Формат заголовка IP-дейтаграммы
IP-дейтаграмма состоит из заголовка и данных.
Заголовок дейтаграммы состоит из 32-разрядных слов и имеет переменную длину, зависящую от размера поля “Options”, но всегда кратную 32 битам. За заголовком непосредственно следуют данные, передаваемые в дейтаграмме.
Формат заголовка:

Значения полей заголовка следующие.
Ver (4 бита) - версия протокола IP, в настоящий момент используется версия 4, новые разработки имеют номера версий 6-8.
IHL (Internet Header Length) (4 бита) - длина заголовка в 32-битных словах; диапазон допустимых значений от 5 (минимальная длина заголовка, поле “Options” отсутствует) до 15 (т.е. может быть максимум 40 байт опций).
TOS (Type Of Service) (8 бит) - значение поля определяет приоритет дейтаграммы и желаемый тип маршрутизации. Структура байта TOS:
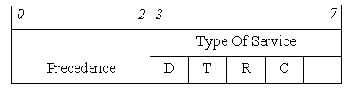
Три младших бита (“Precedence”) определяют приоритет дейтаграммы:
111 - управление сетью
110 - межсетевое управление
101 - CRITIC-ECP
100 - более чем мгновенно
011 - мгновенно
010 - немедленно
001 - срочно
000 - обычно
Биты D,T,R,C определяют желаемый тип маршрутизации:
D (Delay) - выбор маршрута с минимальной задержкой,
T (Throughput) - выбор маршрута с максимальной пропускной способностью,
R (Reliability) - выбор маршрута с максимальной надежностью,
C (Cost) - выбор маршрута с минимальной стоимостью.
В дейтаграмме может быть установлен только один из битов D,T,R,C. Старший бит байта не используется.
Реальный учет приоритетов и выбора маршрута в соответствии со значением байта TOS зависит от маршрутизатора, его программного обеспечения и настроек. Маршрутизатор может поддерживать расчет маршрутов для всех типов TOS, для части или игнорировать TOS вообще. Маршрутизатор может учитывать значение приоритета при обработке всех дейтаграмм или при обработке дейтаграмм, исходящих только из некоторого ограниченного множества узлов сети, или вовсе игнорировать приоритет.
Total Length (16 бит) - длина всей дейтаграммы в октетах, включая заголовок и данные, максимальное значение 65535, минимальное - 21 (заголовок без опций и один октет в поле данных).
ID (Identification) (16 бит), Flags (3 бита), Fragment Offset (13 бит) используются для фрагментации и сборки дейтаграмм и будут подробнее рассмотрены ниже в п. 2.4.1.
TTL (Time To Live) (8 бит) - “время жизни” дейтаграммы. Устанавливается отправителем, измеряется в секундах. Каждый маршрутизатор, через который проходит дейтаграмма, переписывает значение TTL, предварительно вычтя из него время, потраченное на обработку дейтаграммы. Так как в настоящее время скорость обработки данных на маршрутизаторах велика, на одну дейтаграмму тратится обычно меньше секунды, поэтому фактически каждый маршрутизатор вычитает из TTL единицу. При достижении значения TTL=0 дейтаграмма уничтожается, при этом отправителю может быть послано соответствующее ICMP-сообщение. Контроль TTL предотвращает зацикливание дейтаграммы в сети.
Protocol (8 бит) - определяет программу (вышестоящий протокол стека), которой должны быть переданы данные дейтаграммы для дальнейшей обработки. Коды некоторых протоколов приведены в таблице 2.4.1.
Таблица 2.4.1
Коды IP-протоколов
| Код | Протокол | Описание |
| 1 | ICMP |
Протокол контрольных сообщений
Header Checksum (16 бит) - контрольная сумма заголовка, представляет из себя 16 бит, дополняющие биты в сумме всех 16-битовых слов заголовка. Перед вычислением контрольной суммы значение поля “Header Checksum” обнуляется. Поскольку маршрутизаторы изменяют значения некоторых полей заголовка при обработке дейтаграммы (как минимум, поля “TTL”), контрольная сумма каждым маршрутизатором пересчитывается заново. Если при проверке контрольной суммы обнаруживается ошибка, дейтаграмма уничтожается.
Source Address (32 бита) - IP-адрес отправителя.
Destination Address (32 бита) - IP-адрес получателя.
Options - опции, поле переменной длины. Опций может быть одна, несколько или ни одной. Опции определяют дополнительные услуги модуля IP по обработке дейтаграммы, в заголовок которой они включены. Подробнее опции рассматриваются в пп. , .
Padding - выравнивание заголовка по границе 32-битного слова, если список опций занимает нецелое число 32-битных слов. Поле “Padding” заполняется нулями.
Сообщение "Описание базы данных (Database Description)"

Значения полей:
Options(1 октет) - то же, что и в сообщениях Hello.
IMMS (3 бита) - последние 3 бита октета, следующего за полем "Options": I - Initialize, бит 5; M - More, бит 6, MS - Master/Slave, бит 7. Использование этих бит будет описано ниже. Остальная часть октета, где находятся эти биты, обнулена.
DD Sequence number (DDSN) (4 октета) - порядковый номер данного сообщения.
LSA Header (20 октетов) - описание (набор идентификаторов) записи из базы данных состояния связей, представляющее собой заголовок "Объявления о состоянии связей" (см. , формат поля "LSA Header" - в ). В сообщении может присутствовать несколько описаний (полей "LSA Header"), следующих друг за другом; их число определяется из общей длины сообщения, указанной в OSPF заголовке.
Обмен сообщениями "Описание базы данных" происходит при работе протокола обмена (Exchange protocol, см. ) между двумя смежными маршрутизаторами. Обмен начинается с выяснения, кто из двух маршрутизаторов будет играть главную роль, а кто подчиненную.
Маршрутизатор, желающий начать обмен на правах главного, отправляет пустое сообщение с установленными битами IMMS и произвольным, но не использованным в обозримом прошлом номером DDSN (предлагается использовать время суток). Второй маршрутизатор подтверждает, что согласен играть подчиненную роль: он отправляет обратно также пустое сообщение с тем же DDSN, c установленными битами I и M и сброшенным битом MS.
Если же оба маршрутизатора одновременно решили начать процедуру обмена, то маршрутизатор, получивший в ответ на свое сообщение о начале обмена сообщение второго маршрутизатора о начале обмена вместо подтверждения подчиненной роли, сравнивает адрес второго маршрутизатора со своим. Если свой адрес меньше, маршрутизатор принимает подчиненную роль и отправляет соответствующее подтверждение, иначе принятое сообщение игнорируется.
После того, как роли распределены, начинается обмен описаниями базы данных. Главный отправляет подчиненному сообщения с описаниями своей базы данных; номера DDSN увеличиваются с каждым сообщением, бит I сброшен, бит МS установлен, бит M установлен во всех сообщениях, кроме последнего.
Подчиненный отправляет подтверждения на каждое полученное от главного сообщения. Эти подтверждения представляют собой сообщения того же типа, содержащие описание базы данных подчиненного маршрутизатора. Номер DDSN равен номеру подтверждаемого сообщения, биты I и MS сброшены, бит М установлен во всех сообщениях, кроме последнего.
При неполучении подтверждения от подчиненного в течение некоторого тайм-аута главный посылает сообщение повторно. Если подчиненный получает сообщение с уже встречавшимся номером DDSN, он должен повторить передачу соответствующего подтверждения. Это касается также и фазы инициализации (распределения ролей).
Если один из маршрутизаторов уже передал все данные, он продолжает передавать пустые сообщения со сброшенным битом М, пока другая сторона также не закончит передачу всех данных и не передаст сообщение (или подтверждение) со сброшенным битом М.
На этом процедура обмена описаниями базы данных заканчивается.
Значения полей:
Options(1 октет) - то же, что и в сообщениях Hello.
IMMS (3 бита) - последние 3 бита октета, следующего за полем "Options": I - Initialize, бит 5; M - More, бит 6, MS - Master/Slave, бит 7. Использование этих бит будет описано ниже. Остальная часть октета, где находятся эти биты, обнулена.
DD Sequence number (DDSN) (4 октета) - порядковый номер данного сообщения.
LSA Header (20 октетов) - описание (набор идентификаторов) записи из базы данных состояния связей, представляющее собой заголовок "Объявления о состоянии связей" (см. , формат поля "LSA Header" - в ). В сообщении может присутствовать несколько описаний (полей "LSA Header"), следующих друг за другом; их число определяется из общей длины сообщения, указанной в OSPF заголовке.
Обмен сообщениями "Описание базы данных" происходит при работе протокола обмена (Exchange protocol, см. ) между двумя смежными маршрутизаторами. Обмен начинается с выяснения, кто из двух маршрутизаторов будет играть главную роль, а кто подчиненную.
Маршрутизатор, желающий начать обмен на правах главного, отправляет пустое сообщение с установленными битами IMMS и произвольным, но не использованным в обозримом прошлом номером DDSN (предлагается использовать время суток). Второй маршрутизатор подтверждает, что согласен играть подчиненную роль: он отправляет обратно также пустое сообщение с тем же DDSN, c установленными битами I и M и сброшенным битом MS.
Если же оба маршрутизатора одновременно решили начать процедуру обмена, то маршрутизатор, получивший в ответ на свое сообщение о начале обмена сообщение второго маршрутизатора о начале обмена вместо подтверждения подчиненной роли, сравнивает адрес второго маршрутизатора со своим. Если свой адрес меньше, маршрутизатор принимает подчиненную роль и отправляет соответствующее подтверждение, иначе принятое сообщение игнорируется.
После того, как роли распределены, начинается обмен описаниями базы данных. Главный отправляет подчиненному сообщения с описаниями своей базы данных; номера DDSN увеличиваются с каждым сообщением, бит I сброшен, бит МS установлен, бит M установлен во всех сообщениях, кроме последнего.
Подчиненный отправляет подтверждения на каждое полученное от главного сообщения. Эти подтверждения представляют собой сообщения того же типа, содержащие описание базы данных подчиненного маршрутизатора. Номер DDSN равен номеру подтверждаемого сообщения, биты I и MS сброшены, бит М установлен во всех сообщениях, кроме последнего.
При неполучении подтверждения от подчиненного в течение некоторого тайм-аута главный посылает сообщение повторно. Если подчиненный получает сообщение с уже встречавшимся номером DDSN, он должен повторить передачу соответствующего подтверждения. Это касается также и фазы инициализации (распределения ролей).
Если один из маршрутизаторов уже передал все данные, он продолжает передавать пустые сообщения со сброшенным битом М, пока другая сторона также не закончит передачу всех данных и не передаст сообщение (или подтверждение) со сброшенным битом М.
На этом процедура обмена описаниями базы данных заканчивается.
PIM DM
PIM (Protocol Independent Multicast) – два протокола групповой маршрутизации (для плотного и разреженного расположения членов групп, соответственно dense mode и sparse mode), не зависящие от используемого протокола "обычной" маршрутизации.
PIM DM (PIM Dense Mode) используется в системах сетей с большой плотностью получателей. Этот протокол реализует метод RPF с усечением (немодифицированный, то есть без доступа к внутренним таблицам протокола маршрутизации, вследствие чего достигается независимость от протокола маршрутизации). Необходимость периодической посылки "пробных" дейтаграмм не является существенным недостатком при плотном расположении получателей.
При работе протокола PIM DM могут возникнуть две особые ситуации.
Несколько маршрутизаторов подключены к одной широковещательной сети N, которая через вышестоящий маршрутизатор G соединяется с системой сетей, в которой находится отправитель (рис. 8.4.1). В сетях, подключенных к маршрутизаторам В и С, находятся члены группы, а в сети, подключенной к маршрутизатору А – нет.

Рис. 8.4.1. Особая ситуация (1) в PIM DM
Вышестоящий маршрутизатор G посылает в сеть N первую групповую дейтаграмму. Маршрутизатор А откликается сообщением Prune, однако отсекать сеть N от дерева рассылки нельзя, так как есть получатели в сетях В и С. Протокол предлагает следующее решение: маршрутизатор G, получив Prune, запускает таймер. Маршрутизаторы В и С, прослушивая сеть, обнаруживают посланное узлом А Prune, и тут же один из них отправляет сообщение Join (второй, обнаружив в сети Join, не предпринимает никаких действий, поскольку одного такого сообщения достаточно). Маршрутизатор G, приняв Join, игнорирует предыдущий Prune. Если же за определенное время сообщение Join не будет принято, сеть N отрезается от дерева рассылки.
Вторая особая ситуация возникает, когда два маршрутизатора А и В подключены к одной и той же клиентской сети N, в которой находится получатель (рис. 8.4.2).

Рис. 8.4.2. Особая ситуация (2) в PIM DM
Оба маршрутизатора будут отправлять групповые дейтаграммы в сеть N, так как им известно, что в ней находится получатель. Очевидно, что при этом создается избыточный трафик из лишних экземпляров дейтаграмм. Во избежание этого эффекта маршрутизатор (предположим, А), обнаружив, что в сети N действует "конкурирующий" маршрутизатор В, также рассылающий групповые дейтаграммы от источника S в группу G, посылает сообщение Assert, содержащее расстояние от A до S. Конкурирующий узел В, получив это сообщение, сравнивает расстояние от себя до S с указанным в сообщении, и если свое расстояние больше, то соответствующий интерфейс отрезается от дерева с помощью Prune. Аналогичным образом посылается и обрабатывается Assert из В в А. При равных расстояниях побеждает маршрутизатор с большим IP-адресом.
Протокол PIM DM прост в реализации и в настройке; предусмотрено взаимодействие с протоколом DVMRP. В качестве недостатка отметим необходимость рассылать пробные дейтаграммы каждые 3 минуты, так как за это время истекает срок действия сообщения Prune.
Алгоритм построения таблицы маршрутов
В этом разделе для простоты будем называть таблицей маршрутов таблицу, являющуюся результатом деятельности протокола RIP, как описано выше, т.е. состоящую из строк с полями "Сеть", "Расстояние", "Следующий маршрутизатор". Записывать строку в таблице маршрутов будем следующим образом:
А=2a
?
Это означает, что расстояние от данного маршрутизатора до сети А равно 2, а дейтаграммы, следующие в сеть А, надо пересылать маршрутизатору ?.
Вектором расстояний называется набор пар ("Сеть", "Расстояние до этой сети"), извлеченный из таблицы маршрутов. Каждую такую пару мы назовем элементом вектора расстояний. Мы будем записывать вектор расстояний в виде (А=2,В=1): это означает, что расстояние от данного маршрутизатора до сети А равно 2, до сети В- 1.
Расстояние до сети, к которой маршрутизатор подключен непосредственно, примем равным 1.
Каждый маршрутизатор, на котором запущен модуль RIP, периодически широковещательно распространяет свой вектор расстояний. Вектор распространяется через все интерфейсы маршрутизатора, подключенные к сетям, входящим в RIP-систему.
Каждый маршрутизатор также периодически получает векторы расстояний от других маршрутизаторов. Расстояния в этих векторах увеличиваются на 1, после чего сравниваются с данными в таблице маршрутов, и, если расстояние до какой-то из сетей в полученном векторе оказывается меньше расстояния, указанного в таблице, значение из таблицы замещается новым (меньшим) значением, а адрес маршрутизатора, приславшего вектор с этим значением, записывается в поле "Следующий маршрутизатор" в этой строке таблицы. После этого вектор расстояний, рассылаемый данным маршрутизатором, соответственно изменится.
В этом разделе для простоты будем называть таблицей маршрутов таблицу, являющуюся результатом деятельности протокола RIP, как описано выше, т.е. состоящую из строк с полями "Сеть", "Расстояние", "Следующий маршрутизатор". Записывать строку в таблице маршрутов будем следующим образом:
А=2->
(3)
Это означает, что расстояние от данного маршрутизатора до сети А равно 2, а дейтаграммы, следующие в сеть А, надо пересылать маршрутизатору (3).
Вектором расстояний называется набор пар ("Сеть", "Расстояние до этой сети"), извлеченный из таблицы маршрутов. Каждую такую пару мы назовем элементом вектора расстояний. Мы будем записывать вектор расстояний в виде (А=2,В=1): это означает, что расстояние от данного маршрутизатора до сети А равно 2, до сети В- 1.
Расстояние до сети, к которой маршрутизатор подключен непосредственно, примем равным 1.
Каждый маршрутизатор, на котором запущен модуль RIP, периодически широковещательно распространяет свой вектор расстояний. Вектор распространяется через все интерфейсы маршрутизатора, подключенные к сетям, входящим в RIP-систему.
Каждый маршрутизатор также периодически получает векторы расстояний от других маршрутизаторов. Расстояния в этих векторах увеличиваются на 1, после чего сравниваются с данными в таблице маршрутов, и, если расстояние до какой-то из сетей в полученном векторе оказывается меньше расстояния, указанного в таблице, значение из таблицы замещается новым (меньшим) значением, а адрес маршрутизатора, приславшего вектор с этим значением, записывается в поле "Следующий маршрутизатор" в этой строке таблицы. После этого вектор расстояний, рассылаемый данным маршрутизатором, соответственно изменится.
Алгоритм SPF
Алгоритм SPF, основываясь на базе данных состояния связей, вычисляет кратчайшие пути между заданной вершиной S графа и всеми остальными вершинами. Результатом работы алгоритма является таблица, где для каждой вершины V графа указан список ребер, соединяющих заданную вершину S с вершиной V по кратчайшему пути.
Алгоритм SPF был предложен Е.В.Дейкстрой (E.W.Dijkstra).
Пусть
S - заданная вершина (источник путей);
E - множество обработанных вершин, т.е. вершин, кратчайший путь к которым уже найден;
R - множество оставшихся вершин графа (т.е. множество вершин графа за вычетом множества E);
O - упорядоченный список путей.
Описание алгоритма
1. Инициализировать E={S}, R={все вершины графа, кроме S}. Поместить в О все односегментные (длиной в одно ребро) пути, начинающиеся из S, отсортировав их в порядке возрастания метрик.
2. Если О пуст или первый путь в О имеет бесконечную метрику, то отметить все вершины в R как недостижимые и закончить работу алгоритма.
3. Рассмотрим P - кратчайший путь в списке О. Удалить P из О. Пусть V - последний узел в P.
Если V принадлежит E, перейти на шаг 2;
иначе P является кратчайшим путем из S в V (будем записывать как V:P); перенести V из R в E.
4. Построить набор новых путей, подлежащих рассмотрению, путем добавления к пути P всех односегментных путей, начинающихся из V. Метрика каждого нового пути равна сумме метрики P и метрики соответствующего односегментного отрезка, начинающегося из V. Добавить новые пути в упорядоченный список О, поместив их на места в соответствии со значениями метрик. Перейти на шаг 2.
Все вычисления производятся локально по известной базе данных, а потому - быстро по сравнению с дистанционно-векторными протоколами, при этом результаты получаются на основе полной, а не частичной информации о графе системы сетей.
Алгоритм SPF, основываясь на базе данных состояния связей, вычисляет кратчайшие пути между заданной вершиной S графа и всеми остальными вершинами. Результатом работы алгоритма является таблица, где для каждой вершины V графа указан список ребер, соединяющих заданную вершину S с вершиной V по кратчайшему пути.
Алгоритм SPF был предложен Е.В.Дейкстрой (E.W.Dijkstra).
Пусть
S - заданная вершина (источник путей);
E - множество обработанных вершин, т.е. вершин, кратчайший путь к которым уже найден;
R - множество оставшихся вершин графа (т.е. множество вершин графа за вычетом множества E);
O - упорядоченный список путей.
Описание алгоритма
1. Инициализировать E={S}, R={все вершины графа, кроме S}. Поместить в О все односегментные (длиной в одно ребро) пути, начинающиеся из S, отсортировав их в порядке возрастания метрик.
2. Если О пуст или первый путь в О имеет бесконечную метрику, то отметить все вершины в R как недостижимые и закончить работу алгоритма.
3. Рассмотрим P - кратчайший путь в списке О. Удалить P из О. Пусть V - последний узел в P.
Если V принадлежит E, перейти на шаг 2;
иначе P является кратчайшим путем из S в V (будем записывать как V:P); перенести V из R в E.
4. Построить набор новых путей, подлежащих рассмотрению, путем добавления к пути P всех односегментных путей, начинающихся из V. Метрика каждого нового пути равна сумме метрики P и метрики соответствующего односегментного отрезка, начинающегося из V. Добавить новые пути в упорядоченный список О, поместив их на места в соответствии со значениями метрик. Перейти на шаг 2.
Все вычисления производятся локально по известной базе данных, а потому - быстро по сравнению с дистанционно-векторными протоколами, при этом результаты получаются на основе полной, а не частичной информации о графе системы сетей.
Анализ сетевого трафика
Анализ сетевого трафика проводится для обнаружения атак, предпринятых злоумышленниками, находящимися как в сети организации, так и в Интернете.
Сохранять и анализировать статистику работы маршрутизаторов, особенно — частоту срабатывания фильтров. Применять специализированное программное обеспечение для анализа трафика для выявления выполняемых атак (NIDS — Network Intrusion Detection System). Выявлять узлы, занимающие ненормально большую долю полосы пропускания, и другие аномалии в поведении сети. Применять программы типа arpwatch для выявления узлов, использующих нелегальные IP- или MAC-адреса. Применять программы типа Antisniff для выявления узлов, находящихся в режиме прослушивания сети.
ARP для дейтаграмм, направленных в другую сеть
Дейтаграмма, направленная во внешнюю (в другую) сеть, должна быть передана маршрутизатору. Предположим, хост А отправляет дейтаграмму хосту В через маршрутизатор G. Несмотря на то, что в заголовке дейтаграммы, отправляемой из А, в поле “Destination” указан IP-адрес В, кадр Ethernet, содержащий эту дейтаграмму, должен быть доставлен маршрутизатору. Это достигается тем, что IP-модуль при вызове ARP-модуля передает тому вместе с дейтаграммой в качестве IP-адреса узла назначения адрес маршрутизатора, извлеченный из таблицы маршрутов. Таким образом, дейтаграмма с адресом В инкапсулируется в кадр с MAC-адресом G:

Модуль Ethernet на маршрутизаторе G получает из сети этот кадр, так как кадр адресован ему, извлекает из кадра данные (то есть дейтаграмму) и отправляет их для обработки модулю IP. Модуль IP обнаруживает, что дейтаграмма адресована не ему, а хосту В, и по своей таблице маршрутов определяет, куда ее следует переслать. Далее дейтаграмма опять опускается на нижний уровень, к соответствующему физическому интерфейсу, которому передается в качестве IP-адреса узла назначения адрес следующего маршрутизатора, извлеченный из таблицы маршрутов, или сразу адрес хоста В, если маршрутизатор G может доставить дейтаграмму непосредственно к нему.
AS_PATH
AS_PATH (тип 2) – обязательный атрибут, содержащий список автономных систем, через которые должна пройти дейтаграмма на пути в указанную в маршруте сеть. AS_PATH представляет собой чередование сегментов двух типов: AS_SEQUENCE – упорядоченный список АС, и AS_SET – множество АС (последнее может возникнуть при агрегировании нескольких маршрутов со схожими, но не одинаковыми AS_PATH в один общий маршрут).
Каждый BGP-узел при анонсировании маршрута (за исключением IBGP-соединений) добавляет в AS_PATH номер своей АС. Возможно (в зависимости от политики) дополнительно добавляются номера других АС.
Атака крошечными фрагментами (Tiny Fragment Attack)
В случае, когда на вход фильтрующего маршрутизатора поступает фрагментированная датаграмма, маршрутизатор производит досмотр только первого фрагмента датаграммы (первый фрагмент определяется по значению поля IP-заголовка Fragment Offset=0). Если первый фрагмент не удовлетворяет условиям пропуска, он уничтожается. Остальные фрагменты можно безболезненно пропустить, не затрачивая на них вычислительные ресурсы фильтра, поскольку без первого фрагмента датаграмма все равно не может быть собрана на узле назначения.
При конфигурировании фильтра перед сетевым администратором часто стоит задача: разрешить соединения с TCP-сервисами Интернет, инициируемые компьютерами внутренней сети, но запретить установление соединений внутренних компьютеров с внешними по инициативе последних. Для решения поставленной задачи фильтр конфигурируется на запрет пропуска TCP-сегментов, поступающих из внешней сети и имеющих установленный бит SYN в отсутствии бита ACK; сегменты без этого бита беспрепятственно пропускаются в охраняемую сеть, покольку они могут относиться к соединению, уже установленному ранее по инициативе внутреннего компьютера.
Рассмотрим, как злоумышленник может использовать фрагментацию, чтобы обойти это ограничение, то есть, передать SYN-сегмент из внешней сети во внутреннюю.
Злоумышленник формирует искусственно фрагментированную датаграмму с TCP-сегментом, при этом первый фрагмент датаграммы имеет минимальный размер поля данных — 8 октетов (напомним, что размеры фрагментов указываются в 8-октетных блоках). В поле данных датаграммы находится TCP-сегмент, начинающийся с TCP-заголовка. В первых 8 октетах TCP-заголовка находятся номера портов отправителя и получателя и поле Sequence Number, но значения флагов не попадут в первый фрагмент. Следовательно, фильтр пропустит первый фрагмент датаграммы, а остальные фрагменты он проверять не будет. Таким образом, датаграмма с SYN-сегментом будет успешно доставлена на узел назначения и после сборки передана модулю TCP.
На рис. 9.12 пример датаграммы из 2 фрагментов (IP-заголовки выделены серым). В поле данных первого фрагмента находится 8 октетов TCP-заголовка. В поле данных второго фрагмента помещена остальная часть TCP-заголовка с флагом SYN.

Рис. 9.12. Фрагментированный TCP-сегмент
Описанный выше прием проникновения сквозь фильтр называется «Tiny Fragment Attack» (RFC-1858). Использование его в других случаях (для обхода других условий фильтрации) не имеет смысла, так как все остальные «интересные» поля в заголовке TCP и других протоколов находятся в первых 8 октетах заголовка и, следовательно, не могут быть перемещены во второй фрагмент.
Для защиты от этой атаки фильтрующему маршрутизатору, естественно, не следует инспектировать содержимое не первых фрагментов датаграмм — это было бы равносильно сборке датаграмм на промежуточном узле, что быстро поглотит все вычислительные ресурсы маршрутизатора. Достаточно реализовать один из двух следующих подходов:
1) не пропускать датаграммы с Fragment Offset=0 и Protocol=6 (TCP), размер поля данных которых меньше определенной величины, достаточной, чтобы вместить все «интересные поля» (например, 20);
2) не пропускать датаграммы с Fragment Offset=1 и Protocol=6 (TCP): наличие такой датаграммы означает, что TCP-сегмент был фрагментирован с целью скрыть определенные поля заголовка и что где-то существует первый фрагмент с 8 октетами данных. Несмотря на то, что в данном случае первый фрагмент будет пропущен, узел назначения не сможет собрать датаграмму, так как фильтр уничтожил второй фрагмент.
Отметим, что поскольку в реальной жизни никогда не придется фрагментировать датаграмму до минимальной величины, риск потерять легальные датаграммы, применив предложенные выше методы фильтрации, равен нулю.
Второй аспект фрагментации, интересный с точки зрения безопасности, — накладывающиеся (overlapping) фрагменты. Рассмотрим пример датаграммы, несущей TCP-сегмент и состоящей из двух фрагментов (рис. 9.13, IP-заголовок выделен серым цветом). В поле данных первого фрагмента находится полный TCP-заголовок, без опций, дополненный нулями до размера, кратного восьми октетам. В поле данных второго фрагмента — часть другого TCP-заголовка, начиная с девятого по порядку октета, в котором установлен флаг SYN.
Видно, что второй фрагмент накладывается на первый (первый фрагмент содержит октеты 0–23 данных исходной датаграммы, а второй фрагмент начинается с октета 8, потому что его Fragment Offset=1). Поведение узла назначения, получившего такую датаграмму, зависит от реализации модуля IP. Часто при сборке датаграммы данные второго, накладывающегося фрагмента записываются поверх предыдущего фрагмента. Таким образом, при сборке приведенной в примере датаграммы в TCP-заголовке переписываются поля начиная с ACK SN в соответствии со значениями из второго фрагмента, и в итоге получается SYN-сегмент.

Рис. 9.13. Накладывающиеся фрагменты
Если для защиты от Tiny Fragment Attack применяется подход 1) из описанных выше (инспекция первого фрагмента датаграммы), то с помощью накладывающихся фрагментов злоумышленник может обойти эту защиту.
Маршрутизатор, применяющий второй подход, будет успешно противостоять Tiny Fragment Attack с накладывающимися фрагментами.
Атрибуты агрегирования
ATOMIC_AGGREGATE (тип 6) и AGGREGATOR (тип 7)– необязательные атрибуты, связанные с операциями агрегирования (объединения) нескольких маршрутов в один. Для более детального ознакомления с ними отсылаем читателей к документу RFC-1771.
Атрибуты пути (Path Attributes)
Ниже перечислены все атрибуты пути, определенные для протокола BGP.
База данных состояния связей
Для работы алгоритма SPF на каждом маршрутизаторе строится база данных состояния связей, представляющая собой полное описание графа OSPF-системы. При этом вершинами графа являются маршрутизаторы, а ребрами- соединяющие их связи. Базы данных на всех маршрутизаторах идентичны.
За создание баз данных и поддержку их взаимной синхронизации при изменениях в структуре системы сетей отвечают другие алгоритмы, содержащиеся в протоколе OSPF. Мы рассмотрим эти алгоритмы , а сейчас будем считать, что базы данных на всех маршрутизаторах каким-то образом построены, синхронизированы и правильно описывают граф системы в данный момент времени.
База данных состояния связей представляет из себя таблицу, где для каждой пары смежных вершин графа (маршрутизаторов) указано ребро (связь), их соединяющее, и метрика этого ребра. Граф считается ориентированным, то есть ребро, соединяющее вершину ?
с вершиной ?
, и ребро, соединяющее вершину ?
с вершиной ?
, могут быть различны или это может быть одно и то же ребро, но с разными метриками.
База данных состояния связей в нашем примере () выглядит следующим образом:

Базовая передача данных
Модуль TCP выполняет передачу непрерывных потоков данных между своими клиентами в обоих направлениях. Клиентами TCP являются прикладные процессы, вызывающие модуль TCP при необходимости получить или отправить данные процессу-клиенту на другом узле.
Протокол TCP рассматривает данные клиента как непрерывный неинтерпретируемый поток октетов. TCP разделяет этот поток на части для пересылки на другой узел в TCP-сегментах некоторого размера. Для отправки или получения сегмента модуль TCP вызывает модуль IP.
Немедленное отправление данных может быть затребовано процессом-клиентом от TCP-модуля с помощью специальной функции PUSH, иначе TCP сам будет решать, как накапливать и когда отправлять данные клиента или когда передавать клиенту полученные данные.
Бесклассовая модель (CIDR)
Предположим, в локальной сети, подключаемой к Интернет, находится 2000 компьютеров. Каждому из них требуется выдать IP-адрес. Для получения необходимого адресного пространства нужны либо 8 сетей класса C, либо одна сеть класса В. Сеть класса В вмещает 65534 адреса, что много больше требуемого количества. При общем дефиците IP-адресов такое использование сетей класса В расточительно. Однако если мы будем использовать 8 сетей класса С, возникнет следующая проблема: каждая такая IP-сеть должна быть представлена отдельной строкой в таблицах маршрутов на маршрутизаторах, потому что с точки зрения маршрутизаторов — это 8 абсолютно никак не связанных между собой сетей, маршрутизация дейтаграмм в которые осуществляется независимо, хотя фактически эти IP-сети и расположены в одной физической локальной сети и маршруты к ним идентичны. Таким образом, экономя адресное пространство, мы многократно увеличиваем служебный трафик в сети и затраты по поддержанию и обработке маршрутных таблиц.
С другой стороны, нет никаких формальных причин проводить границу сеть-хост в IP-адресе именно по границе октета. Это было сделано исключительно для удобства представления IP-адресов и разбиения их на классы. Если выбрать длину сетевой части в 21 бит, а на номер хоста отвести, соответственно, 11 бит, мы получим сеть, адресное пространство которой содержит 2046 IP-адресов, что максимально точно соответствует поставленному требованию. Это будет одна сеть, определяемая своим уникальным 21-битным номером, следовательно, для ее обслуживания потребуется только одна запись в таблице маршрутов.
Единственная проблема, которую осталось решить: как определить, что на сетевую часть отведен 21 бит? В случае классовой модели старшие биты IP-адреса определяли принадлежность этого адреса к тому или иному классу и, следовательно, количество бит, отведенных на номер сети.
В случае адресации вне классов, с произвольным положением границы сеть-хост внутри IP-адреса, к IP-адресу прилагается 32-битовая маска, которую называют маской сети (netmask) или маской подсети (subnet mask). Сетевая маска конструируется по следующему правилу:
на позициях, соответствующих номеру сети, биты установлены; на позициях, соответствующих номеру хоста, биты сброшены.
Описанная выше модель адресации называется бесклассовой (CIDR - Classless Internet Direct Routing, прямая бесклассовая маршрутизация в Интернет). В настоящее время классовая модель считается устаревшей и маршрутизация и (большей частью) выдача блоков IP-адресов осуществляются по модели CIDR, хотя классы сетей еще прочно удерживаются в терминологии.
Бесплатное программное обеспечение
. Разные программы.
. Библиотека для формирования кадров и даfтаграмм произвольного формата.
. Библиотека для извлечения пакетов из сети (используется также программой tcpdump).
. Библиотека для поддержки SSL.
. Программа для прослушивания сети (sniffer).
. Программа для анализа и конвертирования дамп-файлов, записанных различными программами прослушивания.
. Программа для обнаружения в сети узлов, находящихся в режиме прослушивания.
. Сканер сети.
. Сканер для обнаружения проблем с безопасностью в сети. Использует nmap.
. Программа для формирования сообщений различных протоколов.
. Программа для обнаружения несоответствия между IP- и MAC-адресами в сети.
. NIDS (система обнаружения атак в сети).
. Универсальный прокси-сервер для TCP-сервисов (reference implementation).
. Программа мониторинга и фильтрации запросов на установление TCP-соединений через супердемон inetd.
. Программа для обнаружения попыток сканирования хоста.
. Утилита для отслеживания изменений в файловой системе.
. Супердемон для замены inetd. Осуществляет фильтрацию соединений и уменьшает риск DoS атак.
. Еще один вариант замены супердемона inetd.
, , . Реализации протокола SSH - защищенного варианта Telnet + FTP.
. Система распределенной аутентификации в сети.
. Утилита слежения за лог-файлами протоколов.
CBT
Метод CBT (Core Based Trees, Деревья с фиксированным ядром) основан на том, что для каждой группы назначается главный маршрутизатор, называемый ядром, – он будет корнем дерева рассылки (узел В на рис. 8.3.3). Все маршрутизаторы, к которым могут быть подключены потенциальные члены группы, знают адрес ядра. После того, как член группы зарегистрировался на маршрутизаторе с помощью протокола IGMP, маршрутизатор посылает в сторону ядра сообщение Join для присоединения к дереву рассылки. Промежуточные маршрутизаторы, пересылая это сообщение в сторону ядра, одновременно помечают интерфейсы, через которые получены сообщения Join, как принадлежащие дереву рассылки для данной группы. Сообщение следует до ядра или до первого маршрутизатора, уже присоединенного к дереву рассылки.

Рис. 8.3.3. Метод CBT
а) посылка сообщений Join; б) сформированное дерево рассылки
S – источник, A-F – маршрутизаторы;
к маршрутизатору А не подключены члены группы; метрики всех сетей, кроме явно указанных, равны 1
Состояние принадлежности к дереву имеет определенный срок годности, поэтому периодически требуется посылка подтверждений. Отметим, что каждый маршрутизатор посылает подтверждение вышестоящему (следующему по пути к ядру) маршрутизатору. Неподтвержденные в течение некоторого времени ветви дерева усекаются.
Рассылка же самих групповых дейтаграмм маршрутизаторами происходит аналогично методу остовых деревьев: дейтаграмма рассылается через все интерфейсы, принадлежащие дереву рассылки, кроме того, с которого дейтаграмма была получена. Если источник дейтаграммы не является членом группы, то его маршрутизатор сначала инкапсулирует групповую дейтаграмму в обычную, адресованную ядру, а ядро уже инициирует групповую рассылку по дереву.
Достоинства этого метода:
все групповые дейтаграммы рассылаются только участникам группы (в отличие от RPF нет "пробных" дейтаграмм);
размер таблицы принадлежности интерфейсов к деревьям рассылки, которую требуется хранить на маршрутизаторе, меньше чем при использовании метода RPF (произведение числа групп на число интерфейсов; для всех источников одной группы используется одно дерево);
не требуется доступ к маршрутным таблицам.
Недостатки CBT аналогичны недостаткам метода остовых деревьев:
весь групповой трафик ложится на одни и те же связи (сети), составляющие, возможно, небольшое подмножество всей системы сетей; узким местом является ядро;
для некоторых пар отправитель-получатель путь по установленному дереву будет неоптимальным (например, для источника S и получателей, подсоединенных к маршрутизатору С, рис 1.2.6С).
Протокол CBT (RFC-2189) реализует метод CBT так, как он описан в п. . В протоколе CBT предусмотрена возможность взаимодействия с DVMRP.
Decision Process
Рассмотрим действия BGP-маршрутизатора при получении и анонсировании маршрута (рис. 7.4.1). Маршрутизатор использует три базы данных: Adj-RIBsIn, Loc-RIB и Adj-RIBsOut, в которых содержатся маршруты, соответственно, полученные от соседей, используемые самим маршрутизатором и объявляемые соседям. Также на маршрутизаторе сконфигурированы две политики: политика приема маршрутов (accept policy) и политика анонсирования маршрутов (announce policy). Для обработки маршрутов в базах данных в соответствии с имеющимися политиками маршрутизатор выполняет процедуру под названием процесс отбора (decision process), описанную ниже.
Маршруты, полученные от BGP-соседей, помещаются в базу данных Adj-RIBsIn. В соответствии с политикой приема для каждого маршрута в Adj-RIBsIn вычисляется приоритет (это называется фазой 1 процесса отбора). В результате этих действий некоторые маршруты могут быть отбракованы (признаны неприемлемыми).
Далее (фаза 2) для каждой сети из всех имеющихся (полученных и неотбракованных) вариантов выбирается маршрут с большим приоритетом. Результаты заносятся в базу Loc-RIB, откуда менеджер маршрутной таблицы IP-модуля может их взять для установки в таблицу маршрутов маршрутизатора и для экспорта во внутренний протокол маршрутизации с тем, чтобы и другие узлы автономной системы имели маршруты к внешним сетям. И наоборот, чтобы другие автономные системы имели маршруты к сетям данной АС, из таблиц протокола (протоколов) внутренней маршрутизации могут извлекаться номера сетей своей АС и заноситься в Loc-RIB.
Задача третьей фазы – отбор маршрутов для анонсирования (рассылки соседям). Из LocRIB выбираются маршруты, соответствующие политике анонсирования, и результат помещается в базу Adj-RIBsOut, содержимое которой и рассылается BGP-соседям. Возможно, что маршрутизатор имеет разные политики анонсирования для каждого соседа.

Рис. 7.4.1. Обработка маршрутной информации модулем BGP
Важным свойством процесса отбора является то, что BGP-маршрутизатор объявляет только те маршруты, которые он сам использует. Это обстоятельство является следствием природы IP-маршрутизации: при выборе маршрута для дейтаграммы учитывается только адрес получателя и никогда – адрес отправителя. Таким образом, если маршрутизатор сам использует один маршрут в сеть Х, а соседу объявил другой, то дейтаграммы от соседа все равно будут пересылаться в сеть Х по тому маршруту, который использует сам маршрутизатор, поскольку адрес отправителя при выборе маршрута IP-модулем не рассматривается.
Десинхронизация TCP-соединения
Злоумышленник Х, находящийся в одном сегменте сети с узлами А и В или на пути между А и В, может произвести десинхронизацию TCP-соединения между А и В для установления полного контроля над соединением, то есть, злоумышленник получит возможность действовать как от имени А, так и от имени В. Для обозначения имперсонации, выполняемой таким методом, в англоязычной литературе используется термин TCP hijacking. Впервые эта атака была описана в [].
Определим, что такое десинхронизация TCP-соединения. При установленном соединении каждый из узлов А и В знает, октеты с какими номерами может прислать ему собеседник в данный момент: если последнее подтверждение, высланное узлом А, было ACKAB и при этом узел А объявил окно WAB, то А ожидает от В октетов с номерами SNBA, попадающими в объявленное окно, то есть:
ACKAB <= SNBA <= ACKAB + WAB
Аналогично в узле В ожидается от А:
ACKBA <= SNAB <= ACKBA + WBA
Если, например, узел А по какой-то причине получает от В сегмент с номером SNBA, не попадающим в окно, то этот сегмент уничтожается, а в ответ А отправляет в В сегмент с SNAB, ACKAB, WAB, чтобы указать узлу В, какие именно октеты ожидает получить А. Отметим, что скорее всего этот сегмент не содержит данных, но номер SNAB в этом сегменте тем не менее должен быть указан, где SNAB — номер следующего октета данных, который А когда-либо вышлет в В.
Предположим, злоумышленнику каким-то образом удалось сбить показатели счетчиков узлов А и (или) В так, что вышеприведенные неравенства больше не выполняются (как это можно сделать, мы обсудим ниже). Далее мы будем использовать обозначения вида SNAB(B), что означает «приемлемый SNAB с точки зрения В».
Теперь, если В посылает в А сегмент с неким номером SNBA(B), адекватным с точки зрения В, но уже не попадающим в окно в узле А, то А возвращает узлу В подтверждение со своим значением ACKAB=SNBA(A). Однако в этом же сегменте имеется номер SNAB(A), который теперь уже В рассматривает как не попадающий в свое окно и отправляет в А подтверждение SNBA(B), ACKBA=SNAB(A). Номер SNBA(B), как и раньше, неприемлем для А, и узел А вновь отправляет в В подтверждение, и этот цикл, называемый ACK-шторм, теоретически продолжается до бесконечности, а практически — до тех пор, пока один из ACK-сегментов не потеряется в сети. Чем сильнее шторм, тем больше загрузка сети, тем выше процент потерь, следовательно, тем быстрее шторм прекратится.
Итак, в десинхронизированном состоянии любая попытка обмена данными вызывает только ACK-шторм, а сами сегменты с данными участниками соединения уничтожаются.
В это время злоумышленник, знающий «правильные» номера с точки зрения обоих узлов, берет на себя функции посредника (рис. 9.6). Он прослушивает сеть, обнаруживает сегмент с данными длиной L октетов, направленный, например, из А в В, меняет в нем номер SNAB(A) на ожидаемый узлом В номер SNAB(B) и, пересчитав контрольную сумму, отправляет сегмент в В от имени А. После этого в узел А от имени В злоумышленник отправляет подтверждение на этот сегмент, содержащее правильный с точки зрения А номер SNBA(A). Во время этого обмена в виде побочного явления возникают два ACK-шторма: первый инициирует узел В, получивший из А оригинальный сегмент с SNAB(A) != SNAB(B), а второй шторм возникает, когда узел А получает от В сегмент, подтверждающий получение данных от Х, и в этом сегменте SNBA(B) != SNBA(A).
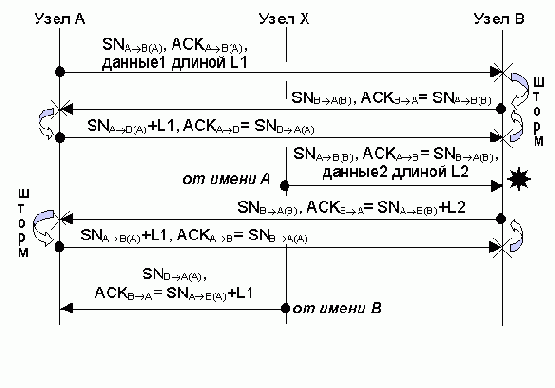
Рис. 9.6. Действия злоумышленника-посредника в десинхронизированном соединении между узлами А и В
(L1, L2 — объем данных в пересылаемых сегментах)
Разумеется, злоумышленник затевает атаку не для того, чтобы просто ретранслировать сегменты, которые он и так может подслушать. Ничто не мешает ему изменять содержащиеся в сегментах данные или добавлять свои: на рис. 9.6 это отображено в виде «данных 2», имеющих длину L2 октетов, в то время как оригинальные данные обозначены «данные 1» длиной L1 октетов. Например, если имеет место сессия программы telnet и А посылает в В некоторую команду, то злоумышленник может вставить в этот сегмент еще одну команду. Результат выполнения своей команды он получит, подслушав ответный сегмент SNBA(B), направленный из В в А, который узел А не воспримет из-за несовпадения порядковых номеров, так как SNBA(B) != SNBA(A). Зато злоумышленник, удалив из этого сегмента результат выполнения своей команды, отправит то, что осталось (то есть результат оригинальной команды) в А от имени В уже с приемлемым порядковым номером SNBA(A).
Злоумышленник может вообще игнорировать сегменты, посылаемые узлом А и отправлять в В только свои данные, получая ответы прослушиванием сети и соответственно реагируя на них, но в этом случае узел А заметит, что В не отвечает на его команды, и может забеспокоиться.
Рассмотрим, каким образом злоумышленник может перевести TCP-соединение в десинхронизированное состояние.
Ранняя десинхронизация
Ранняя десинхронизация (рис. 9.7): злоумышленник, прослушивая сеть, обнаруживает момент установления соединения между А и В, от имени А сбрасывает соединение RST-сегментом и тут же открывает его заново, но уже с новыми номерами ISN. Разберем эту процедуру в деталях.
Сначала А посылает в В сегмент SYNAB, ISNAB(A), потом В отвечает сегментом SYNBA, ISNBA(1), ACKBA(ISNAB(A)+1). По получении этого сегмента А переходит в состояние ESTABLISHED и посылает в В подтверждающий сегмент ACKAB(ISNBA(1)+1).
В этот момент злоумышленник от имени А отправляет в В сегмент RSTAB и следом за ним сегмент SYNAB, ISNAB(X), содержащий те же номера портов, но другой номер ISNAB= ISNAB(X), неприемлемый для А.
При получении этих сегментов узел В закрывает установленное соединение с А, а затем тут же вновь отрывает его и отправляет в А сегмент SYNBA, ISNBA(2), ACKBA(ISNAB(Х)+1), где ISNBA(2) — новый начальный порядковый номер, ISNBA(1) != ISNBA(2).
Узел А не воспринимает этот сегмент из-за несовпадения порядковых номеров, но злоумышленник от имени А посылает в В сегмент SNAB=ISNAB(Х)+1, ACKAB(ISNBA(2)+1).

Рис. 9.7. Ранняя десинхронизация TCP-соединения
(сегменты ACK-шторма не показаны)
После этого оба узла А и В находятся в состоянии ESTABLISHED, но соединение десинхронизировано (рис. 9.8).

Рис. 9.8. Состояние соединения после ранней десинхронизации
Отметим, что некоторые реализации TCP в нарушение стандарта в ответ на получение RST-сегмента сами отправляют RST-сегмент. В этом случае десинхронизация описанным способом невозможна.
Десинхронизация нулевыми данными
Десинхронизация нулевыми данными (рис. 9.9): злоумышленник, дожидаясь момента, когда соединение находится в неактивном состоянии (данные не передаются), посылает узлу А от имени В и узлу В от имени А фальсифицированные сегменты с данными, вызывая тем самым десинхронизацию. Посылаемые данные должны быть «нулевыми» — то есть приложение-получатель должно их молча игнорировать и не посылать никаких данных в ответ. Этот метод десинхронизации подходит для Telnet-соединений, которые, во-первых, часто находятся в неактивном состоянии, а во-вторых, в протоколе Telnet имеется команда «нет операции» (IAC NOP). Сегмент, содержащий произвольное число таких команд (IAC NOP IAC NOP …), будет принят приложением и полностью проигнорирован.
Кроме того, в начале Telnet-сеанса производится аутентификация пользователя. Ра-зумно ( с точки зрения злоумышленника) произвести десинхронизацию после того, как введен пароль, а не в самом начале соединения. Отметим, что даже использование одноразовых паролей в этом случае пользователю не поможет.

Рис. 9.9. Десинхронизация TCP-соединения нулевыми данными
(сегменты ACK-шторма не показаны)
После описанной процедуры имеет место следующая ситуация, показанная на рис. 9.10.

Рис. 9.10. Состояние соединения после десинхронизации нулевыми данными
Имперсонация с помощью десинхронизации является сравнительно простой и очень эффективной атакой. Она позволяет злоумышленнику установить полный контроль над TCP-соединением без использования ложных сообщений ARP, ICMP или протоколов маршрутизации, без атак типа «отказ в обслуживании», которые могут быть обнаружены администратором сети или атакуемого узла. Обнаружить такие атаки можно, прослушивая сеть на предмет ACK-штормов.
Для защиты от описанных в этом пункте атак маршрутизатор (шлюз, брандмауэр), соединяющий сеть с внешним миром, должен быть настроен на запрет пропуска пакетов;
а) приходящих на внешний интерфейс, но имеющих адрес отправителя из внутренней сети;
б) приходящих на внутренний интерфейс, но имеющих адрес отправителя из внешней сети.
Случай а) соответствует ситуации, когда узлы А и В находятся во внутренней сети, а злоумышленник расположен снаружи и пытается послать узлу А датаграмму якобы от узла В. Случай б) соответствует ситуации, когда злоумышленник находится во внутренней сети, а узлы А и В — снаружи. Подчеркнем, что предложенные меры не защитят от всех разновидностей имперсонации: например, когда узел Х находится в одной сети с узлом А или В, или, естественно, когда все три узла расположены в одной сети.
Хороший алгоритм генерации случайных номеров ISN защитит от атаки в случае отсутствия обратной связи, но бесполезен, если злоумышленник может видеть сегменты, передаваемые из А в В.
В общем случае только шифрование данных или аутентификация сегментов могут гарантировать защиту от имперсонации.
Динамическая маршрутизация
В случае объединения сетей со сложной топологией, когда существует несколько вариантов маршрутов от одного узла к другому и (или) когда состояние сетей (топология, качество каналов связи) изменяется с течением времени, таблицы маршрутов составляются динамически с помощью различных протоколов маршрутизации. Подчеркнем, что протоколы маршрутизации не осуществляют собственно маршрутизацию дейтаграмм- она в любом случае производится модулем IP согласно записям в таблице маршрутов, как обсуждалось выше. Протоколы маршрутизации на основании тех или иных алгоритмов динамически редактируют таблицу маршрутов, то есть вносят и удаляют записи, при этом часть записей может по-прежнему статически вноситься администратором.
В зависимости от алгоритма работы различают дистанционно-векторные протоколы (distance vector protocols) и протоколы состояния связей (link state protocols).
По области применения существует разделение на протоколы внешней (exterior) и внутренней (interior) маршрутизации.
Дистанционно-векторные протоколы реализуют алгоритм Беллмана-Форда (Bellman-Ford). Общая схема их работы такова: каждый маршрутизатор периодически широковещательно рассылает информацию о расстоянии от себя до всех известных ему сетей (“вектор расстояний”). В начальный момент времени, разумеется, рассылается информация только о тех сетях, к которым маршрутизатор подключен непосредственно.
Также каждый маршрутизатор, получив от кого-либо вектор расстояний, в соответствии с полученной информацией корректирует уже имеющиеся у него данные о достижимости сетей или добавляет новые, указывая маршрутизатор, от которого получен вектор, в качестве следующего маршрутизатора на пути в данные сети. Через некоторое время алгоритм сходится и все маршрутизаторы имеют информацию о маршрутах до всех сетей.
Дистанционно-векторные протоколы хорошо работают только в небольших сетях. Подробнее алгоритм их работы будет рассмотрен в . Развитие технологии векторов расстояний - “векторы путей”, применяющиеся в протоколе BGP.
При работе протоколов состояния связей каждый маршрутизатор контролирует состояние своих связей с соседями и при изменении состояния (например, при обрыве связи) рассылает широковещательное сообщение, после получения которого все остальные маршрутизаторы корректируют свои базы данных и пересчитывают маршруты. В отличие от дистанционно-векторных протоколов протоколы состояния связей создают на каждом маршрутизаторе базу данных, описывающую полный граф сети и позволяющую локально и, следовательно, быстро производить расчет маршрутов.
Распространенный протокол такого типа, OSPF, базируется на алгоритме SPF (Shortest Path First) поиска кратчайшего пути в графе, предложенном Дейкстрой (E.W.Dijkstra).
Протоколы состояния связей существенно сложнее дистанционно-векторных, но обеспечивают более быстрое, оптимальное и корректное вычисление маршрутов. Подробнее протоколы состояния связей будут рассмотрены на примере протокола OSPF в .
Протоколы внутренней маршрутизации (например, RIP, OSPF; собирательное название IGP - Interior Gateway Protocols) применяются на маршрутизаторах, действующих внутри автономных систем. Автономная система - это наиболее крупное деление Интернет, представляющее из себя объединение сетей с одинаковой маршрутизационной политикой и общей администрацией, например, совокупность сетей компании Глобал Один и ее клиентов в России.
Область действия того или иного протокола внутренней маршрутизации может охватывать не всю автономную систему, а только некоторое объединение сетей, являющееся частью автономной системы. Такое объединение мы будем называть системой сетей, или просто системой, иногда с указанием протокола маршрутизации, действующего в этой системе, например: RIP-система, OSPF-система.
Маршрутизация между автономными системами осуществляется пограничными (border) маршрутизаторами, таблицы маршрутов которых составляются с помощью протоколов внешней маршрутизации (собирательное название EGP - Exterior Gateway Protocols). Особенность протоколов внешней маршрутизации состоит в том, что при расчете маршрутов они должны учитывать не только топологию графа сети, но и политические ограничения, вводимые администрацией автономных систем на маршрутизацию через свои сети трафика других автономных систем. В настоящее время наиболее распространенным протоколом внешней маршрутизации является BGP.
Дополнительные возможности OSPF
В дополнение к общей идеологии протоколов состояния связей, описанной в предыдущих разделах этой главы, в OSPF реализованы дополнительные возможности, позволяющие оптимизировать расчет маршрутов в сетях с множественным доступом и в сложных системах сетей.
DVMRP
Протокол DVMRP (Distance Vector Multicast Routing Protocol, RFC-1075) – самый старый протокол групповой маршрутизации, он используется в ядре экспериментальной сети MBONE. Протокол работает по технологии RPF с усечением, но для построения деревьев используется собственный дистанционно-векторный протокол, аналогичный протоколу RIP.
Протокол DVRMP прост в реализации и весьма эффективен, но он подходит только для небольших сетей с высокой плотностью получателей. К недостаткам метода RPF, описанным в предыдущем пункте (относительно большой размер хранимой таблицы и необходимость рассылки "пробных" дейтаграмм по всей системе сетей), добавляется ограничение на размер системы сетей, унаследованное от протокола RIP (в DVMRP значение бесконечности равно 32).
Фаза закрытия соединения

Проблемы возникновения некорректных ситуаций, например, наполовину открытое соединение, получение заблудившихся в сети старых SYN-сегментов, неожиданный крах программ и т.п., решаются путем детектирования ошибки (несоответствие или бессмысленные значения ACK или SN), после чего посылается сигнал RST (сегмент с установленным битом RST) и соединение ликвидируется.
(С)
Фильтрация на маршрутизаторе
Фильтры на маршрутизаторе, соединяющем сеть предприятия с Интернетом, применяются для запрета пропуска датаграмм, которые могут быть использованы для атак как на сеть организации из Интернета, так и на внешние сети злоумышленником, находящимся внутри организации.
Запретить пропуск датаграмм с широковещательным адресом назначения между сетью организации и Интернетом. Запретить пропуск датаграмм, направленных из внутренней сети (сети организации) в Интернет, но имеющих внешний адрес отправителя. Запретить пропуск датаграмм, прибывающих из Интернета, но имеющих внутренний адрес отправителя. Запретить пропуск датаграмм с опцией «Source Route» и, если они не используются для групповой рассылки, инкапсулированных датаграмм (IP-датаграмма внутри IP-датаграммы). Запретить пропуск датаграмм с ICMP-сообщениями между сетью организации и Интернетом, кроме необходимых (Destination Unreachable: Datagram Too Big — для алгоритма Path MTU Discovery; также Echo, Echo Reply, Destination Unreachable: Network Unreachable, Destination Unreachable: Host Unreachable, TTL exceeded). На сервере доступа клиентов по коммутируемой линии — разрешить пропуск датаграмм, направленных только с или на IP-адрес, назначенный клиенту. Запретить пропуск датаграмм с UDP-сообщениями, направленными с или на порты echo и chargen, либо на все порты, кроме используемых (часто используется только порт 53 для службы DNS). Использование TCP Intercept для защиты от атак SYN flood. Фильтрация TCP-сегментов выполняется в соответствии с политикой безопасности: разрешаются все сервисы, кроме запрещенных, или запрещаются все сервисы, кроме разрешенных (описывая каждый прикладной сервис в главе 3, мы будем обсуждать вопросы фильтрации сегментов применительно к сервису). Если во внутренней сети нет хостов, к которым предполагается доступ из Интернета, но разрешен доступ внутренних хостов в Интернет, то следует запретить пропуск TCP SYN-сегментов, не имеющих флага ACK, из Интернета во внутреннюю сеть1, а также запретить пропуск датаграмм с Fragment Offset=1 и Protocol=6 (TCP).
Отметим, что более безопасным и управляемым решением, чем фильтрация того или иного TCP-трафика следующего от или к компьютеру пользователя, является работа пользователей через прокси-серверы. Прокси-сервер берет на себя функции предоставления пользователю требуемого сервиса и сам связывается с необходимыми хостами Интернета. Хост пользователя же взаимодействует только с прокси-сервером и не нуждается в коннективности с Интернетом. Таким образом, фильтрующий маршрутизатор разрешает прохождение TCP-сегментов определенного типа только от или к прокси-серверу. Преимущества этого решения следующие.
Прокси-сервер находится под контролем администратора предприятия, что позволяет реализовывать различные политики для дифференцированного управления доступом пользователей к сервисам и ресурсам Интернета, фильтрации передаваемых данных (защита от вирусов, цензура и т.п.), кэширования (там, где это применимо).
С точки зрения Интернета от имени всех пользовательских хостов предприятия действует один прокси-сервер, то есть имеется только один потенциальный объект для атаки из Интернета, а безопасность одного прокси-сервера, управляемого профессионалом, легче обеспечить, чем безопасность множества пользовательских компьютеров.
Формат BGP-сообщения
Сообщение протокола BGP состоит из заголовка и тела. Заголовок имеет длину 19 октетов и состоит из следующих полей:
16 октетов - маркер: в сообщении OPEN всегда, и при работе без аутентификации - в других собщениях, заполнен единицами. Иначе содержит аутентификационную информацию. Сопутствующая функция маркера - повышение надежности выделения границы сообщения в потоке данных. 2 октета - длина сообщения в октетах, включая заголовок. 1 октет - тип сообщения:
1 - OPEN 2 - KEEPALIVE 3 - UPDATE 4 - NOTIFICATION
Формат сообщения KEEPALIVE
Сообщение KEEPALIVE состоит только из BGP-заголовка.
Формат сообщения NOTIFICATION
Сообщение NOTIFICATION состоит из следующих полей:
1 октет - Код ошибки, 1 октет - Субкод ошибки, X октетов - данные, X=Длина_всего_сообщения - 19(длина заголовка) - 1 - 1. Количество и интерпретация данных зависят от кода и субкода ошибки.
Определены следующие коды ошибок:
1 - Ошибка заголовка 2 - Ошибка в сообщении OPEN 3 - Ошибка в сообщении UPDATE 4 - Истекло время ожидания сообщения KEEPALIVE 5 - Ошибка последовательности состояний 6 - Закрытие соединения по желанию участника
(С)
Формат сообщения OPEN
Сообщение OPEN состоит из следующих полей:
19 октетов - заголовок с маркером, заполненным единицами. 1 октет - версия BGP (=4). 2 октета - номер своей АС. 2 октета - Hold Time - максимальное вермя (в секундах) между приходами сообщений KEEPALIVE, используемых для монитронига активности соединения; значение 0 - KEEPALIVE не посылаются вообще (мониторинг не производится); значения 1 и 2 не разрешаются. При получении сообщения маршрутизатор принимает для данного соединения значение Hold Time, равное минимуму из того, что он получил в сообщении OPEN, и значения, указанного в конфигурации маршрутизатора. Если сообщение KEEPALIVE не было получено в течении Hold Time секунд, соединение считается закрытым и вся связанная с ним маршрутная информация ликвидируется.
4 октета - идентификатор маршрутизатора (один из адресов интерфейсов).
1 октет - длина опции в октетах. Опции кодируются в виде: октет "Тип опции", октет "Длина опции в октетах", содержимое опции. Стандарт определяет одну опцию (тип 1) - "Определение типа аутентификации", содержимое которой состоит из октета "Тип аутентификации" и аутентификационных данных, интерпретация которых зависит от типа аутентификации. Предполагается, что на основании этой информации будет заполняться маркер заголовка.
Формат сообщения UPDATE
Сообщение UPDATE состоит из трех частей переменной длины: список недействительных маршрутов, список атрибутов и список сетей, к которым эти атрибуты относятся. Две последние части представляют собой собственно информацию о маршруте в указанные сети. (То есть, если маршруты в несколько разных сетей имеют одинаковые атрибуты, то они объединяются в одном сообщении UPDATE. Разумеется, предварительно адреса сетей везде, где это возможно, агрегируются в общий префикс.) Как первая часть сообщения, так и две последние могут отсутствовать.
Формат сообщения:
19 октетов - заголовок, 2 октета - длина списка недействительных маршрутов L1; L1 октетов - список недействительных маршрутов; 2 октета - длина списка атрибутов L2; L2 октетов - список атрибутов для указанных ниже сетей; X октетов - список адресов сетей (Network Layer Reachability Information, NLRI).
X= Длина_всего_сообщения - 19(длина заголовка) - 4 - L1 - L2.
Список адресов сетей и список недействительных маршрутов представляют собой списки элементов, каждый элемент состоит из 2 частей:
1 октет - длина префикса L N октетов - префикс, где N - верхняя целая часть от L/8.
Например, префикс 10.0.0.0/8 представляется в виде двух октетов:
| 8 | 10 |
Префикс 172.16.192.0/19 представляется в виде 4 октетов:
| 19 | 172 | 16 | 192 |
Напомним, что формально префикс представляет собой адрес некой сети, а длина префикса интерпретируется также как длина сетевой маски. В реальном адресном пространстве префикс может соответствовать одной IP-сети или агрегировать в себе несколько IP-сетей.
Для отмены маршрута достаточно указать только адрес сети (префикс) назначения, по которому сосед найдет и удалит из своей базы все данные по этому маршруту. В одном сообщении может быть отменено несколько маршрутов.
Для объявления маршрута следует представить префикс назначения и список атрибутов пути для этого префикса. Только один список атрибутов передается в одном собщении, но указанные атрибуты могут относиться к нескольким префиксам, список которых приводится за списком атрибутов.
Список атрибутов представляет собой список элементов, каждый элемент состоит из 4 частей:
1 октет - флаги атрибута, 1 октет - тип атрибута, 1 или два октета, в зависимости от бита 3 флагов - длина данных атрибута L, L октетов, может быть 0, - данные атрибута.
Флаги атрибута:
бит 0=1 - атрибут всеобщий (обязан обрабатываться любым BGP-процессом: например, ORIGIN, AS_PATH, NEXT_HOP, LOCAL_PREF, ATOMIC_AGGREGATE), бит 0=0 - атрибут дополнительный (BGP-процесс может проигнорировать этот атрибут: например, MULTI_EXIT_DISC, AGGREGATOR). бит 1=1 - для дополнительных атрибутов: атрибут транзитивный (должен передаваться при переобъявлении маршрута другому соседу, например, AGGREGATOR). Для прочих атрибутов бит 1 всегда установлен. бит 1=0 - Для дополнительных атрибутов: атрибут не транзитивный (не передается при переобъявлении маршрута другому соседу, например, MULTI_EXIT_DISC). бит 2=1 - (только дополнительных транзитивных атрибутов) какой-то из маршрутизаторов, через которые проходил атрибут, проигнорировал его, бит 2=0 - (только дополнительных транзитивных атрибутов) все маршрутизаторы по пути следования обработали атрибут. Для прочих атрибутов бит 2 всегда обнулен. бит 3=1 - поле "Длина данных атрибута" занимает 2 октета, бит 3=0 - поле "Длина данных атрибута" занимает 1 октет.
Длина и интерпертация данных атрибута зависит от типа атрибута.
ORIGIN (тип 1) - 1 октет данных, содержащий значение атрибута (целое число 0, 1 или 2). ASPATH (тип 2) - данные атрибута состоят из списка элементов, каждый элемент состоит из 3 частей:
1 октет - тип сегмента пути: AS_SEQUENCE (=2) или AS_SET (=1), 1 октет - число N номеров АС в сегменте, 2N октетов - список номеров АС этого сегмента пути (по два октета на номер).
NEXT_HOP (тип 3) - 4 октета, содержащих значение атрибута (IP-адрес). MULTI_EXIT_DISC (тип 4) - 4 октета, содержащих значение атрибута (беззнаковое целое число). LOCAL_PREF (тип 5)- 4 октета, содержащих значение атрибута (беззнаковое целое число). ATOMIC_AGGRGATE (тип 6) - нет данных (значением атрибута является его присутствие). AGGREGATOR (тип 7) - 6 октетов, содержащих значение атрибута (2 октета - номер АС, 4 октета - IP-адрес).
Формулировка маршрутных политик
Способы описания маршрутных политик не являются частью протокола BGP и отличаются в различных реализациях BGP. Однако в любом случае политики базируются на критериях отбора маршрутов и модификации атрибутов маршрутов, попавших под критерии отбора. Модификация атрибутов маршрута в свою очередь влияет на приоритет этого маршрута при отборе нескольких альтернативных маршрутов во время фазы 2.
Для полного запрета принятия или объявления маршрута используется фильтрация, которую можно рассматривать как назначение наинизшего приоритета, не позволяющего использовать маршрут вообще.
Отбор маршрутов из базы Adj-RIBsIn (для реализации политики приема) может производиться, например, по следующим критериям:
регулярное выражение для значения AS_PATH (частные случаи: номер конечной АС маршрута, АС соседа, от которого получен маршрут);
адрес сети, в которую ведет маршрут;
адрес соседа, приславшего информацию о маршруте;
происхождение маршрута (атрибут ORIGIN).
К маршруту, удовлетворяющему установленному критерию, можно применить следующие политики:
не принимать маршрут – удалить из Adj-RIBsIn (фильтрация);
установить административный вес маршрута,
установить значение атрибута LOCAL_PREF,
установить маршрут в качестве маршрута по умолчанию.
Административный вес маршрута не является атрибутом BGP, он устанавливает внутренний приоритет маршрута на данном маршрутизаторе (в то время, как LOCAL_PREF устанавливает приоритет маршрута в рамках автономной системы).
Если (после выполнения фильтрации) в базе Adj-RIBsIn имеется несколько альтернативных маршрутов, ведущих в одну сеть назначения, то отбор лучшего из них производится фазой 2 по приведенным ниже критериям (на примере маршрутизаторов Cisco). Критерии последовательно применяются в указанном порядке, пока не останется единственный маршрут:
наибольший административный вес;
наибольшее значение LOCAL_PREF;
кратчайший AS_PATH (маршрут, порожденный в локальной АС, имеет самый короткий – пустой – AS_PATH);
наименьшее значение ORIGIN (IGP<EGP<INCOMPLETE);
наименьшее значение MULTI_EXIT_DISC (отсутствующий MULTI_EXIT_DISC считается нулевым);
маршрут, полученный по EBGP, против маршрута, полученного по IBGP;
если все маршруты получены по IBGP, то выбирается маршрут через ближайшего соседа;
маршрут, полученный от BGP-соседа с наименьшим идентификатором (IP-адресом).
Аналогично, отбор маршрутов в базу Adj-RIBsOut (для реализации политики объявлений) может производиться, например, по следующим критериям:
регулярное выражение для значения AS_PATH (частные случаи: номер конечной АС маршрута, АС соседа, от которого получен маршрут);
адрес сети, в которую ведет маршрут;
адрес соседа, которому этот маршрут объявляется;
происхождение маршрута (атрибут ORIGIN).
К маршруту, удовлетворяющему установленному критерию, можно применить следующие политики:
не объявлять маршрут (фильтрация);
MULTI_EXIT_DISC: не устанавливать, установить указанное значение, взять в качестве значения метрику маршрута из IGP;
произвести агрегирование сетей в общий префикс;
модифицировать AS_PATH указанным образом;
заменить маршрут на default.
Фрагментация дейтаграмм
Различные среды передачи имеют различный максимальный размер передаваемого блока данных (MTU- Media Transmission Unit), это число зависит от скоростных характеристик среды и вероятности возникновения ошибки при передаче. Например, размер MTU в 10Мбит/с Ethernet равен 1536 октетам, в 100 Мбит/с FDDI - 4096 октетам.
При передаче дейтаграммы из среды с большим MTU в среду c меньшим MTU может возникнуть необходимость во фрагментации дейтаграммы. Фрагментация и сборка дейтаграмм осуществляются модулем протокола IP. Для этого применяются поля “ID” (Identification), “Flags” и “Fragment Offset” заголовка дейтаграммы.
Flags -поле состоит из 3 бит, младший из которых всегда сброшен:
0
DF
MF
Значения бита DF (Don’t Fragment):
0 - фрагментация разрешена,
1 - фрагментация запрещена (если дейтаграмму нельзя передать без фрагментации, она уничтожается).
Значения бита MF (More Fragments):
0 - данный фрагмент последний (единственный),
1 - данный фрагмент не последний.
ID (Identification) - идентификатор дейтаграммы, устанавливается отправителем; используется для сборки дейтаграммы из фрагментов для определения принадлежности фрагментов одной дейтаграмме.
Fragment Offset - смещение фрагмента, значение поля указывает, на какой позиции в поле данных исходной дейтаграммы находится данный фрагмент. Смещение считается 64-битовыми порциями, т.е. минимальный размер фрагмента равен 8 октетам, а следующий фрагмент в этом случае будет иметь смещение 1. Первый фрагмент имеет смещение нуль.
Рассмотрим процесс фрагментации на примере. Допустим, дейтаграмма размером 4020 октетов (из них 20 октетов заголовка) передается из среды FDDI (MTU=4096) в среду Ethernet (MTU=1536). На границе сред производится фрагментация дейтаграммы. Заголовки в данной дейтаграмме и во всех ее фрагментах одинаковой длины - 20 октетов.
Исходная дейтаграмма:
заголовок: ID=X, Total Length=4020, DF=0, MF=0, FOffset=0
данные (4000 октетов): “А....А” (1472 октета), “В....В” (1472 октета), “С....С” (1056 октетов)
Фрагмент 1:
заголовок: ID=X, Total Length=1492, DF=0, MF=1, FOffset=0
данные: “А....А” (1472 октета)
Фрагмент 2:
заголовок: ID=X, Total Length=1492, DF=0, MF=1, FOffset=184
данные: “B....B” (1472 октета)
Фрагмент 3:
заголовок: ID=X, Total Length=1076, DF=0, MF=0, FOffset=368
данные: “C....C” (1056 октетов)
Фрагментация может быть рекурсивной, т.е., например, фрагменты 1 и 2 могут быть еще раз фрагментированы; при этом смещение (Fragment Offset) считается от начала исходной дейтаграммы.
Функции протокола IP
Протокол IP находится на межсетевом уровне стека протоколов TCP/IP. Функции протокола IP определены в стандарте RFC-791 следующим образом: “Протокол IP обеспечивает передачу блоков данных, называемых дейтаграммами, от отправителя к получателям, где отправители и получатели являются компьютерами, идентифицируемыми адресами фиксированной длины (IP-адресами). Протокол IP обеспечивает при необходимости также фрагментацию и сборку дейтаграмм для передачи данных через сети с малым размером пакетов”.
Протокол IP является ненадежным протоколом без установления соединения. Это означает, что протокол IP не подтверждает доставку данных, не контролирует целостность полученных данных и не производит операцию квитирования (handshaking) - обмена служебными сообщениями, подтверждающими установку соединения с узлом назначения и его готовность к приему данных. Протокол IP обрабатывает каждую дейтаграмму как независимую единицу, не имеющую связи ни с какими другими дейтаграммами в Интернет. После того, как дейтаграмма отправляется в сеть, ее дальнейшая судьба никак не контролируется отправителем (на уровне протокола IP). Если дейтаграмма не может быть доставлена, она уничтожается. Узел, уничтоживший дейтаграмму, может оправить по обратному адресу ICMP-сообщение (см. п. ) о причине сбоя.
Гарантию правильной передачи данных предоставляют протоколы вышестоящего уровня (например, протокол ), которые имеют для этого необходимые механизмы.
Одна из основных задач, решаемых протоколом IP,- маршрутизация дейтаграмм, т.е. определение пути следования дейтаграммы от одного узла сети к другому на основании адреса получателя.
Общий сценарий работы модуля IP на каком-либо узле сети, принимающего дейтаграмму из сети, таков:
с одного из интерфейсов уровня доступа к среде передачи (например, с Ethernet-интерфейса) в модуль IP поступает дейтаграмма; модуль IP анализирует заголовок дейтаграммы; если пунктом назначения дейтаграммы является данный компьютер:
если дейтаграмма является фрагментом большей дейтаграммы, ожидаются остальные фрагменты, после чего из них собирается исходная большая дейтаграмма; из дейтаграммы извлекаются данные и направляются на обработку одному из протоколов вышележащего уровня (какому именно - указывается в заголовке дейтаграммы);
если дейтаграмма не направлена ни на один из IP-адресов данного узла, то дальнейшие действия зависят от того, разрешена или запрещена ретрансляция (forwarding) “чужих” дейтаграмм; если ретрансляция разрешена, то определяются следующий узел сети, на который должна быть переправлена дейтаграмма для доставки ее по назначению, и интерфейс нижнего уровня, после чего дейтаграмма передается на нижний уровень этому интерфейсу для отправки; при необходимости может быть произведена фрагментация дейтаграммы; если же дейтаграмма ошибочна или по каким-либо причинам не может быть доставлена, она уничтожается; при этом, как правило, отправителю дейтаграммы отсылается ICMP-сообщение об ошибке.
При получении данных от вышестоящего уровня для отправки их по сети IP-модуль формирует дейтаграмму с этими данными, в заголовок которой заносятся адреса отправителя и получателя (также полученные от транспортного уровня) и другая информация; после чего выполняются следующие шаги:
если дейтаграмма предназначена этому же узлу, из нее извлекаются данные и направляются на обработку одному из протоколов транспортного уровня (какому именно - указывается в заголовке дейтаграммы); если дейтаграмма не направлена ни на один из IP-адресов данного узла, то определяются следующий узел сети, на который должна быть переправлена дейтаграмма для доставки ее по назначению, и интерфейс нижнего уровня, после чего дейтаграмма передается на нижний уровень этому интерфейсу для отправки; при необходимости может быть произведена фрагментация дейтаграммы; если же дейтаграмма ошибочна или по каким-либо причинам не может быть доставлена, она уничтожается.
Здесь и далее узлом сети называется компьютер, подключенный к сети и поддерживающий протокол IP. Узел сети может иметь один и более IP-интерфейсов, подключенных к одной или разным сетям, каждый такой интерфейс идентифицируется уникальным IP-адресом.
IP-сетью называется множество компьютеров (IP-интерфейсов), часто, но не всегда подсоединенных к одному физическому каналу связи, способных пересылать IP-дейтаграммы друг другу непосредственно (то есть без ретрансляции через промежуточные компьютеры), при этом IP-адреса интерфейсов одной IP-сети имеют общую часть, которая называется адресом, или номером, IP-сети, и специфическую для каждого интерфейса часть, называемую адресом, или номером, данного интерфейса в данной IP-сети. В настоящем пособии речь идет преимущественно об IP-сетях, поэтому приставку “IP” мы будем как правило опускать.
Маршрутизатором, или шлюзом, называется узел сети с несколькими IP-интерфейсами, подключенными к разным IP-сетям, осуществляющий на основе решения задачи маршрутизации перенаправление дейтаграмм из одной сети в другую для доставки от отправителя к получателю.
Хостами называются узлы IP-сети, не являющиеся маршрутизаторами. Обычно хост имеет один IP-интерфейс (например, связанный с сетевой картой Ethernet или с модемом), хотя может иметь и несколько.
Маршрутизаторы представляют собой либо специализированные вычислительные машины, либо компьютеры с несколькими IP-интерфейсами, работа которых управляется специальным программным обеспечением. Компьютеры конечных пользователей, различные серверы Интернет и т.п. вне зависимости от своей вычислительной мощности являются хостами.
Неотъемлемой частью IP-модуля является протокол ICMP (Internet Control Message Protocol), отправляющий диагностические сообщения при невозможности доставки дейтаграммы и в других случаях. Совместно с протоколом IP работает также протокол ARP (Address Resolution Protocol), выполняющий преобразования IP-адресов в MAC-адреса (например, адреса Ethernet). Работа протоколов ICMP и ARP рассмотрена ниже в пп. и соответственно.
Функции протокола TCP
Протокол TCP (Transmission Control Protocol, Протокол контроля передачи) обеспечивает сквозную доставку данных между прикладными процессами, запущенными на узлах, взаимодействующих по сети. Стандартное описание TCP содержится в RFC-793.
TCP- надежный байт-ориентированный (byte-stream) протокол с установлением соединения. TCP находится на транспортном уровне стека TCP/IP, между протоколом IP и собственно приложением. Протокол IP занимается пересылкой дейтаграмм по сети, никак не гарантируя доставку, целостность, порядок прибытия информации и готовность получателя к приему данных; все эти задачи возложены на протокол TCP.
При получении дейтаграммы, в поле Protocol которой указан код протокола TCP (6), модуль IP передает данные этой дейтаграммы модулю TCP. Эти данные представляют собой TCP-сегмент, содержащий TCP-заголовок и данные пользователя (прикладного процесса). Модуль TCP анализирует служебную информацию заголовка, определяет, какому именно процессу предназначены данные пользователя, проверяет целостность и порядок прихода данных и подтверждает их прием другой стороне. По мере получения правильной последовательности неискаженных данных пользователя они передаются прикладному процессу.
Ниже основные функции протокола TCP и их реализация рассмотрены более подробно.
Иерархическая маршрутизация (Разбиение на области)
Для упрощения вычисления маршрутов и уменьшения размера базы данных состояния связей OSPF-система может быть разбита на отдельные независимые области (areas), объединяемые в единую систему особой областью, называемой магистралью (backbone). Области, не являющиеся магистралью, называются периферийными.
Маршруты внутри каждой области вычисляются как в отдельной системе: база данных состояния связей содержит записи только о связях маршрутизаторов внутри области, действие протокола затопления не распространяется за пределы области.
Некоторые маршрутизаторы принадлежат магистрали и одной или нескольким периферийным областям. Такие маршрутизаторы называются областными пограничными маршрутизаторами (area border router, ABR). Каждая область должна иметь как минимум один ABR, иначе она будет полностью изолирована от остальной части системы.
Областные пограничные маршрутизаторы поддерживают отдельные базы данных состояния связей для всех областей, к которым они подключены. На основании этих данных они обобщают информацию о достижимости сетей внутри отдельных областей и сообщают результат в смежную область. Также ABR обрабатывают подобные сообщения от других ABR (граничащих с другими областями) и ретранслируют информацию о внешних маршрутах, исходящую от пограничных маршрутизаторов (автономной) системы (ASBR).
Тем самым обеспечивается передача маршрутной информации и коннективность между областями. При этом за пределы области передается не полная база данных состояния связей, а просто список сетей этой области, достижимых извне области через данный ABR, вместе с метриками расстояния до этих сетей. Если возможно, адреса сетей агрегируются в общий адрес с более короткой маской. Подобную же информацию, но только о сетях, лежащих за пределами OSPF-системы, распространяют ASBR.
Имперсонация
Предположим, что узел А обменивается IP-датаграммами с узлом В, при этом узлы идентифицируют друг друга по IP-адресам, указываемым в датаграммах. Предположим далее, что узел В имеет особые привилегии при взаимодействии с А: то есть А предоставляет В некоторый сервис, недоступный для других хостов Интернета. Злоумышленник на узле Х, желающий получить такой сервис, должен имитировать узел В — такие действия называются имперсонацией узла В узлом Х.
Говоря о сервисах, мы имеем в виду приложения UDP или TCP, то есть речь идет об имперсонации UDP-сообщений или TCP-соединений (соответственно, UDP-spoofing и TCP-spoofing). Часто одновременно с имперсонацией злоумышленник предпринимает атаки типа «отказ в обслуживании» (п. ) против узла В для исключения последнего из процесса сетевого взаимодействия.
Хосты А, В и Х могут располагаться друг относительно друга различным образом, от этого зависит, какие методы имперсонации применит злоумышленник.
Если злоумышленник может перехватить трафик, идущий от узла А к В (одним из методов, описанных в предыдущем пункте), то задача имперсонации практически выполнена. Получая от узла А UDP-сообщения или TCP-сегменты, адресованные узлу В, злоумышленник не передает их по назначению, а вместо этого сам формирует пакеты от имени В. При этом узел В даже не подозревает о происходящем, поэтому атаковать его на предмет отказа в обслуживании не имеет смысла.
Напомним, что перехват трафика возможен, когда:
1) А, В и Х находятся в одной IP-сети (ARP-атака);
2) А и Х находятся в одной сети, а В — в другой (навязывание ложного маршрутизатора);
3) А и В находятся в разных сетях, а Х находится на пути между ними (или включает себя в маршрут путем атаки на протокол маршрутизации).
В остальных случаях злоумышленник не может перехватить данные, передаваемые из А в В. По-прежнему ничто не мешает ему отправлять в адрес А сфальсифицированные датаграммы от имени В, но ответные пакеты А будет отправлять узлу В, минуя злоумышленника. Важным обстоятельством в этих условиях является то, имеет ли узел Х возможность подслушивать эти ответные пакеты, или же злоумышленник вынужден работать вслепую.
Имперсонация без обратной связи
Рассмотрим самый сложный случай: перехват и прослушивание данных, отправляемых из А в В невозможны. Этот случай (рис. 9.4) является наиболее общим: узел Х находится в сети, не имеющей никакого отношения к узлам А и В и не лежащей между ними (А и В могут находиться как в одной, так и в разных сетях).

Рис. 9.4. Имперсонация без обратной связи
Подчеркнем, что имперсонация без обратной связи имеет смысл лишь тогда, когда злоумышленнику для достижения своей цели достаточно только передать данные на узел А от имени узла В, и последующий ответ узла А уже не имеет значения. Классическим примером такой атаки является отправка злоумышленником на порт сервера Rlogin TCP-сегмента, содержащего какую-либо команду операционной системе узла А. Узел А выполняет эту команду, полагая, что она поступила с узла В.
Если имперсонация UDP-сообщений без обратной связи остается тривиальной, злоумышленник должен только сфабриковать датаграмму, адресованную от узла В узлу А, и отправить ее по назначению, то в случае с TCP все обстоит не так просто. Прежде чем отправить узлу А сегмент с данными, узел Х должен установить с ним соединение от имени узла В. Напомним, как происходит установление соединения: узел Х от имени В отправляет в А сегмент с битом SYN, где указывает начальный номер ISN(В). Узел А отвечает узлу В SYN-сегментом, в котором подтверждает получение предыдущего сегмента, и устанавливает свой начальный номер ISN(A). Этот сегмент злоумышленник никогда не получит.
Здесь возникает две проблемы: во-первых, узел В, получив от А ответ на SYN-сегмент, который он никогда не посылал, отправит узлу А сегмент с битом RST, тем самым сводя к нулю усилия злоумышленника. Во-вторых, узел Х все равно не сможет отправить в А следующий сегмент (как раз это должен быть сегмент с данными), потому что в этом сегменте узел Х должен подтвердить получение SYN-сегмента от А, то есть поместить в поле ACK SN заголовка своего сегмента значение ISN(A)+1. Но злоумышленник не знает номера ISN(A), потому что соответствующий сегмент ушел к узлу В.
Первая проблема решается относительно просто: злоумышленник проводит против узла В атаку типа «отказ в обслуживании» с тем расчетом, чтобы узел В не был способен обрабатывать сегменты, приходящие из А. Например, можно поразить узел В шквалом SYN-сегментов от несуществующих узлов1 (подробнее об отказах в обслуживании см. п. ). Впрочем, к облегчению злоумышленника, может оказаться, что узел В просто выключен.
Для решения второй проблемы злоумышленник должен уметь предсказывать значения ISN(A). Если операционная система узла А использует какую-либо функцию для генерации значений ISN (например, линейную зависимость от показания системных часов), то последовательно открыв несколько пробных соединений с узлом А и проанализировав присылаемые в SYN-сегментах от А значения ISN, злоумышленник может попытаться установить эту зависимость опытным путем.
Хорошая реализация TCP должна использовать случайные числа для значений ISN (более подробное обсуждение этого вопроса можно найти в RFC-1948). Несмотря на кажущуюся простоту этого требования, проблема с угадыванием номеров ISN остается актуальной и по сей день2.
2 В марте 2001 г. была опубликована информация о предсказуемости номеров ISN в Cisco IOS. См. также бюллетени CERT "Vulnerability Note VU#498440", "", работы [] и [].
Итак, приведем схему атаки для имперсонации TCP-соединения без обратной связи (рис. 9.5).

Рис. 9.5. Схема атаки с имперсонацией TCP-соединения без обратной связи
Злоумышленник выводит из строя узел В. Злоумышленник делает несколько пробных попыток установить соединения с уз-лом А с целью получить от А последовательность значений ISN(A). Сразу после по-ступления SYN-сегмента от А злоумышленник разрывает наполовину установленное соединение посылкой сегмента с флагом RST. Проанализировав полученные значения ISN(A), злоумышленник определяет закон формирования этих значений. Злоумышленник отправляет в А SYN-сегмент от имени В. Узел А отвечает узлу В свои SYN-сегментом, подтверждающим получение SYN-сегмента от В, и указывает значение ISN(A) для этого соединения. Злоумышленник не видит этого сегмента. На основе ранее полученных данных злоумышленник предсказывает значение ISN(A) и отправляет в А сегмент от имени В, содержащий подтверждение ISN(A)+1 и данные для прикладного процесса3. Получив этот сегмент, узел А считает соединение с В установленным и передает поступившие данные прикладному процессу. Цель атаки достигнута. Данные могут быть, например, командой, которую узел А выполняет, потому что она поступила от доверенного узла В.
3 Узел Х может отправить подряд несколько сегментов с данными, пока он остается в рамках объявленного узлом А окна, размер которого он выяснил во время пробных соединений.
Узел А отправляет подтверждение получения данных и, возможно, свои данные в узел В. Злоумышленник этих сегментов не получит, но они его (по условиям задачи) и не интересуют. Чтобы корректно закрыть соединение, злоумышленник может вслепую отправить в узел А от имени узла В подтверждение получения одного октета (ACK SN=ISN(A)+2), а следом выслать сегмент с флагом FIN. Таким образом канал передачи данных от узла X (он же В) к узлу А корректно закрыт. Для полного закры-тия соединения злоумышленник должен подтвердить получение FIN-сегмента от А (равно как и всех данных, которые этому сегменту предшествовали) - разумеется, он этого сделать не может, потому что в общем случае ни объем этих данных, ни время отправки FIN-сегмента из А ему не известны. Но поскольку данные, переда-ваемые из А в В для злоумышленника ценности не имеют, он просто отправляет в А сегмент с флагом RST, тем самым полностью ликвидируя соединение. Злоумышленник завершает атаку "отказ в обслуживании" против узла В.
Инкапсуляция и обработка пакетов
При продвижении пакета данных по уровням сверху вниз каждый новый уровень добавляет к пакету свою служебную информацию в виде заголовка и, возможно, трейлера (информации, помещаемой в конец сообщения). Эта операция называется инкапсуляцией данных верхнего уровня в пакете нижнего уровня. Служебная информация предназначается для объекта того же уровня на удаленном компьютере, ее формат и интерпретация определяются протоколом данного уровня.
Разумеется, данные, приходящие с верхнего уровня, могут на самом деле представлять собой пакеты с уже инкапсулированными данными еще более верхнего уровня.
С другой стороны, при получении пакета от нижнего уровня он разделяется на заголовок (трейлер) и данные. Служебная информация из заголовка (трейлера) анализируется и в соответствии с ней данные, возможно, направляются одному из объектов верхнего уровня. Тот в свою очередь рассматривает эти данные как пакет со своей служебной информацией и данными для еще более верхнего уровня, и процедура повторяется, пока пользовательские данные, очищенные от всей служебной информации, не достигнут прикладного процесса.
Возможно, что пакет данных не будет доведен до самого верхнего уровня, например, в случае, если данный компьютер представляет собой промежуточную станцию на пути между отправителем и получателем. В этом случае объект соответствующего уровня при анализе служебной информации заметит, что пакет на этом уровне адресован не ему (хотя с точки зрения нижележащих уровней он был адресован именно этому компьютеру). Тогда объект выполнит необходимые действия для перенаправления пакета к месту назначения или возврата отправителю с сообщением об ошибке, но в любом случае не будет продвигать данные на верхний уровень.
Модель OSI предложена достаточно давно, однако протоколы, на ней основанные, используются редко, во-первых, в силу своей не всегда оправданной сложности, во-вторых , из-за существования хотя и не соответствующих строго модели OSI, но уже хорошо зарекомендовавших себя стеков протоколов (например, TCP/IP).
Поэтому модель OSI стоит рассматривать, в основном, как опорную базу для классификации и сопоставления протокольных стеков.
IP-адреса
IP-адрес является уникальным 32-битным идентификатором IP-интерфейса в Интернет. Часто говорят, что IP-адрес присваивается узлу сети (например, хосту); это верно в случае, если узел является хостом с одним IP-интерфейсом, иначе следует уточнить, об адресе какого именно интерфейса данного узла идет речь. Далее для краткости там, где это не вызовет неверного толкования, вместо адреса IP-интерфейса узла сети говорится об IP-адресе хоста.
IP-адреса принято записывать разбивкой всего адреса по октетам, каждый октет записывается в виде десятичного числа, числа разделяются точками. Например, адрес 10100000010100010000010110000011
записывается как 10100000.01010001.00000101.10000011 = 160.81.5.131.
IP-адрес хоста состоит из номера IP-сети, который занимает старшую область адреса, и номера хоста в этой сети, который занимает младшую часть. Положение границы сетевой и хостовой частей (обычно оно характеризуется количеством бит, отведенных на номер сети) может быть различным, определяя различные типы IP-адресов, которые рассматриваются ниже.
Истощение ресурсов узла или сети
Smurf
Атака smurf состоит в генерации шквала ICMP Echo-ответов, направленных на атакуемый узел. Для создания шквала злоумышленник направляет несколько сфальсифицированных Echo-запросов от имени жертвы на широковещательные адреса нескольких сетей, которые выступят в роли усилителей. Потенциально большое число узлов, находящихся в сетях-усилителях и поддерживающих обработку широковещательных Echo-запросов, одновременно отправляет ответы на атакуемый узел. В результате атаки сеть, в которой находится жертва, сам атакуемый узел, а также и сети-усилители могут быть временно заблокированы шквалом ответных сообщений. Более того, если атакуемая организация оплачивает услуги провайдера Интернета пропорционально полученному трафику, ее расходы могут существенно возрасти.
Для атакуемого узла и его сети не существует адекватных способов защиты от этой атаки. Очевидно, что блокирование ICMP-сообщений маршрутизатором на входе в атакуемую сеть не является удовлетворительным решением проблемы, поскольку при этом канал, соединяющий организацию с провайдером Интернета, остается подверженным атаке, а именно он, как правило, является наиболее узким местом при работе организации с Интернетом. И поскольку ICMP-сообщения были доставлены провайдером на маршрутизатор организации, они подлежат оплате.
Атаку smurf можно обнаружить путем анализа трафика на маршрутизаторе или в сети. Признаком атаки является также полная загрузка внешнего канала и сбои в работе хостов внутри сети. При обнаружении атаки следует определить адреса отправителей сообщений Echo Reply (это сети-усилители), установить в регистратуре Интернета их административную принадлежность и обратиться к администраторам с просьбой принять меры защиты для усилителей, описываемые ниже. Администратор атакуемой сети также должен обратиться к своему провайдеру с извещением об атаке; провайдер может заблокировать передачу сообщений Echo Reply в канал атакуемой организации.
Для устранения атак smurf защитные меры могут быть предприняты как потенциальными усилителями, так и администраторами сетей, в которых может находиться злоумышленник. Это:
запрет на маршрутизацию датаграмм с широковещательным адресом назначения между сетью организации и Интернетом; запрет на обработку узлами Echo-запросов, направленных на широковещательный адрес; запрет на маршрутизацию датаграмм, направленных из внутренней сети (сети организации) в Интернет, но имеющих внешний адрес отправителя.
В этой связи отметим, что каждая сеть может оказаться в любой из трех ролей: сети злоумышленника, усилителя или жертвы, поэтому, принимая меры по защите других сетей, вы можете надеяться, что администраторы других сетей достаточно квалифицированы и принимают те же самые меры, которые могут защитить вас.
SYN flood и Naptha
Распространенная атака SYN flood (она же Neptune) состоит в посылке злоумышленником SYN-сегментов TCP на атакуемый узел в количестве большем, чем тот может обработать одновременно (это число невелико — обычно несколько десятков).
При получении каждого SYN-сегмента модуль TCP создает блок TCB, то есть выделяет определенные ресурсы для обслуживания будущего соединения, и отправляет свой SYN-сегмент. Ответа на него он никогда не получит. (Чтобы замести следы и не затруднять себя игнорированием ответных SYN-сегментов, злоумышленник будет посылать свои SYN-сегменты от имени несуществующего отправителя или нескольких случайно выбранных несуществующих отправителей.) Через несколько минут модуль TCP ликвидирует так и не открытое соединение, но если одновременно злоумышленник сгенерирует большое число SYN-сегментов, то он заполнит все ресурсы, выделенные для обслуживания открываемых соединений, и модуль TCP не сможет обрабатывать новые SYN-сегменты, пока не освободится от запросов злоумышленника. Постоянно посылая новые запросы, злоумышленник может продолжительно удерживать жертву в блокированном состоянии. Чтобы снять воздействие атаки, злоумышленник посылает серию сегментов с флагом RST, которые ликвидируют полуоткрытые соединения и освобождают ресурсы атакуемого узла.
Целью атаки является приведение узла (сервера) в состояние, когда он не может принимать запросы на открытие соединений. Однако некоторые недостаточно хорошо спроектированные системы в результате атаки не только перестают открывать новые соединения, но и не могут поддерживать уже установленные, а в худшем случае — зависают.
Атаку SYN flood можно определить как удерживание большого числа соединений на атакуемом узле в состоянии SYN-RECEIVED. В последнее время , что большое число соединений в состояниях ESTABLISHED и FIN-WAIT-1 также вызывает отказы в обслуживании на сервере. Эти отказы выражаются по-разному в различных системах: переполнение таблиц процессов (process table attack) и файловых дескрипторов, невозможность открытия новых и обрыв установленных соединений, зависание серверных процессов или всей системы.
Подобные бреши в безопасности стеков TCP/IP получили собирательное название Naptha. Подчеркнем, что выполнение атаки Naptha не требует от злоумышленника тех же затрат по поддержанию TCP-соединений, что и от атакуемого узла. Злоумышленник не создает блоков TCB, не отслеживает состояния соединений и не запускает прикладных процессов; при получении TCP-сегмента от атакуемого узла злоумышленник просто генерирует приемлемый ответ, основываясь на флагах и значениях полей заголовка принятого сегмента, чтобы перевести или удержать TCP-соединение на атакуемом узле в нужном состоянии. Разумеется, злоумышленник, чтобы скрыть себя, будет посылать сегменты от имени несуществующего (выключенного) узла и принимать ответные сегменты от атакуемого узла методом прослушивания.
Полной защиты от описанных атак не существует. Чтобы уменьшить подверженность узла атаке администратор должен использовать программное обеспечение, позволяющее установить максимальное число открываемых соединений, а также список разрешенных клиентов (если это возможно)1. Только необходимые порты должны быть открыты (находиться в состоянии LISTEN), остальные сервисы следует отключить. Операционная система должна иметь устойчивость к атакам Naptha — при проведении атаки не должно возникать отказа в обслуживании пользователей и сервисов, не имеющих отношения к атакуемым.
Должен также проводиться анализ трафика в сети для выявления начавшейся атаки, признаком чего является большое число однотипных сегментов, и блокирование сегментов злоумышленника фильтром на маршрутизаторе. Маршрутизаторы Cisco предлагают механизм TCP Intercept, который служит посредником между внешним TCP-клиентом и TCP-сервером, находящимся в защищаемой сети. При получении SYN-сегмента из Интернета маршрутизатор не ретранслирует его во внутреннюю сеть, а сам отвечает на этот сегмент от имени сервера. Если соединение с клиентом устанавливается, то маршрутизатор устанавливает соединение с сервером от имени клиента и при дальнейшей передаче сегментов в этом соединении действует как прозрачный посредник, о котором ни клиент, ни сервер не подозревают. Если ответ от клиента за определенное время так и не поступил, то оригинальный SYN-сегмент не будет передан получателю.
Если SYN-сегменты начинают поступать в большом количестве и на большой скорости, то маршрутизатор переходит в «агрессивный» режим: время ожидания ответа от клиента резко сокращается, а каждый вновь прибывающий SYN-сегмент приводит к исключению из очереди одного из ранее полученных SYN-сегментов. При снижении интенсивности потока запросов на соединения маршрутизатор возвращается в обычный, «дежурный» режим.
Отметим, что применение TCP Intercept фактически переносит нагрузку по борьбе с SYN-атакой с атакуемого хоста на маршрутизатор, который лучше подготовлен для этой борьбы.
UDP flood
Атака состоит в затоплении атакуемой сети шквалом UDP-сообщений. Для генерации шквала злоумышленник использует сервисы UDP, посылающие сообщение в ответ на любое сообщение. Примеры таких сервисов: echo (порт 7) и chargen (порт 19). От имени узла А (порт отправителя —7) злоумышленник посылает сообщение узлу В (порт получателя — 19). Узел В отвечает сообщением на порт 7 узла А, который возвращает сообщение на порт 19 узла В, и так далее до бесконечности (на самом деле, конечно, до тех пор, пока сообщение не потеряется в сети). Интенсивный UDP-трафик затрудняет работу узлов А и В и может создать затор в сети.
UDP-сервис echo может быть также использован для выполнения атаки fraggle. Эта атака полностью аналогична smurf, однако менее популярна у злоумышленников из-за меньшей эффективности.
Для защиты от атак типа UDP flood следует отключить на узлах сети все неиспользуемые сервисы UDP (отметим, что вам вряд ли когда-нибудь вообще понадобятся сервисы echo и chargen). Фильтр на маршрутизаторе-шлюзе должен блокировать все UDP-сообщения кроме тех, что следуют на разрешенные порты (например, порт 53 — DNS).
В заключение этого подпункта отметим, что использование промежуточных систем для реализации атак, связанных с генерацией направленного шквала пакетов (типа smurf), оказалось весьма плодотворной идеей для злоумышленников. Такие атаки называются распределенными (Distributed DoS, DDoS). Для их реализации злоумышленниками создаются программы-демоны, захватывающие промежуточные системы и впоследствии координирующие создание направленных на атакуемый узел шквалов пакетов (ICMP Echo, UDP, TCP SYN). Захват систем производится путем использования ошибок в программах различных сетевых сервисов. Примеры таких распределенных систем — TFN, trin001 (см. ).
Ложные DHCP-клиенты
Атака состоит в создании злоумышленником большого числа сфальсифицированных запросов от различных несуществующих DHCP-клиентов. Если DHCP-сервер выделяет адреса динамически из некоторого пула, то все адресные ресурсы могут быть истрачены на фиктивных клиентов, вследствие чего легитимные хосты не смогут сконфигурироваться и лишатся доступа в сеть.
Для защиты от этой атаки администратору следует поддерживать на DHCP-сервере таблицу соответствия MAC- и IP-адресов (если это возможно); сервер должен выдавать IP-адреса в соответствии с этой таблицей.
Изменение конфигурации или состояния узла
Перенаправление трафика на несуществующий узел
В п. были рассмотрены различные методы перехвата трафика злоумышленником. Любой из этих методов может быть использован также и для перенаправления посылаемых атакуемым узлом (или целой сетью) данных «в никуда», результатом чего будет потеря связи жертвы с выбранными злоумышленником узлами или сетями.
В случае с протоколом BGP злоумышленнику достаточно сбросить TCP-соединение между BGP-соседями (см. ниже), чтобы каждый из соседей удалил маршруты, полученные от другого, и распространил информацию о недостижимости этих маршрутов другим своим соседям. К счастью, применение BGP-аутентификации, которая, напомним, работает на уровне TCP, существенно затрудняет эту задачу, поскольку злоумышленник, не зная пароля, не может сфабриковать приемлемый RST-сегмент.
В дополнение отметим, что при использовании в сети любого протокола маршрутизации злоумышленник может генерировать сфальсифицированные сообщения протокола, содержащие некорректные или предельные значения некоторых полей (порядковых номеров, возраста записи, метрики), что приведет к нарушениям в системе маршрутизации (см., например, [], []).
Навязывание длинной сетевой маски
Если хост получает маску для своей сети через ICMP-сообщение Address Mask Reply, то, сформировав ложное сообщение с длинной маской (например, 255.255.255.252), злоумышленник существенно ограничит способность атакуемого хоста к соединениям (коннективность). Если в «суженной» злоумышленником сети не окажется маршрутизатора по умолчанию, то жертва сможет посылать данные только узлам, попадающим под навязанную маску.
В настоящее время хосты динамически конфигурируются с помощью протокола DHCP (что, впрочем, открывает перед злоумышленником более широкие возможности: выдав себя за DHCP-сервер, злоумышленник может полностью исказить настройки стека TCP/IP атакуемого хоста). Тем не менее, следует проверить, как система отреагирует на получение ICMP Address Mask Reply.
Десинхронизация TCP-соединения
Десинхронизация TCP-соединения была рассмотрена в п. . Очевидно, что если после выполнения десинхронизации злоумышленник не будет функционировать в качестве посредника, то передача данных по атакованному TCP-соединению будет невозможна.
Изменение состояния RIP-системы
Выясним, что происходит в случае, когда состояние системы неожиданно изменяется, например, маршрутизатор ?
отключается от сети А.

Рис. 4.1.2. Изменение состояния RIP-системы
Узел ?
обнаруживает свое отсоединение от сети А и меняет таблицу маршрутов, устанавливая бесконечное расстояние до всех сетей, ранее достижимых через маршрутизаторы, подключенные к сети А (то есть ?
). В протоколе RIP значение бесконечности равно 16.
A=16a
?
B=1a
?
C=16a
?
D=16a
?
Е=2a
?
Вектор расстояний, построенный на основании этой таблицы, рассылается в сеть В, чтобы маршрутизаторы, направлявшие свои данные через ?
в ставшие недоступными сети, если таковые маршрутизаторы существуют, соответственно изменили свои маршрутные таблицы.
Допустим, в узле ?
имелась следующая таблица маршрутов:
A=2a
?
B=1a
?
C=1a
?
D=2a
?
Е=1a
?
Узел ?
периодически и широковещательно рассылает в сети В, С, Е свой вектор расстояний (А=2,В=1,С=1,D=2,E=1). Узел ?
получает этот вектор, увеличивает расстояния на 1: (А=3,В=2,С=2,D=3,E=2) и замечает, что расстояния А=3, С=2 и D=3 меньше бесконечностиследовательно, соответствующие записи таблицы маршрутов модифицируются и она принимает вид:
A=3a
?
B=1a
?
C=2a
?
D=3a
?
Е=2a
?
Таким образом, узел ?
построил маршруты в обход поврежденного участка и восстановил достижимость всех сетей.
Классовая модель
В классовой модели IP-адрес может принадлежать к одному из четырех классов сетей. Каждый класс характеризуется определенным размером сетевой части адреса, кратным восьми; таким образом, граница между сетевой и хостовой частями IP-адреса в классовой модели всегда проходит по границе октета. Принадлежность к тому или иному классу определяется по старшим битам адреса.
Класс А. Старший бит адреса равен нулю. Размер сетевой части равен 8 битам. Таким образом, может существовать всего примерно 27 сетей класса А, но каждая сеть обладает адресным пространством на 224 хостов. Так как старший бит адреса нулевой, то все IP-адреса этого класса имеют значение старшего октета в диапазоне 0— 127, который является также и номером сети.
Класс В. Два старших бита адреса равны 10. Размер сетевой части равен 16 битам. Таким образом, может существовать всего примерно 214 сетей класса В, каждая сеть обладает адресным пространством на 216 хостов. Значения старшего октета IP-адреса лежат в диапазоне 128 — 191, при этом номером сети являются два старших октета.
Класс С. Три старших бита адреса равны 110. Размер сетевой части равен 24 битам. Количество сетей класса С примерно 221, адресное пространство каждой сети рассчитано на 254 хоста. Значения старшего октета IP-адреса лежат в диапазоне 192 - 223, а номером сети являются три старших октета.
Класс D. Сети со значениями старшего октета IP-адреса 224 и выше. Зарезервированы для специальных целей. Некоторые адреса используются для мультикастинга - передачи дейтаграмм группе узлов сети, например:
224.0.0.1 - всем хостам данной сети;
224.0.0.2 - всем маршрутизаторам данной сети;
224.0.0.5 - всем OSPF-маршрутизаторам;
224.0.0.6 - всем выделенным (designated) OSPF-маршрутизаторам;
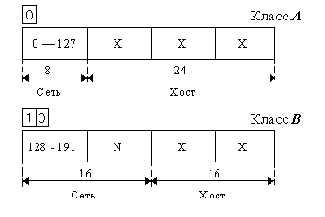

Рис. 2.2.1. Классы IP-адресов
В классе А выделены две особые сети, их номера 0 и 127. Сеть 0 используется при маршрутизации как указание на маршрут по умолчанию (см. п. 2.3) и в других особых случаях.
IP-интерфейс с адресом в сети 127 используется для адресации узлом себя самого (loopback, интерфейс обратной связи). Интерфейс обратной связи не обязательно имеет адрес в сети 127 (особенно у маршрутизаторов), но если узел имеет IP-интерфейс с адресом 127.0.0.1, то это - интерфейс обратной связи. Обращение по адресу loopback-интерфейса означает связь с самим собой (без выхода пакетов данных на уровень доступа к среде передачи); для протоколов на уровнях транспортном и выше такое соединение неотличимо от соединения с удаленным узлом, что удобно использовать, например, для тестирования сетевого программного обеспечения.
В любой сети (это справедливо и для бесклассовой модели, которую мы рассмотрим ниже) все нули в номере хоста обозначают саму сеть, все единицы - адрес широковещательной передачи (broadcast).
Например, 194.124.84.0 - сеть класса С, номер хоста в ней определяется последним октетом. При отправлении широковещательного сообщения оно отправляется по адресу 194.84.124.255. Номера, разрешенные для присваивания хостам: от 1 до 254 (194.84.124.1 — 194.84.124.254), всего 254 возможных адреса.
Другой пример: в сети 135.198.0.0 (класс В, номер хоста занимает два октета) широковещательный адрес 135.198.255.255, диапазон номеров хостов: 0.1 — 255.254 (135.198.0.1 — 135.198.255.254).
Конфигурирование RIP
Общий порядок действий при конфигурировании модуля RIP следующий:
указать, какие сети, подключенные к маршрутизатору, будут включены в RIP-систему;
указать "nonbroadcast networks", т.е. сети со статической маршрутизацией (например, тупиковые сети, подсоединенные к внешнему миру через единственный шлюз), куда не нужно рассылать векторы расстояний;
указать "permanent routes"- статические маршруты, например, маршрут по умолчанию за пределы автономной системы.
Конфликты маршрутных политик
Рассмотрим пример (рис. 7.4.2).

Рис. 7.4.2. Автономные системы
Предположим, автономная система 5 формирует маршрут до сетей автономной системы 1. Политическая ситуация такова, что АС3 берет с АС5 существенно большие деньги за транзитный трафик, чем АС4 и АС2, поэтому АС5 формирует политику приема маршрутов, в соответствии с которой на маршруты, полученные от АС3, но ведущие в сети других АС (АС1 и АС2), назначается меньший приоритет, чем на маршруты в те же сети, но полученные от АС4. Таким образом, АС5 ожидает, что ее маршрутизатор установит маршрут в АС1 как 5-4-2-1 (естественно, что к сетям самой АС3 маршрут будет кратчайший: 5-3).
Однако выясняется, что маршрутизатор АС5 выбрал маршрут 5-3-1, то есть политика не действует, хотя все настройки в АС5 произведены верно. Дело в том, что к четвертой системе АС5 относится гораздо более дружелюбно и тарифицирует ее трафик по обычным расценкам, вследствие чего для АС4 нет разницы, как добираться в АС1: 4-3-1 или 4-2-1. АС4 по какой-то причине выбирает маршрут 4-3-1, и поскольку маршрутом 4-2-1 она не пользуется, она его и не объявляет. В результате у АС5 нет вариантов: эта автономная система просто не получает анонс маршрута 4-2-1 и вынуждена использовать маршрут 3-1.
Для решения проблемы АС5 должна обратиться к АС4 с просьбой установить политику приема маршрутов так, чтобы использовать маршрут 4-2-1. Однако, если АС3 тарифицирует трафик АС4 не просто по обычным тарифам, а со скидками, то для АС4 невыгодно вносить требуемые изменения, и АС5 остается перед выбором: либо дорого платить за трафик через АС3, либо не иметь связи с АС1.
Описанная ситуация представляет собой конфликт интересов, который не может быть разрешен программным обеспечением протокола BGP. Отметим, что в этом нет вины самого протокола; мы наблюдаем здесь побочный эффект технологии маршрутизации "только по адресу получателя", используемой протоколом IP.
Литература
[Bellovin] // Computer Communications Review, Vol. 19, No. 2, pp. 32-48, April 1989.
[McDanel] McDanel, B. "TCP Timestamping - Obtaining System Uptime Remotely" // Bugtraq, March 11, 2001.
[Zalewski] , April 2001.
[Newsham] , February 2001.
[Joncheray] // Proceedings of 5th USENIX UNIX Security Symposium, June 1995.
[Savage] Savage S., Cardwell N., Wetherall D., Anderson T. "TCP Congestion Control with a Misbehaving Receiver" // ACM Computer Communications Review, Vol. 29, No. 5, pp. 71-78, October 1999.
[Moore] // Proceedings of 10th USENIX UNIX Security Symposium, August 2001.
[Vetter] Vetter B., Wang F., Wu S.F. "An experimental study of insider attacks on the OSPF routing protocol" // IEEE International Conference on Network Protocol (ICNP), pp. 293-300, Atlanta, USA, October 1997.
[Wang] Wang F., Gong F., Wu S.F. Narayan R. "Intrusion Detection for Link State Routing Protocol Through Integrated Network Management" // Proc. of Eighth International Con-ference on Computer Communications and Networks, Boston, October 1999.
LOCAL_PREF
LOCAL_PREF (тип 5) – необязательный атрибут, устанавливающий для данной АС приоритет данного маршрута среди всех маршрутов к заявленной сети, известных внутри АС. Атрибут вычисляется каждым пограничным маршрутизатором для каждого присланного ему по EBGP маршрута и потом распространяется вместе с этим маршрутом по IBGP в пределах данной АС. Способ вычисления значения атрибута определяется политикой приема маршрутов (по умолчанию берется во внимание только длина AS_PATH). LOCAL_PREF используется для согласованного между маршрутизаторами одной АС выбора маршрута из нескольких вариантов.
Ложные ARP-ответы
Для перехвата трафика между узлами А и В, расположенными в одной IP-сети, злоумышленник использует протокол ARP. Он рассылает сфальсифицированные ARP-сообщения так, что каждый из атакуемых узлов считает MAC-адрес злоумышленника адресом своего собеседника (рис. 2.78).
Рис. 9.1. Схема ARP-атаки
План атаки:
1. Злоумышленник определяет MAC-адреса узлов А и В:
% ping IP(A); ping IP(B); arp —a
2. Злоумышленник конфигурирует дополнительные логические IP-интерфейсы на своем компьютере, присвоив им адреса А и В и отключив протокол ARP для этих интерфейсов, чтобы их не было «слышно» в сети, например:
# ifconfig hme0:1 inet IP(A) -arp # ifconfig hme0:2 inet IP(B) -arp
Затем он устанавливает статическую ARP-таблицу:
# arp —s IP(A) MAC(A) # arp —s IP(B) MAC(B)
и разрешает ретрансляцию IP-датаграмм (переводит компьютер в режим маршрутизатора).
3. Злоумышленник отправляет на МАC-адрес узла А кадр со сфабрикованным ARP-ответом, в котором сообщается, что IP адресу В соответствует MAC-адрес Х. Аналогично узлу В сообщается, что IP адресу А соответствует тот же MAC-адрес Х (рис. 9.1). Для формирования сообщений можно использовать библиотеку libnet. Так как ARP — протокол без сохранения состояния, то узлы А и В примут ARP-ответы, даже если они не посылали запросов. Далее злоумышленник периодически (достаточно это делать раз в 20–40 секунд) повторяет посылку сфальсифицированных ARP-ответов для обновления сфабрикованных записей в ARP-таблицах узлов А и В, чтобы удерживать эти узлы в неведении относительно истинных адресов и не дать им сформировать соответствующие ARP-запросы.
4. Введенные в заблуждение узлы А и В пересылают свой трафик через узел Х, полагая, что сообщаются друг с другом непосредственно. Злоумышленник может просто прослушивать трафик или изменять передаваемые данные в своих интересах.
Узел В может быть шлюзом сети, в которой находится узел А. В этом случае злоумышленник может перехватывать весь трафик между узлом А и Интернетом.
Также злоумышленник может вообще не передавать кадры узла А узлу В, а выдавать себя за узел В, фабрикуя ответы от его имени и отсылая их в А (см. также п. ).
Разделение сети на сегменты с помощью коммутаторов, очевидно, не является препятствием для описанной ARP-атаки.
Отметим, что в сфабрикованных ARP-ответах злоумышленник может вместо своего MAC-адреса указать несуществующий адрес Ethernet. Впоследствии он может извлекать из сети кадры, направленные на этот адрес путем прослушивания сети или перепрограммирования MAC-адреса своей сетевой карты. Это потребует несколько больших усилий, но взамен злоумышленник сможет практически полностью замести следы, поскольку его собственный MAC-адрес уже нигде не фигурирует.
Для обнаружения ARP-атак администратор должен вести базу данных соответствия MAC- и IP-адресов всех узлов сети и использовать программу arpwatch, которая прослушивает сеть и уведомляет администратора о замеченных нарушениях. Если сеть разделена на сегменты коммутаторами, то администратор должен настроить их таким образом, чтобы в сегмент, где находится станция администратора, перенаправлялись кадры из всех сегментов сети вне зависимости от того, кому они предназначены.
Использование статических ARP-таблиц, по крайней мере — на ключевых узлах (серверах, маршрутизаторах), защитит их от ARP-атаки, правда, за счет накладных расходов на поддержку этих таблиц в актуальном состоянии.
Пользователю на атакуемом хосте, не снабженном статической ARP-таблицей, крайне сложно заметить, что он подвергся ARP-атаке, поскольку представляется маловероятным, что пользователь помнит MAC-адреса других узлов своей сети и периодически проверяет ARP-таблицу своего компьютера. Возможно, что операционная система отслеживает изменения в ARP-таблице и вносит в лог-файл записи вида «arp info for 0x11223344 overwritten by 01:02:03:04:05:06», однако, в общем случае, для отслеживания ARP-атак следует полагаться на администратора сети и программу arpwatch.
Ложные дубликаты подтверждений
Опять рассмотрим ситуацию, когда узел А находится в медленном старте после установления соединения. А отправляет в В один сегмент (SN=1–1000), но узел В, вместо того чтобы ответить подтверждением ACK SN=1001, отвечает серией сфабрикованных подтверждений ACK SN=1 (рис. 9.15).
Получение дубликатов подтверждений включает на узле А алгоритмы быстрой повторной передачи (fast retransmit) и быстрого восстановления (fast recovery). Последний из них представляет в данном случае особый интерес. Напомним, что алгоритм быстрого восстановления базируется на предположении, что каждый полученный дубликат предыдущего подтверждения, кроме того, что говорит о потере сегмента, также подразумевает, что какой-то другой полноразмерный сегмент покинул сеть. Вследствие этого окно cwnd, измеряемое в полноразмерных сегментах, временно увеличивается на число полученных дубликатов, пока не придет подтверждение, отличное от предыдущих.
Поскольку сам дубликат подтверждения не несет никакой информации о том, получение какого именно сегмента вызвало отправку данного дубликата, ничто не может уберечь отправителя от ложных дубликатов подтверждений, сгенерированных получателем. Таким образом, получатель заставляет отправителя необоснованно увеличить окно cwnd и ускорить отправку данных.
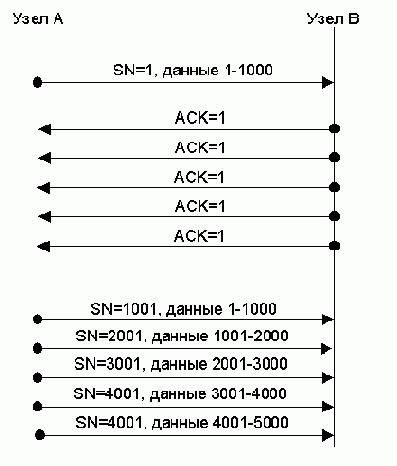
Рис. 9.15 Ложные дубликаты подтверждений
Фактически узел А будет отправлять данные со скоростью, с которой В генерирует дубликаты подтверждений. В какой-то момент в узле А сработает таймер повторной передачи для сегмента SN=1–1000, поскольку он так и не был подтвержден. Узел В отреагирует на это посылкой кумулятивного подтверждения на все полученные к этому моменту данные и переключится на генерацию ложных дубликатов этого последнего подтверждения, снова вынуждая отправителя необоснованно увеличивать cwnd.
Маршрутизация
Процесс маршрутизации дейтаграмм состоит в определении следующего узла (next hop) в пути следования дейтаграммы и пересылки дейтаграммы этому узлу, который является либо узлом назначения, либо промежуточным маршрутизатором, задача которого — определить следующий узел и переслать ему дейтаграмму. Ни узел-отправитель, ни любой промежуточный маршрутизатор не имеют информации о всей цепочке, по которой пересылается дейтаграмма; каждый маршрутизатор, а также узел-отправитель, основываясь на адресе назначения дейтаграммы, находит только следующий узел ее маршрута.
Маршрутизация дейтаграмм осуществляется на уровне протокола IP.
Маршрутизация выполняется на основе данных, содержащихся в таблице маршрутов. Строка в таблице маршрутов состоит из следующих полей:
адрес сети назначения; адрес следующего маршрутизатора (то есть узла, который знает, куда дальше отправить дейтаграмму, адресованную в сеть назначения); вспомогательные поля.
Таблица может составляться вручную или с помощью специализированных протоколов. Каждый узел сети, в том числе и хост, имеет таблицу маршрутов, хотя бы самую простую.
Маршрутизация групповых дейтаграмм
Задачей этого раздела является описание методов маршрутизации групповых дейтаграмм, то есть продвижения их через систему сетей от отправителя к членам группы. После описания методов маршрутизации в п. рассмотрены использующие их протоколы.
