не послав done. В противном случае сервер мог бы «зависнуть» навсегда. Поскольку установлен обработчик сигнала SIGALRM, UNIX завершает программу при срабатывании таймера.
Переименовав новую версию исполняемой программы в udpechod и запустив ее. вы получили следующие результаты:
sparc: $ udpclient bad udpecho
one
28743: one
two
28744: two
three
28744: three
done
^C
sparc: $
На этот раз, как видите, в первом сообщении пришел идентификатор родительского процесса (сервера, запущенного inetd), а в остальных - один и тот же идентификатор (потомка). Теперь вы понимаете, почему udpclient всякий раз извлекает адрес сервера: ему нужно знать новый номер порта (а возможно, и новый IP-адрес если сервер работает на машине с несколькими сетевыми интерфейсами), в который посылать следующее сообщение. Разумеется, это необходимо делать только для первого вызова recvfrom, но для упрощения здесь не выделяется особый случай.
«UNIX Network Programming»
В серии «UNIX Network Programming» приведена трактовка TCP/IP для прикладных программистов. Здесь рассматриваются не сами протоколы, а их применение для построения сетевых приложений.
Том 1. Сетевые API: Сокеты и XTI
Эта книга должна быть у каждого сетевого программиста. В ней очень подробно рассматривается программирование TCP/IP с помощью API сокетов и XTI. Помимо традиционных тем, обсуждаемых в изданиях по программированию в архитектуре клиент-сервер, в данной книге затрагиваются групповое вещание, маршрутизирующие сокеты, неблокирующий ввод/вывод, протокол IPv6 и его работу совместно с IPv4, простые сокеты, программирование на канальном уровне и сокета в адресном домене UNIX.
В этом томе есть особенно ценная глава, в которой сравниваются различные модели построения клиентов и серверов. В приложениях описываются виртуальные сети и техника отладки.
Том 2: Межпроцессное взаимодействие
Во втором томе детально рассмотрены различные механизмы межпроцессного взаимодействия. Помимо таких традиционных средств, как каналы и FIFO в UNIX, очереди сообщений, семафоры и разделяемая память, впервые появившиеся в системе SysV, обсуждаются и более современные методы межпроцессного взаимодействия, предложенные в стандарте POSIX.
Имеется прекрасное введение в изучение стандартизованных POSIX-потоков (threads) и использования в них таких примитивов синхронизации, как мьютексы, условные переменные и блокировки чтения-записи. Для тех, кто интересуется работой системных механизмов, Стивенс приводит реализацию нескольких примитивов синхронизации и очередей сообщений в стандарте POSIX.
Заканчивается книга главами об RPC (Remote Procedure Calls - вызовы удаленных процедур) и подсистеме Solaris Doors.
Был запланирован и третий том, в котором предполагалось рассмотреть приложения, но, к несчастью, Стивене скончался, не успев его завершить. Частично материал, который он хотел включить в третий том, можно найти в первом издании книги «UNIX Network Programming» [Stevens 1990].
| | |
Вещание на подсеть
В адресе для вещания на все подсети идентификаторы сети и подсети определяют соответствующие адреса, а идентификатор хоста состоит из одних единиц. Не зная маски подсети, невозможно определить, является ли данный адрес адресом для вещания на подсеть. Например, адрес 190.50.1.255 можно трактовать как адрес для вещания на подсеть только при условии, если маршрутизатор имеет информацию, что маска подсети равна 255.255.255.0. Если же известно, что маска подсети равна 255.255.0.0, то это адрес не считается широковещательным.
При использовании бесклассовой междоменной маршрутизации (CIDR), которая будет рассмотрена ниже, широковещательный адрес этого типа такой же, как и адрес вещания на сеть; RFC 1812 предлагает трактовать их одинаково.
Вещание на сеть
В адресе для вещания на сеть идентификатор сети определяет адрес этой сети, а идентификатор хоста состоит из одних единиц. Например, для вещания на сет 190.50.0.0 используется адрес 190.50.255.255. Датаграммы, посылаемые на такой адрес, доставляются всем хостам указанной сети.
Требования к машрутизаторам (RFC 1812) [Baker 1995] предусматривают по умолчанию пропуск маршрутизатором сообщений, вещаемых на сеть, но эту возможность можно отключить. Во избежание атак типа «отказ от обслуживания» (denial of service), которые используют возможности, предоставляемые направленным широковещанием, во многих маршрутизаторах пропуск таких датаграмм, скорее всего, будет заблокирован.
Вещание на все подсети
В адресе для вещания на все подсети задан идентификатор сети, а адреса подсети и хоста состоят из одних единиц. Как и при вещании на подсеть, для опознания такого адреса необходимо знать маску подсети.
К сожалению, применение адреса для вещания на все подсети сопряжено с н которыми проблемами, поэтому этот режим не внедрен. При использовали CIDR этот вид широковещания не нужен и, по RFC 1812, «отправлен на свалку истории».
Ни один из описанных широковещательных адресов нельзя использовать в качестве адреса источника IP-датаграммы. И, наконец, следует отметить, что в некоторых ранних реализациях TCP/IP, например в системе 4.2BSD, для выделения широковещательного адреса в поле идентификатора хоста ставились не единицы, а нули.
Вспомогательный код для UNIX
Заголовочный файл etcp.h
Почти все программы в этой книге начинаются с заголовочного файла etcp. h (листинг П1.1). Он подключает и другие необходимые файлы, в том числе skel. h (листинг П2.1), а также определения некоторых констант, типов данных и прото-типов.
Листинг П1.1. Заголовочный файл etcp, h
1 #ifndef _ETCP_H_
2 #define _ЕТСР_Н_
3 /* Включаем стандартные заголовки. */
4 #include <errno.h>
5 #include <stdlib.h>
6 #include <unistd.h>
7 #include <stdio.h>
8 #include <stdarg.h>
9 #include <string.h>
10 #include <netdb.h>
11 #include <signal.h>
12 #include <fcntl.h>
13 #include <sys/socket.h>
14 #include <sys/wait.h>
15 #include <sys/time.h>
16 #include <sys/resource.h>
17 #include <sys/stat.h>
18 #include <netinet/in.h>
19 #include <arpa/inet.h>
20 #include "skel.h"
21 #define TRUE 1
22 #define FALSE 0
23 #define NLISTEN 5 /* Максимальное число ожидающих соединений. */
24 #define NSMB 5 /* Число буферов в разделяемой памяти. */
25 #tdefine SMBUFSZ256/* Размер буфера в разделяемой памяти. */
26 extern char *program_name; /* Для сообщений об ошибках. */
27 #ifdef _SVR4
28 #define bzero(b,n) memset( ( b ), 0, ( n ) )
29 #endif
30 typedef void ( *tofunc_t ) ( void * ) ;
31 void error( int, int, char*, ... );
32 int readn( SOCKET, char *, size_t );
33 int readvrect SOCKET, char *, size_t ) ;
34 int readcrlf( SOCKET, char *, size_t ) ;
35 int readline( SOCKET, char *, size_t ) ;
36 int tcp_server( char *, char * };
37 int tcp_client ( char *, char * ) ;
38 int udp_server ( char *, char * } ;
39 int udp_client( char *, char *, struct sockaddr_in * );
40яяяяяяя int tselect( int, fd_set *, fd_set *, fd_set *);
41яяяяяяя unsigned int timeout( tofunc_t, void *, int );
42яяяяяяя void untimeout( unsigned int );
43яяяяяяя void init_smb( int ) ;
44яяяяяяя void *smballoc( void ) ;
45яяяяяяя void smbfree( void * ) ;
46яяяяяяя void smbsendf SOCKET, void * );
47яяяяяяя void *smbrecv( SOCKET ) ;
48яяяяяяя void set_address ( char *, char *, struct sockaddr_in *', char *яяяяяяяяяя ) ;
49яяяяяяя #endifя /* _ETCP_H_ */
”гЄжЁп daemon
”гЄжЁп daemon, Є®в®а п ЁбЇ®«м§®ў ў Їа®Ја ¬¬Ґ tcpmux, ўе®¤Ёв ў бв ¤ авго ЎЁЎ«Ё®вҐЄг, Ї®бв ў«пҐ¬го б бЁб⥬®© BSD. „«п бЁб⥬ SVR4 ЇаЁў®¤Ёвбп ўҐабЁп, ⥪бв Є®в®а®© Ї®Є § ў «ЁбвЁЈҐ Џ1.2.
‹ЁбвЁЈ Џ1.2. ”гЄжЁп daemon
daemon.б
1яяяяяя int daemon( int nocd, int noclose )
2яяяяяяяяя (
3яяяяяя struct rlimit rlim;
4яяяяяя pid_t pid;
5яяяяяя int i;
6яяяяяя mask( 0 );яяя /* ЋзЁбвЁвм ¬ бЄг ᮧ¤ Ёп д ©«®ў. */
7яяяяяя /* Џ®«гзЁвм ¬ ЄбЁ¬ «м®Ґ зЁб«® ®вЄалвле д ©«®ў. */
8яяяяяя if ( getrlimit( RLIMIT_NOFILE, &rlim ) < 0 )
9яяяяяяяяяяяяяяя error( 1, errno, "getrlimit failed" );
10яяяя /* ‘в вм «Ё¤Ґа®¬ бҐббЁЁ, Ї®вҐапў ЇаЁ н⮬ гЇа ў«пойЁ© вҐа¬Ё «... */
11яяяя pid = fork();
12яяяя if ( pid < 0 )
13яяяяяяяяяяяяя return -1;
14яяяя if ( pid != 0 )
15яяяяяяяяяяяяя exit( 0 ) ;
16яяяя setsid();
17яяяя /* ... Ё Ј а вЁа®ў вм, зв® Ў®«миҐ ҐЈ® Ґ Ўг¤Ґв. */
18яяяя signal( SIGHUP, SIG_IGN );
19яяяя pid = fork(};
20яяяя if ( pid < 0 )
21яяяяяяяяяяяяя return -1;
22яяяя if ( pid != 0 )
23яяяяяяяяяяяяя exit( 0 );
24яяяя * ‘¤Ґ« вм ⥪гйЁ¬ Є®аҐў®© Є в «®Ј, ҐҐ «Ё Ґ вॡ®ў «®бм ®Ўа ⮥ */
25яяяя if ( !nocd )
26яяяяяяяяяяяяя chdir( "/" ) ;
27яяяя /*
28яяяя * …б«Ё б Ґ Їа®бЁ«Ё нв®Ј® Ґ ¤Ґ« вм, § Єалвм ўбҐ д ©«л.
29яяяя * ‡ ⥬ ЇҐаҐ Їа ўЁвм stdin, stdout Ё stderr
30яяяя * /dev/null.
31яяяя */
32яяяя if (!noclose }
33яяяя {
34яяяя #if 0 /* ‡ ¬ҐЁвм 1 ¤«п § ЄалвЁп ўбҐе д ©«®ў. */
35яяяя if ( rlim.rlim_max == RLIM_INFINITY )
3яяяяяяяяяяяяяяя rlim.rlim_max = 1024;
37яяяя for ( i = 0; i < rlim.rlim_max; i++ )
38яяяяяяяяяяяяя close( i );
39яяяя endif
40яяяя i = open( "/dev/null", 0_RDWR );
41яяяя f ( i < 0 )
42яяяяяяяяяяяяя return -1;
43яяяя up2( i, 0 ) ;
44яяяя up2( i, 1 };
45яяяя up2( i, 2 );
46яяяя f ( i > 2 )
47яяяяяяяяяяяяя close( i ) ;
48яяяя }
49яяяя return 0;
50яяяя }
”гЄжЁп signal
‚ нв®© ЄЁЈҐ 㦥 гЇ®¬Ё «®бм, зв® ў ҐЄ®в®але ўҐабЁпе UNIX дгЄжЁп s ignal ॠ«Ё§®ў ®б®ўҐ ᥬ вЁЄЁ Ґ ¤Ґ¦ле бЁЈ «®ў. ‚ в Є®¬ б«гз Ґ ¤«п Ї®«г票п ᥬ вЁЄЁ ¤Ґ¦ле бЁЈ «®ў б«Ґ¤гҐв ЁбЇ®«м§®ў вм дгЄжЁо sigaction. —в®Ўл Ї®ўлбЁвм ЇҐаҐ®бЁ¬®бвм, Ґ®Ўе®¤Ё¬® ॠ«Ё§®ў вм signal б Ї®¬®ймо sigaction («ЁбвЁЈ Џ1.3)
‹ЁбвЁЈ Џ 1.3. ”гЄжЁп signal
signal. c
/*яя signalяя -я ¤Ґ¦ пя ўҐабЁп ¤«пя SVR4я Ё ҐЄ®в®але ¤агЈЁеяяяяяяя бЁб⥬.яя */
1яяяяяя typedef void sighndlr_t(яя intяя );
2яяяяяя sighndlr_tяя *signal(яя intяя sig,яя sighndlr_tяя *hndlrяя )
3яяяяяя {
4яяяяяяяяяяяяяяя struct sigaction act;
5яяяяяяяяяяяяяяя struct sigaction xact;
6яяяяяяяяяяяяяяя act.sa_handler = hndlr;
7яяяяяяяяяяяяяяя act.sa_flags =0;
8яяяяяяяяяяяяяяя sigemptyset( &act.sa_mask );
9яяяяяяяяяяяяяяя if ( sigaction( sig, &act, &xact ) < 0 )
10яяяяяяяяяяяяяяяяяяя return SIG_ERR;
11яяяяяяяяяяяяя return xact.sa_handler;
12яяяя }
| | |
Вспомогательный код для Windows
Заголовочный файл skel.h
Для компиляции примеров программ на платформе Windows вы можете пользоваться тем же файлом etcp. h, что и для UNIX (листинг П1.1). Вся системно зависимая информация находится в заголовочном файле skel. h, версия которого для Windows приведена в листинге П2.1.
Листинг П2.1. Версия skel.h для Windows
1 #ifndef _SKEL_H_
2 #define _SKEL_H_
3 /* Версия Winsock. */
4 #include <windows.h>
5 #include <winsock2.h>
6 struct timezone
7 {
8 long tz_minuteswest;
9 long tz_dsttime;
10 };
11 typedef unsigned int u_int32_t;
12 #define EMSGSIZE WSAEMSGSIZE
13 #define INITO init ( argv ) ;
14 #define EXIT(s) do { WSACleanup () ; exit ( ( s ) ) ; } \
15 while ( 0 )
16 #define CLOSE (s) if ( closesocket( s ) ) \
17 error( 1, errno, "ошибка вызова close")
18 #define errno ( GetLastError() )
19 #define set_errno(e) SetLastError( ( e ) )
20 #define isvalidsock(s) ( ( s ) != SOCKET_ERROR )
21 #define bzero(b,n) memset ( ( b ), 0, ( n ) )
22 #define sleep(t) Sleep( ( t ) * 1000 )
23 #define WINDOWS
24 #endif /* _SKEL_H_ */
Выходная информация, формируемая tcpdump
Информация, выдаваемая программой tcpdump, зависит от протокола. Рассмотрим несколько примеров, которые помогут составить представление о том, что можно получить от tcpdump для наиболее распространенных протоколов. Документация, поставляемая вместе с программой, содержит исчерпывающие сведения о формате выдачи.
Первый пример - это трассировка сеанса по протоколу SMTP (Simple Mail Transfer Protocol - простой протокол электронной почты), то есть процедура отправки электронного письма. Распечатка на рис. 4.6 в точности соответствует выдаче tcpdump, только добавлены номера строк, напечатанные курсивом, удалено имя домена хоста bsd и перенесены длинные строки, не уместившиеся на странице.
Для получения трассировки послано письмо пользователю с адресом в домен gte. net. Таким образом, адрес имел вид user@gte.net.
Строки 1-4 относятся к поиску адреса SMTP-сервера, обслуживающего домен gte. net. Это пример выдачи, генерируемой tcpdump для запросов и ответов сервиса DNS. В строке 1 bsd запрашивает у сервера имен своего сервис-провайдера (nsl. ix.netcom.com) имя или имена почтового сервера gte.net. В первом находится временной штамп пакета (12:54:32.920881). Поскольку разрешающая способность таймера на машине bsd составляет 1 мкс, показано шесть десятичных знаков. Вы видите, что пакет ушел из порта 1067 на bsd в порт 53 (domain) на машине nsl. Далее, дается информация о данных в пакете. Первое поле (45801) -
1 12:54:32.920881 bsd.1067 > nsl.ix.netcom.com.domain:
45801+ MX? gte.net. (25)
2 12:54:33.254981 nsl.ix.netcom.com.domain > bsd.1067:
45801 5/4/9 (371) (DF)
3 12:54:33.256127 bsd.1068 > nsl.ix.netcom.com.domain:
45802+ A? mtapop2.gte.net. (33)
4 12:54:33.534962 nsl.ix.netcom.com.domain > bsd.1068:
45802 1/4/4 (202) (DF)
5 12:54:33.535737 bsd.1059 > mtapop2.gte.net.smtp:
S 585494507:585494507(0) win 16384
<mss 1460,nop,wscale 0,nop,nop,
timestamp 6112 0> (DF)
6 12:54:33.784963 mtapop2.gte.net.smtp > bsd.1059:
S1257159392:1257159392(0) ack 585494509 win 49152
<mss 1460,nop,wscale 0,nop,nop,
timestamp 7853753 6112> (DF)
7 12:54:33.785012 bsd.1059 > mtapop2.gte.net.smtp:
.ack 1 win 17376 <nop,nop,
timestamp 6112 7853753> (DF)
8 12:54:34.235066 mtapop2.gte.net.smtp > bsd.1059:
P 1:109(108) ack 1 win 49152
<nop,nop,timestamp 7853754 6112> (DF)
9 12:54:34.235277 bsd.1059 > mtapop2.gte.net.smtp:
P 1:19(10) ack 109 win 17376
<nop,nop,timestamp 6113 7853754> (DF)
14 строк опущено
24 12:54:36.675105 bsd.1059 > mtapop2.gte.net.smtp:
F 663:663(0) ack 486 3win 17376
<nop,nop,timestamp 6118 7853758> (DF)
25 12:54:36.685080 mtapop2.gte.net.smtp > bsd.1059:
F 486:486(0) ack 663 win 49152
<nop,nop,timestamp 7853758 6117> (DF)
26 12:54:36.685126 bsd.1059 > mtapop2.gte.net.smtp:
. ack 487 win 17376
<nop,nop,timestamp 6118 7853758> (DF)
27 12:54:36.934985 mtapop2.gte3.net.smtp > bsd.1059:
F 486:486(0) ack 664 win 49152
<nop,nop,timestamp 7853759 6118> (DF)
28 12:54:36.935020 bsd.1059 > mtapop2.gte.net.smtp:
. ack 487 win 17376
<nop,nop,timestamp 6118 7853759> (DF)
Рис. 4.6. Трассировка SMTP-сеанса с включением обмена по протоколам DNS и TCP
Это номер запроса, используемый функциями разрешения имен на bsd для сопоставления ответов с запросами. Знак «+» означает, что функция разрешения задает опрос DNS-сервером других серверов, если у него нет информации об ответе. Строка «MX?» показывает, что это запрос о записи почтового обмена для сети, имя которой стоит в следующем поле (gte.net). Строка «(25)» свидетельствует о том, что длина запроса - 25 байт.
Строка 2 - это ответ на запрос в строке 1. Число 45801 - это номер запроса, к которому относится ответ. Следующие три поля, разделенные косой чертой, - количество записей в ответе, записей от сервера имен (полномочного агента) и прочих записей. Строка «(371)» показывает, что ответ содержит 371 байт. И, наконец, строка «(DF)» означает, что в IP-заголовке ответа был поднят бит «Don't fragment» (не фрагментировать). Итак, эти две строки иллюстрируют использование системы DNS для поиска обработчиков почты (об этом кратко упоминалось в совете 29).
Если в двух первых строках было выяснено имя обработчика почты для сети gte.net, то в двух последующих выясняется его программа tcpdump IP-адрес. «А?» в строке 3 указывает, что это запрос IP-адреса хоста mtapop2.gte.net - одного из почтовых серверов компании GTE.
Строки 5-28 содержат детали обмена по протоколу SMTP. Процедура трехстороннего квитирования между хостами bsd и mtapop2 начинается в строке 5 и заканчивается строкой 7. Первое поле после временного штампа и имен хостов - это поле flags. «S» в строке 5 указывает, что в сегменте установлен флаг SYN. Другие возможные значения флага: «F» (FIN), «U» (URG), «P» (PUSH), «R» (RST) и «.» (нет флагов). Далее идут порядковые номера первого и последнего байтов, а за ними в скобках - число байтов данных. Эти поля могут вызвать некоторое недоумение, так как «порядковый номер последнего» - это первый неиспользованный порядковый номер, но только в том случае, когда в пакете есть данные. Удобнее всего считать, что первое число - это порядковый номер первого байта в сегменте (SYN или информационном), а второе - порядковый номер первого байта плюс число байтов данных в сегменте. Следует отметить, что по умолчанию показываются реальные порядковые номера для SYN-сегментов и смещения - для последующих сегментов (так удобнее следить). Это поведение можно изменить с помощью опции - S в командной строке.
Во всех сегментах, кроме первого SYN, имеется поле АСК, показывающее, какой следующий порядковый номер ожидает отправитель. Это поле (в виде ack nnn), как и раньше, по умолчанию содержит смещение относительно порядкового номера, указанного в сегменте SYN.
За полем АСК идет поле window. Это количество байтов данных, которое готов принять удаленный хост. Обычно оно отражает объем свободной памяти в буферах соединения.
И, наконец, в угловых скобках указаны опции TCP. Основные опции рассматриваются в RFC 793 [Postel 1981b] и RFC 1323 [Jacobson et al. 1992]. Они обсуждаются также в книге [Stevens 1994], а их полный перечень можно найти на Web-странице http://www.isi.edu/in-notes/iana/assignments/tcp-parameters.
В строках 8- 23 показан диалог между программой sendmail на bsd и SMTP сервером на машине mtapop2. Большая часть этих строк опущена. Строки 24-28 отражают процедуру разрыва соединения. Сначала bsd посылает FIN в строке 24 затем приходит FIN от mtapop2 (строка 25). Заметьте, что в строке 27 mtapop повторно посылает FIN. Это говорит о том, что хост не получил от bsd подтверждения АСК на свой первый FIN, и еще раз подчеркивает важность состояния ТIME-WAIT (совет 22).
Теперь посмотрим, что происходит при обмене UDP-датаграммами. С помощью клиента udphelloc (совет 4) следует послать один нулевой байт в порт сервера времени дня в домене netсоm.com:
bsd: $ udphelloc netcom4.netcom.com daytime
Thu Sep 16 15:11:49 1999
bsd: $
Хост netcom4 возвращает дату и время в UDP-датаграмме. Программа tcpdump печатает следующее:
18:12:23.130009 bsd.1127 > nectom4.netcom.com.daytime: udp 1
18:12:23.389284 nectom4.netcom.com.daytime > bsd.1127: udp 26
Отсюда видно, что bsd послал netcom4 UDP-датаграмму длиной один байт, a netcom4 ответил датаграммой длиной 26 байт.
Протокол обмена ICMP-пакетами аналогичен. Ниже приведена трассировка одного запроса, генерируемого программой ping с хоста bsd на хост netcom4:
1 06:21:28.690390 bsd > netcom4.netcom.com: icmp: echo request
2 06:21:29.400433 netcom4.netcom.com > bsd: icmp: echo reply
Строка icmp: означает, что это ICMP-датаграмма, а следующий за ней текст описывает тип этой датаграммы.
Один из недостатков tcpdump - это неполная поддержка вывода собственно данных. Часто во время отладки сетевых приложений необходимо знать, какие данные посылаются. Эту информацию можно получить, задав в командной строке опции -s и -х, но данные будут выведены только в шестнадцатеричном формате. Опция -х показывает, что содержимое пакета нужно выводить в шестнадцатеричном виде. Опция -s сообщает, сколько данных из пакета выводить. По умолчанию tcpdump выводит только первые 68 байт (в системе SunOS NIT - 96 байт). Этого достаточно для заголовков большинства протоколов. Повторим предыдущий пример, касающийся UDP, но здесь нужно выводить также следующие данные:
tcpdump -х -s 100 -l
После удаления строк, относящихся к DNS, и исключения имени домена из адреса хоста bsd получается следующий результат:
1 12:57:53.299924 bsd.1053 > netcom4.netcom.com.daytime: udp 1
4500 001d 03d4 0000 4011 17al c7b7 c684
c7b7 0968 041d 000d 0009 9c56 00
2 12:57:53.558921 netcom4.netcom.com.daytime > bsd.1053: udp 26
4500 0036 f0c8 0000 3611 3493 c7b7 0968
c7b7 c684 000d 041d 0022 765a 5375 6e20
5365 7020 3139 2030 393a 3537 3a34 3220
3139 3939 0a0d
Последний байт в первом пакете - это нулевой байт, который udphelloc посылает хосту netcom4. Последние 26 байт второго пакета - это полученный ответ. Интерпретировать приведенные в нем шестнадцатеричные цифры довольно трудно.
Авторы tcpdump не хотели давать ASCII-представление данных, так как полагали, что это упростит кражу паролей для технически неподготовленных лиц. Теперь многие считают, что широкое распространение программ для кражи паролей сделало это опасение неактуальным. Поэтому есть основания полагать, что в последующие версии tcpdump будет включена поддержка вывода в коде ASCII*.(* Начиная с версии 3.5 tcpdump позволяет выводить и ASCII-представление. Для этого надо одновременно указать опции -X и -х. - Прим. автора.)
А пока многие сетевые программисты упражняются в написании фильтр, преобразующих выдачу tcpdump в код ASCII. Несколько подобных программ есть в Internet. Показанный в листинге 4.1 сценарий Perl запускает tcpdump, перенаправляет ее вывод к себе и перекодирует данные в ASCII.
Листинг 4.1. Perl-сценарий для фильтрации выдачи tcpdump
1 #! /usr/bin/perl5
2 $tcpdump = "/usr/sbin/tcpdump";
3 open( TCPD, "$tcpdump 8ARGV |" )
4 die "не могу запустить tcpdump: \$!\\n";
5 $| = 1;
6 while ( <TCPD> )
7 {
8 if ( /^\t/ }
9 {
10 chop;
11 $str = $_;
12 $str =~ tr / \t//d;
13 $str = pack "H*" , $str;
14 $str =~ tr/\x0-\xlf\x7f-\xff/./;
15 printf "\t%-40s\t%s\n", substr( $_, 4 ), $str;
16 }
17 else
18 {
19 print;
20 }
21 }
Если еще раз прогнать последний пример, но вместо tcpdump использоват tcpd, то получится следующее:
1 12:58:56.428052 bsd.1056 > netcom4.netcom.com.daytime: udp 1
4500 OOld 03d7 0000 4011 179e c7b7 c684 E.......@....
c7b7 0968 041d OOOd 0009 9c56 00 ..-h......S.
2 12:58:56.717128 netcom4.netcom.com.daytime > bsd.1053: udp 26
4500 0036 lOfl 0000 3611 146b c7b7 0968 E..6....6..k..h
c7b7 c684 OOOd 0420 0022 7656 5375 6e20 ......."rVSun
5365 7020 3139 2030 393a 3538 3a34 3620 Sep 19 09:58:46
3139 3939 OaOd 1999..
Вызов shutdown
Как приложение закрывает свой конец соединения? Оно не может просто завершить сеанс или закрыть сокет, поскольку у партнера могут быть еще данные. " API сокетов есть интерфейс shutdown. Он используется так же, как и вызов close, но при этом передается дополнительный параметр, означающий, какую сторону соединения надо закрыть.
#include <sys/socket.h> /* UNIX. */
#include <winsock2.h> /* Windows. */
int shutdown( int s, int how ); /* UNIX. */
int shutdown( SOCKET s, int how ); /* Windows. */
Возвращаемое значение: 0- нормально, -1 (UNIX) или SOCKET_ERROR (Windows) - ошибка.
К сожалению, между реализациями shutdown в UNIX и Windows есть различия в семантике и API. Традиционно в качестве значений параметра how вызова shutdown использовались числа. И в стандарте POSIX, и в спецификации Winsock им присвоены символические имена, только разные. В табл. 3.1 приведены значения, символические константы для них и семантика параметра how.
Различия в символических именах можно легко компенсировать, определив в заголовочном файле одни константы через другие или используя числовые значения. А вот семантические отличия гораздо серьезнее. Посмотрим, для чего предназначено каждое значение.
Таблица 3.1. Значения параметра how для вызова shutdown
| Числовое | Значение how | Действие | |||||
| POSIX | WINSOCK | ||||||
| 0 | SHUT_RD | SD_RECEIVE | Закрывается принимающая сторона соединения | ||||
| 1 | SHUT_WR | SD_SEND | Закрывается передающая сторона соединения | ||||
| 2 | SHUT_RDWR | SD_BOTH | Закрываются обе стороны |
how = 0. Закрывается принимающая сторона соединения. В обеих реализациях в сокете делается пометка, что он больше не может принимать данные и должен вернуть EOF, если приложением делаются попытки еще что-то читать. Но отношение к данным, уже находившимся в очереди приложения в момент выполнения shutdown, а также к приему новых данных от хоста на другом конце различное. В UNIX все ранее принятые, но еще не прочитанные данные уничтожаются, так что приложение их уже не получит. Если поступают новые данные, то TCP их подтверждает и тут же отбрасывает, поскольку приложение не хочет принимать новые данные. Наоборот, в соответствии с Winsock соединение вообще разрывается, если в очереди есть еще данные или поступают новые Поэтому некоторые авторы (например, [Quinn and Shute 1996]) считают, что под Windows использование конструкции
shutdown (s, 0) ;
небезопасно.
how = 1. Закрывается отправляющая сторона соединения. В сокете делается пометка, что данные посылаться больше не будут; все последующие пытки выполнить для него операцию записи заканчиваются ошибкой. После того как вся информация из буфера отправлена, TCP посылает сегмент FIN, сообщая партнеру, что данных больше не будет. Это называется полузакрытием (half close). Такое использование вызова shutdown наиболее типично, и его семантика в обеих реализациях одинакова.
how = 2. Закрываются обе стороны соединения. Эффект такой же, как при выполнении вызова shutdown дважды, один раз с how = 0, а другой - с how = 1. Хотя, на первый взгляд, обращение
shutdown (s, 2);
эквивалентно вызову close или closesocket, в действительности это не так. Обычно нет причин для вызова shutdown с параметром how = 2, но в работе [Quinn and Shute 1996] сообщается, что в некоторых реализациях Winsock вызов closesocket работает неправильно, если предварительно не было обращения к shutdown с how = 2. В соответствии с Winsock вызов shutdown с how= 2 создает ту же проблему, что и вызов с how = 0, - может быть разорвано соединение.
Между закрытием сокета и вызовом shutdown есть существенные различия. Во-первых, shutdown не закрывает сокет по-настоящему, даже если он вызван с параметром 2. Иными словами, ни сокет, ни ассоциированные с ним ресурсы (за исключением буфера приема, если how= 0 или 2) не освобождаются. Кроме того, воздействие shutdown распространяется на все процессы, в которых этот сокет открыт. Так, например, вызов shutdown с параметром how = 1 делает невозможной запись в этот сокет для всех его владельцев. При вызове же с lose или closesocket все остальные процессы могут продолжать пользоваться сокетом.
Последний факт во многих случаях можно обратить на пользу. Вызывая shutdown c how = 1, будьте уверены, что партнер получит EOF, даже если этот сокет открыт и другими процессами. При вызове close или closesocket это не гарантируется, поскольку TCP не пошлет FIN, пока счетчик ссылок на сокет не станет равным нулю. А это произойдет только тогда, когда все процессы закроют этот сокет.
Наконец, стоит упомянуть, что, хотя в этом разделе говорится о TCP, вызов shutdown применим и к UDP. Поскольку нет соединения, которое можно закрыть, польза обращения к shutdown с how = 1 или 2, остается под вопросом, но задавать параметр how - 0 можно для предотвращения приема датаграмм из конкретного UDP-порта.
Зачем нужно состояние TIME- WAIT
Состояние TIME-WAIT служит двум целям:
не дать соединению пропасть при потере последнего АСК, посланного активной стороной, в результате чего другая сторона повторно посылает FIN;
дать время исчезнуть «заблудившимся сегментам», принадлежащим этому соединению.
Рассмотрим каждую из этих причин. В момент, когда сторона, выполняющая активное закрытие, готова подтвердить посланный другой стороной FIN, все данные, отправленные другой стороной, уже получены. Однако последний АСК может потеряться. Если это произойдет, то сторона, выполняющая пассивное закрытие, обнаружит тайм-аут и пошлет свой FIN повторно (так как не получила АСК на последний порядковый номер).
А теперь посмотрим, что случится, если активная сторона не перейдет в состояние TIME-WAIT, а просто закроет соединение. Когда прибывает повторно переданный FIN, у TCP уже нет информации о соединении, поэтому он посылает в ответ RST (сброс), что для другой стороны служит признаком ошибки, а не нормального закрытия соединения. Но, так как сторона, пославшая последний АСК, все-таки перешла в состояние TIME-WAIT, информация о соединении еще хранится, так что она может корректно ответить на повторно отправленный FIN.
Этим объясняется и то, почему 2МSL-таймер перезапускается, если в состоянии TIME-WAIT приходит новый сегмент. Если последний АСК потерян, и другая сторона повторно послала FIN, то сторона, находящаяся в состоянии TIME-WAIT, еще раз подтвердит его и перезапустит таймер на случай, если и этот АСК будет потерян.
Второе назначение состояния TIME-WAIT более важно. Поскольку IР-дата-граммы могут теряться или задерживаться в глобальной сети, TCP использует механизм подтверждений для своевременной повторной передачи неподтвержденных сегментов (совет 1). Если датаграмма просто задержалась в пути, но не потеряна, или потерян подтверждающий ее сегмент АСК, то после прибытия исходных данных могут поступить также и повторно переданные. TCP в этом случае определяет, что порядковые номера поступивших данных находятся вне текущего окна приема, и отбрасывает их.
А что случится, если задержавшийся или повторно переданный сегмент придет после закрытия соединения? Обычно это не проблема, так как TCP просто отбросит данные и пошлет RST. Когда RST дойдет до хоста, отправившего задержавшийся сегмент, то также будет отброшен, поскольку у этого хоста больше нет информации о соединении. Однако если между этими двумя хостами установлено новое соединение с такими же номерами портов, что и раньше, то заблудившийся сегмент может быть принят как принадлежащий новому соединению. Если порядковые номера данных в заблудившемся сегменте попадают в текущее окно приема нового соединения, то данные будут приняты, следовательно, новое соединение - скомпрометировано.
Состояние TIME-WAIT предотвращает такую ситуацию, гарантируя, что два прежних сокета (два IP-адреса и соответствующие им номера портов) повторно не используются, пока все сегменты, оставшиеся от старого соединения, не будут уничтожены. Таким образом, вы видите, что состояние TIME-WAIT играет важную роль в обеспечении надежности протокола TCP. Без него TCP не мог бы гарантировать доставку данных по порядку и без искажений (совет 9).
Запись со сбором
Как видите, существуют приложения, которые, действительно, должны отключать алгоритм Нейгла, но в основном это делается из-за проблем с производительностью, причина которых в отправке логически связанных данных серией из Дельных операций записи. Есть много способов собрать данные, чтобы послать вместе. Наконец всегда можно скопировать различные порции данных в один буфер, которые потом и передать операции записи. Но, как объясняется в совете 26 к такому методу следует прибегать в крайнем случае. Иногда можно организовать хранение данных в одном месте, как и сделано в листинге 2.15. Чаще однако иные находятся в нескольких несмежных буферах, а хотелось бы послать их одной операцией записи.
Для этого и в UNIX, и в Winsock предусмотрен некоторый способ. К сожалению, эти способы немного отличаются. В UNIX есть системный вызов writev и парный ему вызов readv. При использовании writev вы задаете список буферов, из которых должны собираться данные. Это решает исходную задачу: можно размещать данные в нескольких буферах, а записывать их одной операцией, исключив тем самым интерференцию между алгоритмами Нейгла и отложенного подтверждения.
#include <sys/uio.h>
ssize_t writev (int fd, const struct iovec *iov, int cnt);
ssize_t readv(int fd, const struct iovec *iov, int cnt);
Возвращаемое значение: число переданных байт или -1 в случае ошибки.
Параметр iov- это указатель на массив структур iovec, в которых хранятся указатели на буферы данных и размеры этих буферов:
struct iovec {
char *iov_base; /* Адрес начала буфера. */
size_t iov_len; /* Длина буфера. */
};
Примечание: Это определение взято из системы FreeBSD. Теперь во многих системах адрес начала буфера определяется так:
void *iov_base; /* адрес начала буфера */
Третий параметр, cnt - это число структур iovec в массиве (иными словами, количество буферов).
У вызовов writev и readv практически общий интерфейс. Их можно использовать для любых файловых дескрипторов, а не только для сокетов.
Чтобы это понять, следует переписать клиент (листинг 3.23), работающий с записями переменной длины (листинг 2.15), с использованием writev.
Листинг 3.23. Клиент, посылающий записи переменной длины с помощью writev
1 #include "etcp.h"
2 #include <sys/uio.h>
3 int main( int argc, char **argv)
4 {
5 SOCKET s;
6 int n;
7 char buf[128];
8 struct iovec iov[ 2 ];
9 INIT();
10 s = tcp_client( argv[ 1 ], argv[ 2 ] ) ;
11 iov[ 0 ].iov_base = ( char * )&n;
12 iov[ 0 ].iov_len = sizeof( n ) ;
13 iov[ 1 ].iov_base = buf;
14 while ( fgets( buf, sizeof( buf ), stdin ) != NULL )
15 {
16 iov[ 1 ].iov_len = strlent buf );
17 n = htonl ( iov[ 1 ].iov_len ) ;
18 if ( writev( s, iov, 2 ) < 0 )
19 error( 1, errno, "ошибка вызова writev" );
20 }
21 EXIT( 0 ) ;
22 }
Инициализация
9- 13 Выполнив обычную инициализацию клиента, формируем массив iov. Поскольку в прототипе writev имеется спецификатор const для структур, на которые указывает параметр iov, то есть гарантия, что массив iov не будет изменен внутри writev, так что большую часть параметров можно задавать вне цикла while.
Цикл обработки событий
14-20 Вызываем fgets для чтения одной строки из стандартного ввода, вычисляем ее длину и записываем в поле структуры из массива iov. Кроме того, длина преобразуется в сетевой порядок байт и сохраняется в переменной n.
Если запустить сервер vrs (совет 6) и вместе с ним клиента vrcv, то получатся те же результаты, что и раньше.
В спецификации Winsock определен другой, хотя и похожий интерфейс.
#include <winsock2.h>
int WSAAPI WSAsend (SOCKET s, LPWSABUF, DWORD cnt, LPDWORD sent, DWORD flags, LPWSAOVERLAPPED ovl, LPWSAOVERLAPPED_COMPLETION_ROUTINE func );
Возвращаемое значение: 0 в случае успеха, в противном случае SOCKET_ERROR.
Последние два аргумента используются при вводе/выводе с перекрытием, и в данном случае не имеют значения, так что обоим присваивается значение NULL. параметр buf указывает на массив структур типа WSABUF, играющих ту же роль, Что структуры iovec в вызове writev.
typedef struct _WSABUF {
u_longlen; /* Длина буфера. */
char FAR * buf; /* Указатель на начало буфера. */
} WSABUF, FAR * LPWSABUF;
Параметр sent - это указатель на переменную типа DWORD, в которой хранится число переданных байт при успешном завершении вызова. Параметр flags аналогичен одноименному параметру в вызове send.
Версия клиента, посылающего сообщения переменной длины, на платформе Windows выглядит так (листинг 3.24):
Листинг 3.24. Версия vrcv для Winsock
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 SOCKET s;
5 int n;
6 char buf[ 128 ] ;
7 WSABUF wbuf[ 2 ];
8 DWORD sent;
9 INIT();
10 s = tcp_client( argv[ 1 ], argv[ 2 ] ) ;
11 wbuf[ 0 ].buf = ( char * )&n;
12 wbuf[ 0 ].len = sizeof( n );
13 wbuf[ 1 ].buf = buf;
14 while ( fgets( buf, sizeof( buf ), stdin ) != NULL )
15 {
16 wbuff 1 ].len = strlen( buf );
17 n = htonl ( wbuff 1 ].len );
18 if ( WSASend( s, wbuf, 2, &sent, 0, NULL, NULL ) < 0 )
19 error( 1, errno, "ошибка вызова WSASend" );
20 }
21 EXIT( 0 );
22 }
Как видите, если не считать иного обращения к вызову записи со сбором, то Winsock-версия идентична UNIX-версии.
