4.4BSD
4.4BSD
4.4BSD это первый релиз Berkeley, который предоставлял динамическую конфигурацию большого количества параметров ядра. При этом использовалась команда sysctl(8) . Имена параметров были выбраны так, чтобы напоминать имена MIB из SNMP. Просмотреть параметры можно следующим образом:
vangogh % sysctl net.inet.ip.forwarding
net.inet.ip.forwarding = 1
Чтобы изменить параметр (обязательно с привилегиями суперпользователя), можно сделать следующее:
vangogh # sysctl -w net.inet.ip.ttl=128
Могут быть изменены следующие параметры.
net.inet.ip.forwarding
Если равно 0 (по умолчанию), IP датаграммы не перенаправляются. Если равно 1, перенаправление включено.net.inet.ip.redirect
Если равно 1 (по умолчанию), хост будет отправлять ICMP перенаправления при перенаправлении IP датаграмм. Если равно 0, ICMP перенаправления не отправляются.net.inet.ip.ttl
Значение TTL по умолчанию для TCP и UDP. По умолчанию 64.net.inet.icmp.maskrepl
Если равно 0 (по умолчанию), хост не отвечает на ICMP запросы маски адреса. Если равно 1 - отвечает.net.inet.udp.checksum
Если равно 1 (по умолчанию), рассчитывается контрольная сумма UDP для исходящих UDP датаграмм, а для входящих UDP датаграмм, если контрольная сумма не равна нулю, она проверяется. Если равно 0, исходящие UDP датаграммы не содержат контрольной суммы, и не осуществляется проверка контрольной суммы для входящих UDP датаграмм, даже если отправитель рассчитал контрольную сумму.Помимо этого, большое количество переменных, которые мы описали раньше в этом приложении, находятся в различных файлах исходных текстов (tcp_keepidle, subnetsarelocal и так далее) и могут быть модифицированы.
Назад
Компания | Услуги | Для клиентов | Библиотека | Галерея | Cофт | Линки
На главную
BSD/386 Version 1.0
BSD/386 Version 1.0
Эта система является примером "классической" BSD конфигурации, которая используется, начиная с 4.2BSD. Так как вместе с системой распространяются исходные тексты, администратор может указать опции конфигурации, после чего необходимо пересобрать ядро. Существует два типа опций: константы, которые определяются в конфигурационном файле ядра (см. страницы помощи config(8)), и переменные, которые инициализируются в различных файлах С текста. Смелые и квалифицированные администраторы могут изменить значение этих С переменных в работающем ядре или в дисковом имидже ядра с использованием отладчика, чтобы не пересобирать ядро. Ниже приведены константы, которые могут быть изменены в конфигурационном файле ядра.
IPFORWARDING
Значение этой константы устанавливается в переменной ядра ipforwarding . Если равно 0 (по умолчанию), IP датаграммы не перенаправляются. Если равно 1, перенаправление включено.GATEWAY
Если эта константа определена, IPFORWARDING должна быть установлена в 1. Помимо того, определение этой константы вызывает увеличение определенных системных таблиц (ARP кэша и таблицы маршрутизации).SUBNETSARELOCAL
Значение этой константы устанавливает переменную ядра subnetsarelocal. Если равно 1 (по умолчанию), IP адрес назначения с тем же самым идентификатором сети, как и у посылающего хоста, но с другим идентификатором подсети, считается локальным. Если равно 0, только IP адреса назначения непосредственно подключенной подсети считаются локальными. Кратко это описано на рисунке Е.1.
| Идентификатор
сети |
Идентификатор
подсети |
subnetsarelocal | Комментарий | |
| 1 | 0 | |||
| одинаковый | одинаковый | локальный | локальный | всегда локальный |
| одинаковый | разный | локальный | нелокальный | зависит от конфигурации |
| разный | нелокальный | нелокальный | всегда нелокальный |
BSD Net/2 Source Code (глава 1
BSD Net/2 Source Code (глава 1, раздел "Реализации")
Исходный код BSD Net/2, который включает реализации ядра протоколов TCP/IP вместе со стандартными утилитами (клиент и сервер Telnet, клиент и сервер FTP, и так далее), можно получить с хоста ftp.uu.net в дереве директорий, начинающемся с systems/unix/bsd-sources.
Демон gated (глава 10, раздел
Демон gated (глава 10, раздел "Демоны маршрутизации в Unix")
Демон маршрутизации gated, о котором мы упоминали в разделе "Демоны маршрутизации в Unix" главы 10, находится на хосте ftp.gated.cornell.edu.
Демон обнаружения маршрутизаторов
Демон обнаружения маршрутизаторов (Router Discovery Daemon) (глава 9, раздел "ICMP сообщения поиска маршрутизатора")
Существует программа, которая предоставляет поддержку хоста и маршрутизатора для сообщений поиска маршрутизатора. Хост ftp.gregorio.stanford.edu, файл gw-discovery/nordmark-rdisc.tar. Программа была написана в Sun Microsystems и теперь распространяется свободно.
/Dev/ip ip_cksum_choice (Отладочная)
/dev/ip
ip_cksum_choice
(Отладочная) Осуществляет выбор между двумя независимыми реализациями алгоритма расчета контрольной суммы IP.ip_debug
(Отладочная) Включает печать отладочного вывода от ядра, если больше чем 0. Чем больше значение, тем больше генерируется вывода. По умолчанию 0.ip_def_ttl
Значение TTL по умолчанию для исходящих IP датаграмм (если не указано на транспортном уровне). По умолчанию 255.ip_forward_directed_broadcasts
Если равно 1 (по умолчанию), принятые датаграммы, адрес назначения которых является широковещательным адресом непосредственно подключенного интерфейса, перенаправляются как широковещательные запросы канального уровня. Если равно 0, эти датаграммы молча отбрасываются.ip_forward_src_routed
Если равно 1 (по умолчанию), принятые датаграммы, содержащие опцию маршрутизации от источника, перенаправляются. Если равно 0, эти датаграммы отбрасываются.ip_forwarding
Указывает, будет ли система перенаправлять входящие IP датаграммы: 0 означает нет перенаправления, 1 обозначает перенаправляет всегда и 2 (по умолчанию) означает, что перенаправление осуществляется только в том случае, если функционирует два или более интерфейсов.ip_icmp_return_data_bytes
Количество байт данных после IP заголовка, которые возвращаются в ICMP ошибке. По умолчанию 64.ip_ignore_delete_time
(Отладочная) Минимальное время жизни записи в таблице маршрутизации IP (IRE). По умолчанию 30 секунд. (Этот параметр приводится в секундах, а не в миллисекундах).ip_ill_status
(Только для чтения) Отображает статус для структуры данных уровня, находящегося ниже IP. Существует одна структура нижнего уровня для каждого интерфейса.ip_ipif_status
(Только для чтения) Отображает статус каждой структуры данных IP интерфейса (IP адрес, маска подсети и так далее). Существует только одна структура для каждого интерфейса.ip_ire_cleanup_interval
(Отладочная) Интервал, с которым просматриваются записи в таблице маршрутизации IP для возможного удаления. По умолчанию 30000 миллисекунд (30 секунд).ip_ire_flush_interval
Интервал, через который информация ARP безусловно удаляется из таблицы маршрутизации IP. По умолчанию 1200000 миллисекунд (20 минут).ip_ire_pathmtu_interval
Интервал, через который алгоритм определения транспортного MTU пытается увеличить MTU. По умолчанию 30000 миллисекунд (30 секунд).ip_ire_redirect_interval
Интервал, через который записи в таблице маршрутизации IP, которые получены с помощью ICMP перенаправления, удаляются. По умолчанию 60000 миллисекунд (60 секунд).ip_ire_status
(Только для чтения) Отображает все записи в таблице маршрутизации IP.ip_local_cksum
Если равно 0 (по умолчанию), IP не рассчитывает контрольную сумму IP или контрольную сумму верхних протоколов (TCP, UDP, ICMP или IGMP) для датаграмм, которые отправляются или принимаются через loopback интерфейс. Если равно 1, контрольные суммы рассчитываются.ip_mrtdebug
(Отладочная) Включает печать отладочного вывода, связанного с групповой маршрутизацией ядра, если равно 1. По умолчанию равно 0.ip_path_mtu_discovery
Если равно 1 (по умолчанию), определение транспортного MTU осуществляется уровнем IP. Если равно 0, IP никогда не установит бит "не фрагментировать" для исходящих датаграмм.ip_respond_to_address_mask
Если равно 0 (по умолчанию), хост не отвечает на ICMP запросы маски адреса. Если равно 1 - отвечает.ip_respond_to_echo_broadcast
Если равно 1 (по умолчанию), хост отвечает на ICMP эхо запросы, которые отправлены на широковещательный адрес. Если равно 0 - не отвечает.ip_respond_to_timestamp
Если равно 0 (по умолчанию), хост не отвечает на ICMP запросы временной марки. Если равно 1 - отвечает.ip_respond_to_timestamp_broadcast
Если равно 0 (по умолчанию), хост не отвечает на ICMP запросы временной марки, которые отправлены на широковещательный адрес. Если равно 1 - отвечает.ip_rput_pullups
(Отладочная) Счетчик количества буферов в драйвере сетевого интерфейса, который необходимо опросить, чтобы получить полный IP заголовок. Устанавливается в 0 во время загрузки и может быть сброшен в 0.ip_send_redirects
Если равно 1 (по умолчанию), хост отправляет ICMP перенаправления, когда функционирует как маршрутизатор. Если равно 0 - не отправляет.ip_send_source_quench
Если равно 1 (по умолчанию), хост генерирует ICMP ошибки подавления источника, когда входящие датаграммы отбрасываются. Если равно 0 - не генерирует.ip_wroff_extra
(Отладочная) Количество байт дополнительного пространства, необходимого в буфере, чтобы расположить IP заголовки. По умолчанию 32./dev/icmp
icmp_bsd_compat
(Отладочная) Если равно 1 (по умолчанию), поле длины в IP заголовке принятой датаграммы настраивается так, чтобы исключить длину IP заголовка. Это совместимо с Berkeley реализациями и необходимо для приложений, которые читают символьные (raw) IP или символьные ICMP пакеты. Если равно 0, поле длины не изменяется.icmp_def_ttl
Значение TTL по умолчанию для исходящих ICMP сообщений. По умолчанию 255.icmp_wroff_extra
(Отладочная) Количество байт дополнительного пространства в буферах, необходимого, чтобы расположить IP опции и заголовки канального уровня. По умолчанию 32./dev/arp
arp_cache_report
(Только для чтения) ARP кэш.arp_cleanup_interval
Интервал, после которого запись удаляется из ARP кэша. По умолчанию 300000 миллисекунд (5 минут). (IP поддерживает свой собственный кэш полной ARP трансляции; см. ip_ire_flush_interval.)arp_debug
(Отладочная) Если равно 1, включает печать отладочного вывода ARP драйвера. По умолчанию 0./dev/udp
udp_def_ttl
TTL по умолчанию для исходящих UDP датаграмм. По умолчанию 255.udp_do_checksum
Если равно 1 (по умолчанию), рассчитывается контрольная сумма UDP для исходящих UDP датаграмм. Если равно 0, исходящие UDP датаграммы не содержат контрольной суммы. (В отличие от большинства других реализаций, этот флаг контрольной суммы UDP не влияет на входящие датаграммы. Если получена датаграмма, которая имеет ненулевую контрольную сумму, контрольная сумма всегда будет проверена.)udp_largest_anon_port
Самый большой номер порта, который может быть назначен как динамически назначаемый UDP порт. По умолчанию 65535.udp_smallest_anon_port
Начальный номер порта, с которого начинаются динамически назначаемые UDP порты. По умолчанию 32768.udp_smallest_nonpriv_port
Процессу требуются привилегии суперпользователя, чтобы назначить самому себе номер порта меньше чем этот. По умолчанию 1024.udp_status
(Только для чтения) Статус всех локальных конечных точек UDP: локальный IP адрес и порт, удаленный IP адрес и порт.udp_trust_optlen
(Отладочная) В настоящее время не используется.udp_wroff_extra
(Отладочная) Количество байт дополнительного пространства, необходимого, чтобы расположить в буфере IP опции и заголовки канального уровня. По умолчанию 32./dev/tcp
tcp_close_wait_interval
Значение 2MSL: время, которое необходимо провести в состоянии TIME_WAIT. По умолчанию 240000 миллисекунд (4 минуты).tcp_conn_grace_period
(Отладочная) Время, добавляемое к значению таймера при отправке SYN. По умолчанию 500 миллисекунд.tcp_conn_req_max
Максимальное количество необслуженных запросов на соединение, которые могут быть поставлены в очередь для любой слушающей конечной точки. По умолчанию 5.tcp_cwnd_max
Максимальное значение окна переполнения. По умолчанию 32768.tcp_debug
(Отладочная) Если равно 1, включается печать отладочного вывода TCP. По умолчанию 0.tcp_deferred_ack_interval
Время, которое необходимо подождать перед отправкой задержанного ACK. По умолчанию 50 миллисекунд.tcp_dupack_fast_retransmit
Количество последовательно пришедших дублированных ACK, которые включают быструю повторную передачу и алгоритм быстрого восстановления. По умолчанию 3.tcp_eager_listeners
(Отладочная) Если равно 1 (по умолчанию), TCP завершает трехразовое рукопожатие перед передачей нового соединения приложению с ожидающим пассивным открытием. Это способ, которым пользуется большинство реализаций TCP. Если равно 0, TCP передает пришедший запрос на соединение (принятый SYN) приложению и не завершает трехразовое рукопожатие до тех пор, пока приложение не примет соединение. (Установка этого значения в 0 может сломать многие существующие приложения.)tcp_ignore_path_mtu
(Отладочная) Если равно 1, определение транспортного MTU игнорирует принятые ICMP сообщения о необходимости фрагментации. Если равно 0 (по умолчанию), для TCP включается алгоритм определения транспортного MTU.tcp_ip_abort_cinterval
Полное время тайм-аута повторной передачи, когда TCP осуществляет активное открытие. По умолчанию 240000 миллисекунд (4 минуты).tcp_ip_abort_interval
Полное время тайм-аута повторной передачи для TCP соединения, после того как оно установлено. По умолчанию 120000 миллисекунд (2 минуты).tcp_ip_notify_cinterval
Величина тайм-аута, когда TCP осуществляет активное открытие, после чего TCP уведомляет IP о необходимости найти новый маршрут. По умолчанию 10000 миллисекунд (10 секунд).tcp_ip_notify_interval
Величина тайм-аута для установленного соединения, после истечения которого TCP уведомляет IP о необходимости найти новый маршрут. По умолчанию 10000 миллисекунд (10 секунд).tcp_ip_ttl
TTL, используемый для исходящих TCP сегментов. По умолчанию 255.tcp_keepalive_interval
Время, в течение которого соединение не используется, по истечению которого будет отправлена проба "оставайся в живых". По умолчанию 7200000 миллисекунд (2 часа).tcp_largest_anon_port
Самый большой номер порта, который может быть использован как динамически назначаемый порт TCP. По умолчанию 65535.tcp_maxpsz_multiplier
(Отладочная) Указывает множитель MSS, на основании которого данные, которые выдает приложение, разбиваются на пакеты. По умолчанию 1.tcp_mss_def
Значение MSS по умолчанию для нелокальных пунктов назначения. По умолчанию 536.tcp_mss_max
Максимальный MSS. По умолчанию 65495.tcp_mss_min
Минимальный MSS. По умолчанию 1.tcp_naglim_def
(Отладочная) Максимальное значение порога алгоритма Нагла для каждого соединения. По умолчанию равно 65535. Значение для соединения начинается с минимального MSS или этого значения. Значение для соединения устанавливается в 1 опцией сокета TCP_NODELAY, которая выключает алгоритм Нагла.tcp_old_urp_interpretation
(Отладочная) Если равно 1 (по умолчанию), используется старая (но наиболее распространенная) BSD интерпретации указателя срочности: он указывает на 1 байт позади последнего байта срочных данных. Если равно 0, используется интерпретация, приведенная в требованиях к хостам RFC: указатель срочности указывает на последний байт срочных данных.tcp_rcv_push_wait
(Отладочная) Максимальное количество байт, полученных без установленного флага PUSH, перед тем как данные передаются приложению. По умолчанию 16384.tcp_rexmit_interval_initial
(Отладочная) Первоначальная величина тайм-аута повторной передачи. По умолчанию 500 миллисекунд.tcp_rexmit_interval_max
(Отладочная) Максимальная величина тайм-аута повторной передачи. По умолчанию 60000 миллисекунд (60 секунд).tcp_rexmit_interval_min
(Отладочная) Минимальная величина тайм-аута повторной передачи. По умолчанию 200 миллисекунд.tcp_rwin_credit_pct
(Отладочная) Часть приемного окна (в процентах), которая должна быть буферизирована, перед тем как управление потоком проверяет каждый принятый сегмент. По умолчанию 50%.tcp_smallest_anon_port
Начальный номер порта, с которого начинаются динамические назначаемые порты TCP. По умолчанию 32768.tcp_smallest_nonpriv_port
Процессу требуются привилегии суперпользователя, чтобы назначить самому себе номер порта меньше чем этот. По умолчанию 1024.tcp_snd_lowat_fraction
(Отладочная) Если не равно 0, метка "низкой воды" отправляющего буфера равна размеру отправляющего буфера поделенного на это значение. По умолчанию 0 (выключено).tcp_status
(Только для чтения) Информация о всех TCP соединениях.tcp_sth_rcv_hiwat
(Отладочная) Если не равно 0, значение устанавливается в метку "высокой воды" для потока. По умолчанию равно 0.tcp_sth_rcv_lowat
(Отладочная) Если не равно 0, значение устанавливается в метку "низкой воды" для потока. По умолчанию 0.tcp_wroff_xtra
(Отладочная) Количество байт дополнительного пространства, необходимого, чтобы расположить в буферах IP опции и заголовки канального уровня. По умолчанию 32.AIX 3.2.2
AIX 3.2.2 позволяет установить сетевые опции с использованием команды no. Она может отобразить значения опций, установить значения опций или установить значения по умолчанию. Например, посмотреть опцию можно следующим образом:
aix % no -o udp_ttl
udp_ttl = 30
Модифицированы могут быть следующие опции.
arpt_killc
Время (в минутах) перед тем, как неиспользуемая запись ARP полностью удаляется. По умолчанию 20.ipforwarding
Если равно 1 (по умолчанию), IP датаграммы всегда перенаправляются. Если равно 0, перенаправление выключено.ipfragttl
Время жизни (в секундах) для IP фрагментов, которые ожидают повторной сборки. По умолчанию 60.ipsendredirects
Если равно 1 (по умолчанию), хост будет отправлять ICMP перенаправления, когда перенаправляет IP датаграммы. Если равно 0, ICMP перенаправления не отправляются.loop_check_sum
Если равно 1 (по умолчанию), контрольная сумма IP рассчитывается для датаграмм, которые посылаются по loopback интерфейсу. Если равно 0, эта контрольная сумма не рассчитывается.nonlocsrcroute
Если равно 1 (по умолчанию), полученные датаграммы, содержащие опцию маршрутизации от источника, перенаправляются. Если равно 0, эти датаграммы отбрасываются.subnetsarelocal
Если равно 1 (по умолчанию), IP адрес назначения с тем же самым идентификатором сети, как и у отправляющего хоста, однако с другим идентификатором подсети, считается локальным. Если равно 0, только IP адреса назначения принадлежащие непосредственно подключенной подсети считаются локальными. Кратко это описано на рисунке Е.1. Когда происходит отправка на локальный пункт назначения, TCP выбирает MSS, основываясь на MTU исходящего интерфейса. Когда происходит отправка на нелокальные пункты назначения, TCP использует значение по умолчанию (536) в качестве MSS.tcp_keepidle
Количество 500-миллисекундных тиков часов перед отправкой пробы "оставайся в живых". Значение по умолчанию 14400 (2 часа).tcp_keepintvl
Количество 500-миллисекундных тиков часов перед отправкой последовательных проб "оставайся в живых", если не получен отклик. Значение по умолчанию 150 (75 секунд).tcp_recvspace
Размер по умолчанию приемного буфера TCP. Это оказывает влияние на предлагаемый размер окна. Значение по умолчанию 16384.tcp_sendspace
Размер по умолчанию отправляющего буфера TCP. Значение по умолчанию 16384.tcp_ttl
Значение TTL по умолчанию для TCP сегментов. Значение по умолчанию 60.udp_recvspace
Размер по умолчанию приемного буфера UDP. Значение по умолчанию 41600, что позволяет принять 40 датаграмм размером 1024 байта.udp_sendspace
Размер по умолчанию отправляющего буфера UDP. Определяет максимальный размер UDP датаграммы, которая может быть отправлена. По умолчанию 9216.udp_ttl
Значение TTL по умолчанию в UDP датаграммах. По умолчанию 30.
ISODE SNMP менеджер и агент (глава 25)
ISODE SNMP менеджер и агент (глава 25)
SNMP менеджер и агент, описанные в разделе "Простые примеры" главы 25, являются частью пакета ISODE 8.0. Их можно получить со многих FTP узлов, таких как ftp.uu.net в директории networking/osi/isode.
Краник в сетевом интерфейсе SunOS
Краник в сетевом интерфейсе SunOS
SunOS 4.1.x предоставляет потоковый (STREAMS) драйвер псевдоустройства, который называется краник в сетевом интерфейсе (NIT - Network Interface Tap) . ([Rago 1993] содержит дополнительные детали о драйверах потоковых устройств. Мы будем называть эту характеристику "потоками" (streams).) NIT напоминает пакетный фильтр BSD, однако он не такой мощный и эффективный. На рисунке А.2 показаны потоковые модули, которые используются в NIT. Одно отличие между этим рисунком и рисунком А.1 заключается в том, что BPF может захватывать пакеты, принятые и переданные с сетевого интерфейса, тогда как NIT захватывает только пакеты, полученные с этого интерфейса. С использованием tcpdump с NIT мы можем видеть только пакеты, отправленные другими хостами в сеть - мы никогда не увидим пакеты, отправленные нашим собственным хостом. (Несмотря на то, что BPF работает с SunOS 4.1.x, он требует изменения исходного кода для Ethernet драйвера устройства, что невозможно для большинства пользователей, которые не имеют доступа к исходным кодам.)
Когда устройство /dev/nit открыто, потоковый драйвер nit_if открыт. Так как NIT построен с использованием потоков, обрабатывающие модули могут быть помещены поверх драйвера nit_if. tcpdump помещает модуль nit_buf в STREAM. Этот модуль собирает вместе несколько фреймов из сети в один буфер чтения, а пользовательский процесс устанавливает значение тайм-аута. Это напоминает то, что мы описали в случае BPF. Демон RARP не помещает этот модуль в свой поток, так как он работает с небольшим количеством пакетов.
Опция отладки сокета
Опция отладки сокета
Еще один способ посмотреть, что проходит в TCP соединении, это включить опцию отладки сокета, естественно на системах, которые поддерживают эту характеристику. Эта характеристика работает только с TCP (она не работает с другими протоколами) и требует поддержки приложения (чтобы включить опцию сокета, когда оно стартует).
Большинство реализаций Berkeley поддерживают это, включая SunOS, 4.4BSD и SVR4.
Программа включает опцию сокета, а ядро затем осуществляет записи того, что происходит для этого соединения. Затем эта информация может быть получена путем запуска программы trpt(8). Чтобы включить опцию отладки сокета, не требуется специальных прав доступа, однако необходимо иметь специальные привилегии, чтобы запустить trpt, так как она осуществляет доступ к памяти ядра.
Наша программа sock (приложение С) поддерживает эту характеристику с опцией -D, однако информацию, которую можно получить в выводе, сложнее описать и понять, нежели соответствующий вывод команды tcpdump. Тем не менее, мы использовали эту программу в разделе "Пример RTT" главы 21, чтобы посмотреть переменные ядра в TCP соединении, к которому tcpdump не имел доступа.
Назад
Компания | Услуги | Для клиентов | Библиотека | Галерея | Cофт | Линки
На главную
Пакетный фильтр BSD
Пакетный фильтр BSD
В современных реализациях ядра BSD существует пакетный фильтр BSD (BPF - BSD Packet Filter), именно его использует tcpdump, чтобы отлавливать и фильтровать пакеты из сетевой платы (которая помещена в смешанный режим). BPF также работает с каналами точка-точка, такими как SLIP (глава 2, раздел "SLIP: IP по последовательной линии") (при этом не требуется специальных настроек), и с интерфейсом loopback (глава 2, раздел "Интерфейс loopback").
BPF имеет долгую историю. Пакетный фильтр Enet был создан в 1980 году Mike Accetta и Rick Rashid в университете Carnegie Mellon. Jeffrey Mogul из Stanford перенес этот код в BSD и продолжил его разработку с 1983 года. С тех пор туда же был включен Ultrix Packet Filter на DEC, STREAMS NIT модуль на SunOS 4.1, и BPF. Steven McCanne из лаборатории Lawrence Berkeley Laboratory начал работать с BPF летом 1990 года. Однако большая часть разработки принадлежит Van Jacobson. Подробности о последней версии и сравнения с Sun's NIT даны в [McCanne and Jacobson 1993].
На рисунке А.1 показаны характеристики BPF, когда он используется в случае Ethernet.
Пакетный фильтр BSD (приложение
Пакетный фильтр BSD (приложение A, раздел "Пакетный фильтр BSD")
Пакетный фильтр BSD является частью пакета tcpdump.
Передача прервана!
GN="CENTER">Счетчик
Поставщик интерфейса канального уровня в SVR4
Поставщик интерфейса канального уровня в SVR4
SVR4 поддерживает поставщика интерфейса канального уровня (DLPI - Data Link Provider Interface), который является потоковой реализацией OSI Data Link Service Definition. Большинство версий SVR4 все еще поддерживают версию 1 DLPI, SVR4.2 поддерживает обе версии 1 и 2, а Sun's Solaris 2.x поддерживают версию 2 с дополнительными расширениями.
Программы мониторинга сети, такие как tcpdump, должны использовать DLPI для символьного доступа к драйверам устройств канального уровня. В Solaris 2.x модуль потокового пакетного фильтра был переименован в pfmod, а модуль буфера переименован в bufmod.
Несмотря на то, что Solaris 2.x это достаточно новая система, вскоре должна появиться реализация tcpdump. В Sun есть программа, которая называется snoop, осуществляющая функции, напоминающие функции tcpdump. (snoop заменяет программу, работающую в SunOS 4.x, которая называется etherfind.)
Приложение A Программа tcpdump
Приложение A Программа tcpdump
Программа tcpdump была написана Van Jacobson, Craig Leres и Steven McCanne, во время их работы в лаборатории Lawrence Berkeley, Калифорнийского университета, Беркли. В тексте этой книги используется версия 2.2.1 (июнь 1992 года).
Программа tcpdump разработана таким образом, чтобы переводить сетевую плату в смешанный режим (promiscuous mode), при этом, каждый пакет, проходящий по кабелю, фиксируется. Обычно сетевые платы для сред передачи, таких как Ethernet, захватывают только фреймы канального уровня, адресованные конкретному интерфейсу или отправленные на широковещательный адрес (глава 2, раздел "Ethernet и IEEE 802 инкапсуляция").
Операционная система должна позволить поместить интерфейс в смешанный режим и позволить пользовательскому процессу захватывать фреймы. Реализации tcpdump существуют для следующих Unix систем: 4.4BSD, BSD/386, SunOS, Ultrix и HP-UX. Просмотрите файл README, который поставляется вместе с дистрибутивом tcpdump, где подробно описано, как в данном случае функционирует операционная система и какие версии поддерживаются.
Существуют альтернативы для tcpdump. На рисунке 10.8 мы использовали программу snoop, поставляемую в составе Solaris 2.2, чтобы просмотреть некоторые пакеты. В AIX 3.2.2 есть программа iptrace, которая предоставляет подобные возможности.
Приложение B Компьютерные часы
Приложение B Компьютерные часы
Так как в большинстве примеров в этом тексте рассчитываются какие-либо временные интервалы, нам необходимо более подробно описать способы поддержки времени в современных Unix системах. Все сказанное ниже имеет отношение к системам, на которых использовались примеры в этой книге. Более подробно о поддержке времени можно прочитать в разделах 3.4 и 3.5 публикации [Leffler et al. 1989].
С определенной частотой генерируются аппаратные прерывания от часов. В случае Sun SPARCs и Intel 80386s эти прерывания возникают каждые 10 миллисекунд.
Необходимо отметить, что в большинстве компьютеров используется нескомпенсированный кварцевый генератор для генерации прерываний. Как можно заметить из таблицы 7 RFC 1305 [Mills 1992], не стоит беспокоиться о том, на сколько отстает в день этот генератор. Очень немногие компьютеры могут поддерживать точное время (другими словами, прерывания не возникают точно каждые 10 миллисекунд). Приближение 0,01% дает ошибку примерно в 8,64 секунды в день. Чтобы поддерживать более точное время, (1) нужно использовать лучший генератор (кварц), (2) можно использовать внешний источник времени с повышенной точностью (например, источник времени, предоставляемый Global Positioning Satellites) или (3) получить доступ по Internet к системам с более точными часами. Последнее решается с помощью протокола Network Time Protocol, как описано в RFC 1305, но это выходит за рамки обсуждения нашей книги.
Еще один хорошо известный источник ошибок во времени в Unix системах заключается в том, что прерывания, которые появляются каждые 10 миллисекунд, всего лишь заставляют ядро увеличивать переменную, которая отслеживает время. Если ядро потеряло прерывание (например, оно было слишком занято в период между двумя соседними 10-миллисекундными прерываниями), часы отстанут на 10 миллисекунд. Подобная потеря прерываний часто приводит к отставанию часов в Unix системах.
Даже если прерывания часов происходят примерно каждые 10 миллисекунд, более новые системы, такие как SPARCs, предоставляют более высокую точность часов. При работе с NIT драйвером (описанным в приложении А), tcpdump имеет доступ к этому таймеру с повышенным разрешением. В SPARC этот таймер предоставляет микросекундное разрешение. Пользовательские процессы могут получить доступ к этому таймеру с повышенным разрешением через функцию gettimeofday(2).
Автор провел следующий эксперимент. Была запущена программа, которая вызывает функцию gettimeofday циклически 10000 раз, при этом каждый раз возвращенное значение сохранялось в массиве. В конце цикла были напечатаны 9999 отрезков времени. Для SPARC ELC величины отрезков времени показаны на рисунке В.1.
| Микросекунды | "> |
Приложение C Программа sock
Приложение C Программа sock
Для генерации TCP и UDP данных использовалась простая тестовая программа, называемая sock. Она выполняла функции как клиента, так и сервера. С помощью этой тестовой программы, которую можно запустить из приглашения shellа, мы избежали необходимости писать новые программы клиента и сервера на языке программирования C для каждой специальной характеристики, которую хотели протестировать. Так как цель этой книги - понимание сетевых протоколов, а не сетевого программирования, в этом приложении мы ограничимся описанием программы и ее опций.
Существует определенное количество программ, функционально похожих на sock. Juergen Nickelsen написал программу, которая называется socket, а Dave Yost программу sockio. Обе реализуют много похожих функций. Части программы sock также были получены из свободно распространяемой программы ttcp, написанной Mike Muuss и Terry Slattery.
Программа sock может работать в одном из четырех режимов:
Интерактивный клиент: по умолчанию. Программа подсоединяется к серверу и затем копирует стандартный ввод на сервер и копирует все, что получено от сервера, на стандартный вывод. Это показано на рисунке С.1.
Приложение D Решения и ответы на упражнения
Приложение D Решения и ответы на упражнения
Глава 1 Значение равно 27 - 2 (126) плюс 214 - 2 (16382) плюс 221 - 2 (2097150), что составит 2113658. Мы вычитаем 2 при каждом расчете, так как идентификатор сети, состоящий из всех нулевых битов или всех единичных битов, не может существовать. На рисунке D.1 точками показаны значения до августа 1993 года.
Приложение E Конфигурируемые опции
Приложение E Конфигурируемые опции
В тексте встречаются характеристики TCP/IP, которые нам пришлось описывать следующим образом "это зависит от конфигурации". Например, рассчитывается или нет контрольная сумма UDP (глава 11, раздел "Контрольная сумма UDP"), является IP адрес назначения с одним и тем же идентификатором сети, но с различными идентификаторами подсети, локальным или нелокальным (глава 18, раздел "Максимальный размер сегмента"), и будет ли перенаправляться широковещательный запрос или нет (глава 12, раздел "Примеры широковещательных запросов"). И действительно, множество характеристик в реализациях TCP/IP могут быть модифицированы системным администратором. В этом приложении приводится список некоторых конфигурируемых опций для различных реализаций TCP/IP, которые использовались в тексте. Как Вы могли ожидать, продукт каждого поставщика программного обеспечения отличается от других. В этом приложении дается представление о том, какие типы параметров в различных реализациях могут быть модифицированы. Небольшое количество опций, которые принадлежат совсем уж конкретным реализациям, такие как, например, метка низкой воды для буфера памяти, не рассматриваются.
Эти переменные описываются только для информационных целей. Их имена, значения по умолчанию или интерпретации могут изменяться от одного релиза к другому. Обратитесь к документации, которая поставляется с программным обеспечением, для того чтобы составить для себя представление об этих переменных.
Здесь не приводится описания процесса установки опций, которая происходит каждый раз при загрузке системы: инициализация каждого сетевого интерфейса с использованием ifconfig (установка IP адреса, маски подсети), ввод статических маршрутов в таблицу маршрутизации и так далее. Вместо этого в приложении сфокусировано внимание на опциях конфигурации, которые влияют на функционирование TCP/IP.
Приложение F Где можно взять исходные тексты
Приложение F Где можно взять исходные тексты
В книге используется много свободно распространяемых пакетов программного обеспечения. В этом приложении рассказывается, как можно получить эти программы.
Техника, которая используется для получения подобного программного обеспечения, называется анонимный FTP (anonymous FTP), где FTP это стандартный протокол передачи файлов по Internet (File Transfer Protocol) (глава 27). В разделе "Примеры FTP" главы 27 приведен пример использования анонимного FTP. Для того чтобы изучить основные ресурсы Internet и особенности работы с анонимным FTP, обратитесь к любой популярной книге по Internet, например [LaQuey 1993] или [Krol 1992].
Хосты, упоминаемые в приложении, это основные хосты, содержащие эти пакеты программ, однако может существовать еще множество хостов, где могут быть эти программы. Сервис Internet Archie поможет определить месторасположения программ. Однако, в тексте используются только те версии программ, которые описаны ниже.
Пока Вы читаете эту книгу, могут появиться более новые версии этих программ.
Вы должны использовать FTP команду dir, чтобы посмотреть, есть ли более новые версии на конкретном хосте.
В этом приложении приведены используемые программы в порядке глав книги.
Приложение G Библиография
Приложение G Библиография
Все RFC можно получить абсолютно бесплатно, либо с использованием электронной почты, либо через анонимное FTP. Как это сделать - описано в разделе "RFC" главы 1.
Albitz, P., and Liu, C. 1992. DNS and BIND. O'Reilly & Associates, Sebastopol, Calif.
Подробно описаны задачи администрирования и обслуживания DNS сервера.
Alexander, S., and Droms, R. 1993. "DHCP Options and BOOTP Vendor Extensions", RFC 1533, 30 pages (Oct.).
Almquist, P. 1992. "Type of Service in the Internet Protocol Suite", RFC 1349, 28 pages (July).
Описывается, как использовать поле типа сервиса в IP заголовке.
Almquist, P., ed. 1993. "Requirements for IP Routers", Internet Draft (Mar.).
Временно заменяет RFC 1009 [Braden and Postel 1987]. Новый RFC скорее всего появится в четырех томах. Том 1: Архитектура Internet, терминология и общие соглашения. Том 2: канальный уровень, сетевой уровень, транспортный уровень и прикладной уровень. Том 3: перенаправления и протоколы маршрутизации. Том 4: работа в сети, поддержание работоспособности и управление сетью.
Можно получить через анонимный FTP с хоста ftp.jessica.stanford.edu в директории rred. После того как выйдет RFC, необходимость в этой публикации отпадет.
Bellovin, S. M. 1993. Private Communication.
Bhide, A., Elnozahy, E. N., and Morgan, S. P. 1991. "A Highly Available Network File Server", Proceedings of the 1991 Winter USENIX Conference, pp. 199-205, Dallas, Tex.
Описывает использование "беспричинного" ARP (глава 4, раздел "Беспричинный ARP").
Borenstein, N., and Freed, N. 1993. "MIME (Multipurpose Internet Mail Extensions) Part One: Mechanisms for Specifying and Describing the Format of Internet Message Bodies", RFC 1521, 81 pages (Sept.).
Этот RFC заменяет ранний RFC 1341. В приложение H этого RFC приводится список отличий от RFC 1341.
Borman, D. A., ed. 1990. "Telnet Linemode Option", RFC 1184, 23 pages (Oct.).
Borman, D. A. 1991. "IP Bandwidth Limits", Message-ID <91011437.AA17276@berserkly.cray.com>, Usenet, comp.protocols.tcp-ip Newsgroup (Jan.).
Описывает три практических ограничения производительности TCP, которые мы описали в конце раздела "Производительность TCP" главы 24.
Borman, D. A. 1992. "TCP/IP Performance at Cray Research", Proceedings of the Twenty-third Internet Engineering Task Force, pp. 492-493 (Mar.), San Diego Supercomputer Center, San Diego, Calif.
Borman, D. A., ed. 1993a. "Telnet Environment Option", RFC 1408, 7 pages (Jan.).
Опция Telnet для передачи переменных окружения от клиента серверу.
Borman, D. A. 1993b. "A Practical Perspective on Host Networking", in Internet System Handbook, eds. D. C. Lynch and M. T. Rose, pp. 309-367. Addison-Wesley, Reading, Mass.
Практический взгляд на требования к хостам RFC (1122 и 1123).
Braden, R. T., ed. 1989a. "Requirements for Internet Hosts - Communication Layers", RFC 1122, 116 pages (Oct.).
Первая половина требований к хостам RFC. Эта половина охватывает канальный уровень, IP, TCP и UDP.
Braden, R. T., ed. 1989b. "Requirements for Internet Hosts - Application and Support", RFC 1123, 98 pages (Oct.).
Вторая половина требованний к хостам RFC. Эта половина описывает Telnet, FTP, TFTP, SMTP и DNS.
Braden, R. T. 1989c. "Perspective on the Host Requirements RFCs", RFC 1127, 20 pages (Oct.).
Краткое неофициальное описание обсуждений и сделанных выводов в рабочей группе IETF, которая разрабатывает требования к хостам RFC.
Braden, R. T. 1992a. "TIME-WAIT Assassination Hazards in TCP", RFC 1337, 11 pages (May).
Рассказ о том, к каким проблемам может привести получение RST в состоянии TIME_WAIT.
Braden, R. T. 1992b. "Extending TCP for Transactions - Concepts", RFC 1379, 38 pages (Nov.).
Исторические факты и концепции, положенные в основу T/TCP.
Braden, R. T. 1992c. "Extending TCP for Transactions - Functional Specification", Internet Draft, 32 pages (Dec.).
Спецификации и обсуждения реализации T/TCP.
Braden, R. T., Borman, D. A., and Partridge, C. 1988. "Computing the Internet Checksum", RFC 1071, 24 pages (Sept.).
Алгоритмы расчета контрольной суммы, используемые IP, ICMP, IGMP, UDP и TCP.
Braden, R. T., and Postel J.B. 1987. "Requirements for Internet Gateways", RFC 1009, 55 pages (June).
Эквивалент требований к хостам RFC для маршрутизаторов. RFC заменен; обратитесь к [Almquist 1993].
Callon, R. 1992. "TCP and UDP with Bigger Addresses (TUBA), A Simple Proposal for Internet Addressing and Routing", RFC 1347, 9 pages (June).
Caceres, R., Danzig, P. B., Jamin, S., and Mitzel, D.J. 1991. "Characteristics of Wide-Area TCP/IP Conversations", Computer Communication Review, vol. 21, no. 4, pp. 101-112 (Sept.).
Case, J. D., Fedor, M. S., Schoffstall, M. L., and Davin, C. 1990. "Simple Network Management (SNMP)", RFC 1157, 36 pages (May).
Спецификация протокола SNMP.
Case, J. D., McCloghrie, K., Rose, M. T., and Waldbusser, S. 1993. "An Introduction to Version 2 of the Internet-Standard Network Management Framework", RFC 1441, 13 pages (Apr.).
Введение в SNMPv2 со ссылками на остальные 11 RFC, определяющие SNMPv2.
Case, J. D., and Partridge, C. 1989. "Case Diagrams: A First Step to Diagrammed Management Information Bases", Computer Communication Review, vol. 19, no. 1, pp. 13-16 (Jan.).
Описывает диаграммы, используемые для повышения наглядности при изучении взаимосвязи между переменными SNMP в заданном модуле.
Casner, S., and Deering, S. E. 1992. "First IETF Internet Audiocast", Computer Communication Review, vol. 22, no. 3, pp. 92-97 (July).
Описание того, как живой звук с совещания IETF передавался по Internet с помощью групповой рассылки. PostScript копию этой публикации можно получить через анонимный FTP с хоста ftp.venera.isi.edu в файле pub/ietf-audiocaast-article.ps. Файл mbone/faq.txt на этом же хосте содержит самые распространенные вопросы о групповой магистрали Internet.
Cheriton, D. P. 1988. "VMTP: Versatile Message Transaction Protocol", RFC 1045, 123 pages (Feb.).
Cheswick, W. R., and Bellovin, S. M. 1994. Firewalls and Internet Security: Repelling the Wily Hacker. Addison-Wesley, Reading, Mass.
Описывает, как установить и администрировать брэндмауэр на основе технологии firewall, а также приводит рассуждения о безопасности сетей.
Clark, D. D. 1982. "Window and Acknowledgment Strategy in TCP", RFC 813, 22 pages (July).
Оригинальный RFC, описывающий синдром глупого окна и то, как его можно избежать.
Clark, D. D. 1988. "The Design Philosophy of the DARPA Internet Protocols", Computer Communication Review, vol. 18, no. 4, pp. 106-114 (Aug.).
Описывает, как в самом начале строились протоколы Internet.
Comer, D. E., and Stevens, D. L. 1993. Internetworking with TCP/IP: Vol. III: Client-Server Programming and Applications, BSD Socket Version. Prentice-Hall, Englewood Cliffs, N.J.
Cooper, A. W., and Postel, J. B. 1993. "The US Domain", RFC 1480, 47 pages (June).
Описывает домен .us в DNS.
Crocker, D. H. 1982. "Standard for the Format of ARPA Internet Text Messages", RFC 822, 47 pages (Aug.).
Определяет формат почтовых сообщений, передаваемых с помощью SMTP.
Crocker, D. H. 1993. "Evolving the System", in Internet System Handbook, eds. D. C. Lynch and M. T. Rose, pp. 41-76. Addison-Wesley, Reading, Mass.
История разработки стандартов ARPANET, а также подробное описание современной структуры сообщества Internet. Описывает текущие стандарты Internet.
Croft, W., and Gilmore, J. 1985. "Bootstrap Protocol (BOOTP)", RFC 951, 12 pages (Sept.).
Crowcroft, J., Wakeman, I., Wang, Z., and Sirovica, D. 1992. "Is Layering Harmful?", IEEE Network, vol. 6, no. 1, pp. 20-24 (Jan.).
Семь отсутствующих рисунков в этой публикации приводятся в следующем выпуске, том 6, номер 2 (Март).
Curry, D. A. 1992. UNIX System Security: A Guide for Users and System Administrators. Addison-Wesley, Reading, Mass.
Книга, посвященная безопасности Unix. Главы 4 и 5 посвящены сетевой безопасности.
Dalton, C., Watson, J., Banks, D., Calamvokis, C., Edwards, A., and Lumley, J. 1993. "Afterburner", IEEE Network, vol. 7, no. 4, pp. 36-43 (July).
Рассказывает, как увеличить скорость работы TCP путем уменьшения количества осуществляемых копирований данных и с помощью использования специализированной сетевой платы.
Danzig, P. B., Obraczka, K., and Kumar, A. 1992. "An Analysis of Wide-Area Name Server Traffic", Computer Communication Review, vol. 22, no.4, pp. 281-292 (Oct.).
Анализ траффика на одном из корневых DNS серверов за 24 часа. Показано, как траффик от неправильно разработанных и сконфигурированных систем может занять полосу пропускания в 20 раз шире, чем необходимо.
Deering, S. E. 1989. "Host Extensions for IP Multicasting", RFC 1112, 17 pages (Aug.).
Спецификация групповой рассылки IP и IGMP.
Deering, S. E., ed. 1991. "ICMP Router Discovery Messages", RFC 1256, 19 pages (Sept.).
Deering, S. E., and Cheriton, D. P. 1990. "Multicast Routing in Datagram Internetworks and Extended LANs", ACM Transactions on Computer Systems, vol. 8, no. 2, pp. 85-110 (May).
Предложения по расширению существующей техники маршрутизации, таким образом, чтобы добиться поддержки групповой рассылки.
Dixon, T. 1993. "Comparison of Proposals for Next Version of IP", RFC 1454, 15 pages (May).
Сравнение и краткое описание SIP, PIP и TUBA.
Droms, R. 1993. "Dynamic Host Configuration Protocol", RFC 1531, 39 pages (Oct.).
Droms, R., and Dyksen, W. R. 1990. "Performance Measurements of the X Window system Communication Protocol", Software Practice & Experience, vol. 20, pp. 119-136 (Oct.).
Расчеты использования средств передачи TCP при использовании различных Х клиентов.
Fedor, M. S. 1988. "GATED: A Multi-routing Protocol Daemon for UNIX", Proceedings of the 1988 Summer USENIX Conference, pp. 365-376, San Francisco, Calif.
Finlayson, R. 1984. "Bootstrap Loading using TFTP", RFC 906, 4 pages (June).
Finlayson, R., Mann, T., Mogul, J. C., and Theimer, M. 1984. "A Reverse Address Resolution Protocol", RFC 903, 4 pages (June).
Ford, P. S., Rekhter, Y., and Braun, H-W. 1993. "Improving the Routing and Addressing of IP", IEEE Network, vol. 7, no. 3, pp. 10-15 (May).
Описание CIDR (бесклассовая маршрутизация между доменами).
Fuller, V., Li, T., Yu, J. Y., and Varadhan, K. 1993. "Classless Inter-Domain Routing (CIDR): An Address Assignment and Aggregation Strategy", RFC 1519, 24 pages (Sept.).
Спецификация CIDR.
Gerich, E. 1993. "Guidelines for Management of IP Address Space", RFC 1466, 10 pages (May).
Рассказывает, как в будущем будут распределяться IP адреса (использование вместо адресов класса В блоков адресов класса С).
Gurwitz, R., and Hinden, R. 1982. "IP-Local Area Network Addressing Issues", IEN 212, 11 pages (Sept.).
Одно из самых ранних упоминаний о широковещательной рассылке IP.
Harrenstein, K., Stahl, M. K., and Feinler, E. J. 1985. "NICNAME/WHOIS", RFC 954, 4 pages (Oct.).
Hedrick, C. L. 1988a. "Routing Information Protocol", RFC 1058, 33 pages (June).
Hedrick, C. L. 1988b. "Telnet Terminal Speed Option", RFC 1079, 3 pages (Dec.).
Hedrick, C. L., and Borman, D. A. 1992. "Telnet Remote Flow Control Option", RFC 1372, 6 pages (Oct.).
Hornig, C. 1984. "Standard for the Transmission of IP Datagrams over Ethernet Networks", RFC 894, 3 pages (Apr.).
Huitema, C. 1993. "IAB Recommendation for an Intermediate Strategy to Address the Issue of Scaling", RFC 1481, 2 pages (July).
Рекомендации IAB по реализации CIDR.
Jacobson, V. 1988. "Congestion Avoidance and Control", Computer Communication Review, vol. 18, no. 4, pp. 314-329 (Aug.).
Классическое описание TCP алгоритмов медленного старта и предотвращения переполнения. PostScript копию этой публикации можно получить через анонимный FTP с хоста ftp.ee.lbl.gov в файле congavoid.ps.Z.
Jacobson, V. 1990a. "Compressing TCP/IP Headers for Low-Speed Serial Links", RFC 1144, 43 pages (Feb.).
Описание CSLIP, версии SLIP, где происходит сжатие IP и TCP заголовков.
Jacobson, V. 1990b. "Modified TCP Congestion Avoidance Algorithm", April 30, 1990, end2end-interest mailing list (Apr.).
Описывает алгоритмы быстрой повторной передачи и быстрого восстановления.
Jacobson, V. 1990c. "Berkeley TCP Evolution from 4.3-Tahoe to 4.3-Reno", Proceedings of the Eighteenth Internet Engineering Task Force, p. 365 (Sept.), University of British Columbia, Vancouver, B.C.
Jacobson, V., and Braden, R. T. 1988. "TCP Extensions for Long-Delay Paths", RFC 1072, 16 pages (Oct.).
Описывает опцию селективных подтверждений TCP, описание которой было удалено из более поздних RFC.
Jacobson, V., Braden, R. T., and Borman, D. A. 1992. "TCP Extensions for High Performance", RFC 1323, 37 pages (May).
Описывает опцию масштабирования окна, опцию временной марки и алгоритм PAWS. Здесь же доказывается необходимость использования этих модификаций.
Jacobson, V., Braden, R. T., and Zhang, L. 1990. "TCP Extensions for High-Speed Paths", RFC 1185, 21 pages (Oct.).
Несмотря на то, что этот RFC был заменен на RFC 1323, стоит прочитать приложение, посвященное защите от старых дублированных сегментов в TCP.
Juszczak, C. 1989. "Improving the Performance and Correctness of an NFS Server", Proceedings of the 1989 Winter USENIX Conference, pp. 53-63, San Diego, Calif.
Рассматривает подробности реализации кэша NFS сервера.
Kantor, B. 1991. "BSD Rlogin", RFC 1282, 5 pages (Dec.).
Спецификация протокола Rlogin.
Karn, P., and Partridge, C. 1987. "Improving Round-Trip Time Estimates in Reliable Transport Protocols", Computer Communication Review, vol. 17, no. 5, pp. 2-7 (Aug.).
Детали алгоритма Карна, посвященные обработке тайм-аута повторной передачи для сегментов, которые передаются повторно.
Katz, D. 1990. "Proposed Standard for the Transmission of IP Datagrams Over FDDI Networks", RFC 1188, 11 pages (Oct.).
Рассказывает об инкапсуляции IP датаграмм и ARP запросов, описывает сети FDDI, включая проблемы групповой рассылки.
Kent, C. A., and Mogul, J. C. 1987. "Fragmentation Considered Harmful", Computer Communication Review, vol. 17, no. 5, pp. 390-401 (Aug.).
Kent, S. T. 1991. "U.S. Department of Defense Security Options for the Internet Protocol", RFC 1108, 17 pages (Nov.).
Kleinrock, L. 1992. "The Latency/Bandwidth Tradeoff in Gigabit Networks", IEEE Communications Magazine, vol. 30, no. 4, pp. 36-40 (Apr.).
Klensin, J., Freed, N., and Moore, K. 1993. "SMTP Service Extension for Message Size Declaration", RFC 1427, 8 pages (Feb.).
Klensin, J., Freed, N., Rose, M. T., Stefferud, E. A., and Crocker, D. 1993a. "SMTP Service Extensions", RFC 1425, 10 pages (Feb.).
Klensin, J., Freed, N., Rose, M. T., Stefferud, E. A., and Crocker, D. 1993b. "SMTP Service Extension for 8bit-MIME Transport", RFC 1426, 6 pages (Feb.).
Krol, E. 1992. The Whole Internet. O'Reilly & Associates, Sebastopol, Calif.
Введение в Internet для новичков.
LaQuey, T. 1993. The Internet Companion: A Beginner's Guide to Global Networking. Addison-Wesley, Reading, Mass.
Leffler, S. J., and Karels, M. J. 1984. "Trailer Encapsulations", RFC 893, 3 pages (Apr.).
Leffler, S. J., McKusick, M. K., Karels, M. J., and Quarterman, J. S. 1989. The Design and Implementation of the 4.3BSD UNIX Operating System. Addison-Wesley, Reading, Mass.
Полное руководство по Unix системе 4.3BSD. Эта книга описывает Tahoe релиз 4.3BSD.
Lougheed, K., and Rekhter, Y. 1991. "A Border Gateway Protocol 3 (BGP-3)", RFC 1267, 35 pages (Oct.).
Lynch, D. C. 1993. "Historical Perspective", in Internet System Handbook, eds. D. C. Lynch and M. T. Rose, pp. 3-14. Addison-Wesley, Reading, Mass.
Ранние дни Internet: ARPANET.
Macklem, R. 1991. "Lessons Learned Tuning the 4.3BSD Reno Implementation of the NFS Protocol", Proceedings of the 1991 Winter USENIX Conference, pp. 53-64, Dallas, Tex.
Описывает реализацию NFS, который использует и UDP, и TCP.
Malkin, G. S. 1993a. "RIP Version 2: Carrying Additional Information", RFC 1388, 7 pages (Jan.).
Malkin, G. S. 1993b. "Traceroute Using an IP Option", RFC 1393, 7 pages (Jan.).
Предлагаемые модификации для ICMP, предназначенные для новой версии traceroute.
Mallory, T., and Kullberg, A. 1990. "Incremental Updating of the Internet Checksum", RFC 1141, 2 pages (Jan.).
Описывает технику расчета контрольной суммы.
Manber, U. 1990. "Chain Reactions in Networks", IEEE Computer, vol. 23, no. 10, pp. 57-63 (Oct.).
Описывает типы "широковещательного шторма" (неконтролируемый рост числа широковещательных сообщений) и "паводков" в сети, это примерно то, что мы показали в упражнениях 9.3 и 9.4.
McCanne, S., and Jacobson, V. 1993. "The BSD Packet Filter: A New Architecture for User-Level Packet Capture", Proceedings of the 1993 Winter USENIX Conference, pp. 259-269, San Diego, Calif.
Подробное описание пакетного фильтра BSD и сравнение с "краником" в сетевом интерфейсе от Sun (NIT).
McCloghrie, K., and Rose, M. T. 1991. "Management Information Base for Network Management of TCP/IP-based Internets: MIB-II", RFC 1213 (Mar.).
McGregor, G. 1992. "PPP Internet Protocol Control Protocol (IPCP)", RFC 1332, 12 pages (May).
Описание NCP для PPP, как это решено в TCP/IP.
Mills, D. L. 1992. "Network Time Protocol (Version 3): Specification, Implementation, and Analysis", RFC 1305, 113 pages (Mar.).
Mockapetris, P. V. 1987a. "Domain Names: Concepts and Facilities", RFC 1034, 55 pages (Nov.).
Введение в DNS.
Mockapetris, P. V. 1987b. "Domain Names: Implementation and Specification", RFC 1035, 55 pages (Nov.).
Спецификация DNS.
Mogul, J. C. 1990. "Efficient Use of Workstations for Passive Monitoring of Local Area Networks", Computer Communications Review, vol. 20, no. 4, pp. 253-263 (Sept.).
Описывает использование рабочих станций для мониторинга локальных сетей, вместо дорогостоящих специализированных аппаратных анализаторов сети.
Mogul, J. C. 1992. "Holy Turbocharger Batman, (evil cheating), NFS async writes", Message-ID <1992Mar2.191711.9935@PA.dec.com>, Usenet, comp.protocols.nfs Newsgroup (Mar.).
Интересная статистика по ошибкам в контрольных суммах, собранная на загруженном DNS сервере за 40 дней.
Mogul, J. C. 1993. "IP Network Performance", in Internet System Handbook, eds. D. C. Lynch and M. T. Rose, pp. 575-675. Addison-Wesley, Reading, Mass.
Описывает множество аспектов в протоколах TCP/IP, которые могут быть настроены для повышения производительности.
Mogul, J. C., and Deering, S. E. 1990. "Path MTU Discovery", RFC 1191, 19 pages (Apr.).
Mogul, J. C., and Postel, J. B. 1985. "Internet Standard Subnetting Procedure", RFC 950, 18 pages (Aug.).
Moore, K. 1993. "MIME (Multipurpose Internet Mail Extensions) Part Two: Message Header Extensions for Non-ASCII Text", RFC 1522, 10 pages (Sept.).
Описывает способы отправки не-ASCII символов в заголовках почтовых сообщений по RFC 822, с использованием 7-битного ASCII.
Moy, J. 1991. "OSPF Version 2", RFC 1247, 189 pages (July).
Nagle, J. 1984. "Congestion Control in IP/TCP Internetworks", RFC 896, 9 pages (Jan.).
Описание алгоритма Нагла.
Nye, A., ed. 1992. The X Window System, Volume 0: X Protocol Reference Manual, Third Edition. O'Reilly & Associates, Sebastopol, Calif.
Obraczka, K., Danzig, P. B., and Li, S. 1993. "Internet Resource Discovery Services", IEEE Computer, vol. 26, no. 9, pp. 8-22 (Sept.).
Представляет обзор современных средств поиска ресурсов Internet: Alex, Archie, Gopher, Indie, Knowbot Information Service, Netfind, Prospero, WAIS, WWW и X.500. PostScript копию можно получить через анонимный FTP с хоста ftp.caldera.usc.edu, имя файла /pub/kobraczk/ieeecomputer.ps.Z.
Papadopoulos, C., and Parulkar, G. M. 1993. "Experimental Evaluation of SunOS IPC and TCP/IP Protocol Implementation", IEEE/ACM Transactions on Networking, vol. 1, no. 2 (Apr.).
Оценивает дополнения, которые дополняются разными уровнями и передаются и принимаются как данные.
Partridge, C. 1986. "Mail Routing and the Domain System", RFC 974, 7 pages (Jan.).
Как используются DNS MX записи для маршрутизации почты.
Partridge, C. 1994. Gigabit Networking. Addison-Wesley, Reading, Mass.
Описывает, что случается, когда скорости достигают гигабитного предела.
Partridge, C., and Pink, S. 1993. "A Faster UDP", IEEE/ACM Transactions on Networking, vol. 1, no. 4 (Aug.).
Описывает улучшение кодов Berkeley, которые позволяют повысить производительность работы UDP примерно на 30%.
Paxson, V. 1993. "Empirically-Derived Analytic Models of Wide-Area TCP Connections: Extended Report", LBL-34086, Lawrence Berkeley Laboratory and EECS Division, University of California, Berkeley (June).
Приводится анализ 2,5 миллионов TCP соединений открытых по 14-ти маршрутам в глобальных сетях. PostScript копию этого отчета можно получить через анонимный FTP с хоста ftp.ee.lbl.gov, файлы WAN-TCP-models.1.ps.Z и WAN-TCP-models.2.ps.Z.
Perlman, R. 1992. Interconnections: Bridges and Routers. Addison-Wesley, Reading, Mass.
Подробное описание методов связывания сетей (мосты и маршрутизаторы) и различных алгоритмов маршрутизации.
Plummer, D. C. 1982. "An Ethernet Address Resolution Protocol", RFC 826, 10 pages (Nov.).
Postel, J. B. 1980. "User Datagram Protocol", RFC 768, 3 pages (Aug.).
Postel, J. B., ed. 1981a. "Internet Protocol", RFC 791, 45 pages (Sept.).
Postel, J. B. 1981b. "Internet Control Message Protocol", RFC 792, 21 pages (Sept.).
Postel, J. B., ed. 1981c. "Transmission Control Protocol", RFC 793, 85 pages (Sept.).
Postel, J. B. 1982. "Simple Mail Transfer Protocol", RFC 821, 68 pages (Aug.).
Postel, J. B. 1987. "TCP and IP Bake Off", RFC 1025, 6 pages (Sept.).
Описывает некоторые процедуры и осуществляет оценку различных реализаций TCP/IP в ранней стадии развития, с точки зрения совместимости.
Postel, J. B., ed. 1993. "Internet Official Protocol Standards", RFC 1500, 36 pages (Aug.).
Статус всех протоколов Internet. Этот RFC регулярно обновляется - убедитесь, что Вы читаете последний по индексу.
Postel, J. B., and Reynolds, J. K. 1983a. "Telnet Protocol Specification", RFC 854, 15 pages (May).
Основная спецификация протокола Telnet. Более поздние RFC описывают отдельные опции Telnet.
Postel, J. B., and Reynolds, J. K. 1983b. "Telnet Binary Transmission", RFC 856, 4 pages (May).
Postel, J. B., and Reynolds, J. K. 1983c. "Telnet Echo Option", RFC 857, 5 pages (May).
Postel, J. B., and Reynolds, J. K. 1983d. "Telnet Suppress Go Ahead Option", RFC 858, 3 pages (May).
Postel, J. B., and Reynolds, J. K. 1983e. "Telnet Status Option", RFC 859, 3 pages (May).
Postel, J. B., and Reynolds, J. K. 1983f. "Telnet Timing Mark Option", RFC 860, 4 pages (May).
Postel, J. B., and Reynolds, J. K. 1985. "File Transfer Protocol (FTP) ", RFC 959, 69 pages (Oct.).
Postel, J. B., and Reynolds, J. K. 1988. "Standard for the Transmission of IP Datagrams over IEEE 802 Networks", RFC 1042, 15 pages (Apr.).
Спецификация на инкапсуляцию IP датаграмм и ARP запросов и рассмотрение сетей IEEE 802.
Pusateri, T. 1993. "IP Multicast Over Token-Ring Local Area Networks", RFC 1469, 4 pages (June).
Rago, S. A. 1993. UNIX System V Network Programming. Addison-Wesley, Reading, Mass.
Книга про TLI и потоковую подсистему.
Rekhter, Y., and Gross, P. 1991. "Application of the Border Gateway Protocol in the Internet", RFC 1268, 13 pages (Oct.).
Rekhter, Y., and Li, T. 1993. "An Architecture for IP Address Allocation with CIDR", RFC 1518, 27 pages (Sept.).
Reynolds, J. K. 1989. "The Helminthiasis of the Internet", RFC 1135, 33 pages (Dec.).
Подробное описание червя в Internet в 1988 году.
Reynolds, J. K., and Postel, J. B. 1992. "Assigned Numbers", RFC 1340, 138 pages (July).
Все магические числа семейства протоколов Internet. Этот RFC регулярно обновляется. Проверьте по индексу, какая версия последняя.
Romkey, J. L. 1988. "A Nonstandard for Transmission of IP Datagrams Over Serial Lines: SLIP", RFC 1055, 6 pages (June).
Rose, M. T. 1990. The Open Book: A Practical Perspective on OSI. Prentice-Hall, Englewood Cliffs, N.J.
Книга про OSI протоколы. В главе 8 приводится описание ASN.1 и BER.
Rose, M. T. 1993. The Internet Message: Closing the Book with Electronic Mail. Prentice-Hall, Englewood Cliffs, N.J.
Книга о почте Internet с подробным описанием MIME.
Rose, M. T. 1994. The Simple Book: An Introduction to Internet Management, Second Edition. Prentice-Hall, Englewood Cliffs, N.J.
Книга о SNMPv2. Первая редакция описывает SNMPv1.
Rose, M. T., and McCloghrie, K. 1990. "Structure and Identification of Management Information for TCP/IP-based Internets", RFC 1155, 22 pages (May).
Определяет SMI для SNMPv1.
Rosenberg, W., Kenney, D., and Fisher, G. 1992. Understanding DCE. O'Reilly & Associates, Sebastopol, Calif.
Обзор Distributed Computing Environment OSF.
Routhier, S. A. 1993. "Implementation Experience for SNMPv2", The Simple Times, vol. 2, no. 4, pp. 1-4 (July-Aug.).
Описывает необходимые модификации для SNMPv1, обеспечивающие поддержку SNMPv2. Этот журнал распространяется электронным образом, абсолютно бесплатно. Пошлите почту с указанием help в поле subject на st-subscriptions@simple-times.org, чтобы получить информацию о подписке.
Schryver, V. J. 1993. "Info on High Speed Transport Protocols Requested", Message-ID <i0imr8g@rhyolite.wpd.sgi.com>, Usenet, comp.protocols.tcp-ip Newsgroup (May).
Некоторые подробности о производительности TCP по FDDI.
Schwartz, M. F., and Tsirigotis, P. G. 1991. "Experience with a Semantically Cognizant Internet White Pages Directory Tool", Journal of Internetworking Research and Experience, vol. 2, no. 1, pp. 23-50 (Mar.).
Также доступна по анонимному FTP с хоста ftp.cs.colorado.edu в файле pub/cs/techreports/schwartz/PostScript/White.Pages.ps.Z.
Simpson, W. A. 1992. "Point-to-Point Protocol (PPP) for the Transmission of Multi-Protocol Datagrams Over Point-to-Point Links.", RFC 1331, 66 pages (May).
Описывает PPP и его управляющий протокол.
Sollins, K. R. 1992. "The TFTP Protocol (Revision 2)", RFC 1350, 11 pages (July).
Stallings, W. 1987. Handbook of Computer-Communications Standards, Volume 2: Local Network Standards. Macmillan, New York.
Содержит подробное описание стандартов IEEE 802.
Stallings, W. 1993. SNMP, SNMPv2, and CMIP: The Practical Guide to Network-Management Standards. Addison-Wesley, Reading, Mass.
Описывает разницу между SNMPv1 и SNMPv2.
Stern, H. 1991. Managing NFS and NIS. O'Reilly & Associates, Sebastopol, Calif.
Подробное описание процедуры инсталляции, использование и администрирования NFS.
Stevens, W. R. 1990. UNIX Network Programming. Prentice-Hall, Englewood Cliffs, N.J.
Аспекты сетевого программирования в среде Unix.
Stevens, W. R. 1992. Advanced Programming in the UNIX Environment. Addison-Wesley, Reading, Mass.
Программирование в Unix.
Sun Microsystems. 1987. "XDR: External Data Representation Standard", RFC 1014, 20 pages (June).
Sun Microsystems. 1988a. "RPC: Remote Procedure Call, Protocol Specification, Version 2", RFC 1057, 25 pages (June).
Sun Microsystems. 1988b. "NFS: Network File System Protocol Specification", RFC 1094, 27 pages (Mar.).
Спецификация второй версии Sun NFS.
Sun Microsystems. 1993. NFS: Network File System Version 3 Protocol Specification. Sun Microsystems, Mountain View, Calif.
PostScript копию этого документа можно получить через анонимный FTP с хоста ftp.uu.net в файле networking/ip/nfs/NFS3.spec.ps.z.
Tanenbaum, A. S. 1989. Computer Networks, Second Edition. Prentice-Hall, Englewood Cliffs, N.J.
Общее описание компьютерных сетей.
Topolcic, C. 1993. "Status of CIDR Deployment in the Internet", RFC 1467, 9 pages (Aug.).
Tsuchiya, P. F. 1991. "On the Assignment of Subnet Numbers", RFC 1219, 13 pages (Apr.).
Рекомендации по назначению идентификаторов подсетей с битов старшего порядка вниз, а идентификаторов хостов с битов младшего порядка вверх. Это позволяет легко менять маску подсети в будущем без изменения нумерации всей системы.
Ullmann, R. 1993. "TP/IX: The Next Internet", RFC 1475, 35 pages (June).
Еще одно предложение о будущем развитии протоколов Internet.
VanBokkelen, J. 1989. "Telnet Terminal-Type Option", RFC 1091, 7 pages (Feb.).
Waitzman, D. 1988. "Telnet Window Size Option", RFC 1073, 4 pages (Oct.).
Waitzman, D., Partridge, C., and Deering, S. E. 1988. "Distance Vector Multicast Routing Protocol", RFC 1075, 24 pages (Nov.).
Warnock, R. P. 1991. "Need Help Selecting Ethernet Cards for Very High Performance Throughput Rates", Message-ID <lbhal10@sgi.sgi.com>, Usenet, comp.protocols.tcp-ip Newsgroup (Sept.).
Производительность TCP, которую мы вычислили на рисунке 24.9.
Weider, C., Reynolds, J. K., and Heker, S. 1992. "Technical Overview of Directory Services Using the X.500 Protocol", RFC 1309, 16 pages (Mar.).
Wimer, W. 1993. "Clarifications and Extensions for the Bootstrap Protocol", RFC 1532, 22 pages (Oct.).
X/Open. 1991. Protocols for X/Open Internetworking: XNFS. X/Open, Reading, Berkshire, U.K.
Лучшее описание Sun RPC, XDR и NFS. Также содержит описание менеджера блокировки NFS и протоколов монитора статуса, а также приложения, описывающие различия между доступом к NFS файлам и локальным файлам. Номер X/Open документа XO/CAE/91/030.
Zimmerman, D. P. 1991. "Finger User Information Protocol", RFC 1288, 12 pages (Dec.).
Назад
Компания | Услуги | Для клиентов | Библиотека | Галерея | Cофт | Линки
На главную
Программа host (глава 14)
Программа host (глава 14)
Программа host находится на хосте ftp.nikhefh.nikhef.nl в файле host.tar.Z.
Программа icmpaddrmask (глава
Программа icmpaddrmask (глава 6, раздел "ICMP запрос и отклик маски адреса")
Обратитесь к последнему пункту этого раздела.
Программа icmptime (глава 6, раздел
Программа icmptime (глава 6, раздел "ICMP запрос и отклик временной марки")
Обратитесь к последнему пункту этого раздела.
Программа ping (глава 7)
Программа ping (глава 7)
BSD версия программы ping обычно имеет больше опций и характеристик, чем версии, поставляемые другими производителями. Хост ftp.uu.net содержит последнюю BSD версию в файле systems/unix/bsd-sources/sbin/ping.
Программа sock (приложение C)
Программа sock (приложение C)
Обратитесь к последнему пункту этого раздела.
Программа tcpdump (приложение A)
Программа tcpdump (приложение A)
Версия tcpdump, которая используется в этом тексте, взята с хоста ftp.ee.lbl.gov из файла tcpdump-2.2.1.tar.Z.
Программа traceroute (глава 8)
Программа traceroute (глава 8)
Программа traceroute доступна с ftp.ee.lbl.gov. Обратитесь к последнему пункту в этом разделе, где рассказывается, какая версия используется в разделе "Опция IP маршрутизации от источника" главы 8, что позволяет рассмотреть жесткую и свободную маршрутизации от источника.
Программа traceroute.pmtu (глава
Программа traceroute.pmtu (глава 11, раздел "Определение транспортного MTU с использованием Traceroute")
Обратитесь к последнему пункту этого раздела.
Программа ttcp
Программа ttcp
(Программа ttcp не использовалась в тексте, однако это очень полезное средство, с помощью которого читатели могут многого добиться.) ttcp это средство для определения TCP и UDP производительности между двумя системами. Она была создана в исследовательской лаборатории баллистики американской армии (BRL) и сейчас общедоступна. Копии находятся на большом количестве анонимных FTP серверов, однако расширенная версия находится на хосте ftp.sgi.com в директории sgi/src/ttcp.
Программное обеспечение групповой рассылки IP (глава 13)
Программное обеспечение групповой рассылки IP (глава 13)
Модификации, которые необходимо сделать для поддержки групповой рассылки IP для SunOS 4.x и Ultrix, можно получить с хоста ftp.gregorio.stanford.edu в директории vmtp-ip. В этой директории также содержатся исходные коды модификаций, необходимых для реализации групповой рассылки IP в системах Berkeley Unix.
Программы dig и doc (глава 14)
Программы dig и doc (глава 14)
Программы dig и doc, которые мы упомянули в главе 14, можно получить с хоста ftp.isi.edu в файлах dig.2.0.tar.Z и doc.2.0.tar.Z.
Программы и примеры MIME (глава
Программы и примеры MIME (глава 28, раздел "Будущее SMTP")
Программа под названием MetaMail, которая предоставляет возможности MIME для большинства различных пользовательских агентов, есть на хосте ftp.thumper.bellcore.com в директории pub/nsb. Также в этой директории находится дополнительная информация о MIME.
Программы, написанные автором
Программы, написанные автором
Программы, написанные автором, которые используются в этой книге, можно получить с хоста ftp.uu.net в директории published/books/stevens.tcpipiv1.tar.Z.
Назад
Компания | Услуги | Для клиентов | Библиотека | Галерея | Cофт | Линки
На главную
RFC (глава 1, раздел "RFC")
RFC (глава 1, раздел "RFC")
В разделе "RFC" главы 1 приводятся адреса электронной почты, на которые необходимо отправлять запросы. В ответе будет приведено определенное количество узлов, с которых можно получить RFC, используя либо электронную почту (e-mail), либо анонимный FTP.
Запомните, что начинать надо с того, что получить текущий индекс и найти RFC, который Вас интересует в этом индексе. Это позволит Вам получить самый полный и самый новый RFC.
А.1 Пакетный фильтр BSD.
Рисунок А.1 Пакетный фильтр BSD.

BPF помещает драйвер Ethernet устройства в смешанный режим и затем получает от драйвера копию каждого полученного и отправленного пакета. Эти пакеты проходят через фильтр, указанный пользователем, таким образом, только те пакеты, которые интересуют пользователя, попадают в обработку.
Несколько процессов могут наблюдать за указанным интерфейсом, и каждый процесс использует свой собственный фильтр. На рисунке А.1 показаны пример работы tcpdump и демона RARP (глава 5, раздел "Реализация RARP сервера"), оба наблюдают за одним и тем же Ethernetом. При каждом появление tcpdump используется собственный фильтр. Фильтр для tcpdump может быть указан пользователем в командной строке, тогда как rarpd всегда использует один и тот же фильтр для отлова только RARP запросов.
Помимо указанного фильтра, каждый пользователь BPF также указывает значение тайм-аута. Так как скорость данных в сети может легко переполнить мощности процессора, и так как не очень эффективно осуществлять маленькие чтения из ядра, BPF старается упаковать несколько фреймов в один буфер чтения и возвратить только тогда, когда буфер полон или истек тайм-аут, установленный пользователем. tcpdump устанавливает тайм-аут в 1 секунду, так как он обычно получает от BPF много данных, тогда как демон RARP получает немного фреймов, поэтому rarpd устанавливает тайм-аут в 0 (фрейм возвращается при получении).
Фильтр, указанный пользователем, сообщает BPF, какие фреймы необходимо обрабатывать. Эти инструкции интерпретируются фильтром BPF в ядре. Фильтрация в ядре, а не в пользовательском процессе, уменьшает количество данных, которые должны быть переданы от ядра пользовательскому процессу. Демон RARP всегда использует одну и ту же программу фильтрации, которая встроена в программу. tcpdump, с другой стороны, позволяет пользователю указать выражение фильтрации в командной строке при каждом запуске. tcpdump конвертирует выражение, указанное пользователем, в соответствующую последовательность инструкций для BPF. В качестве примера tcpdump можно привести выражение:
% tcpdump tcp port 25
% tcpdump 'icmp[0] != 8 and icmp[0] != 0'
В первом случае печатаются только TCP сегменты с портом источника или назначения равным 25. Во втором случае печатаются только ICMP сообщения, которые не являются эхо запросами или эхо откликами (не ping пакеты). Эти выражения указывают, что первый байт ICMP сообщения (поле type на рисунке 6.2) не должен быть равен 8 или 0, что соответствует эхо запросам или эхо откликам на рисунке 6.3. Как Вы можете видеть, грамотная фильтрация требует знаний структуры пакета. Выражение во втором примере, заключено в одиночные кавычки, что предотвращает от интерпретации командным интерпретатором Unix (shell) специальных символов.
Обратитесь к страницам помощи tcpdump(1), где приведены детали о выражениях, которые могут быть указаны пользователем. В страницах помощи bpf(4) приведены инструкции виртуальной машины, используемой BPF. [McCanne and Jacobson 1993] сравнивает реализацию и производительность этой машины с другими подходами.
А.2 Краник в сетевом интерфейсе SunOS.
Рисунок А.2 Краник в сетевом интерфейсе SunOS.
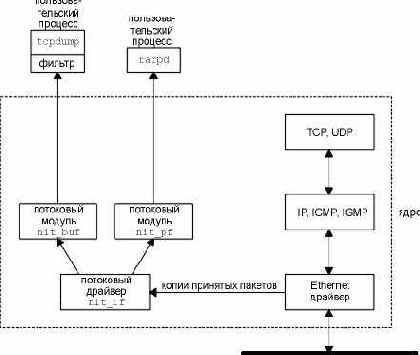
Фильтрация, указанная пользователем, осуществляется потоковым модулем nit_pf. На рисунке А.2 этот модуль используется демоном RARP, однако не используется tcpdump. Вместо этого под SunOS tcpdump осуществляет свою собственную фильтрацию в пользовательском процессе. Причина этого в том, что инструкции виртуальной машины, используемые nit_pf, отличаются (а также они не такие мощные) от тех, которые поддерживаются BPF. Это означает, что когда пользователь указывает выражение фильтрации tcpdump, больше данных пересекают границу между ядром к пользователю с использованием NIT, чем при использовании BPF.
А.3 Вывод команды tcpdump для рисунка 4.4.
Рисунок А.3 Вывод команды tcpdump для рисунка 4.4.
D.1 Количество сетей в сети NSFNET.
Рисунок D.1 Количество сетей в сети NSFNET.

Пунктирная линия примерно показывает максимальное количество сетей, которое будет достигнуто к 2000 году, если продолжится экспоненциальный рост количества сетей.
"Будь либеральным к тому, что принимаешь, и требовательным к тому, что отправляешь."
Глава 3 Нет, любой адрес класса сети с идентификатором, начинающимся со 127, имеет право существовать, однако большинство систем использует 127.0.0.1. kpno имеет пять интерфейсов: три канала точка-точка и два Ethernetа. R10 имеет четыре интерфейса Ethernet. gateway имеет три интерфейса: два канала точка-точка и один Ethernet. И netb имеет один интерфейс Ethernet и два канала точка-точка. Нет никакой разницы: оба имеют маски подсети 255.255.255.0, как адреса класса С, которые не поделены на подсети. Можно. Это называется непересекающиеся сетевые маски, так как 16 бит, выделенные под маску подсети, не пересекаются. RFC, однако, рекомендует не использовать непересекающиеся сетевые маски. Так сложилось исторически. Значение получилось как 1024 + 512 при этом напечатанные значения MTU включают все требуемые заголовки. Solaris 2.2 устанавливает MTU для loopback интерфейса равный 8232 (8192 + 40), что вмещает в себя 8192 байта пользовательских данных вместе с обычным 20-байтовым IP заголовком и 20-байтовым TCP заголовком. Во-первых, с датаграммами значительно легче работать маршрутизаторам. Во-вторых, на основе датаграмм могут быть основаны и ненадежные (UDP) и надежные (TCP) транспортные уровни. В-третьих, датаграммы представляют собой минимальное представление сетевого уровня, что позволяет использовать разнообразные канальные уровни.
Глава 4 Исполнение команды rsh устанавливает TCP соединение с удаленным хостом. При этом начинается обмен IP датаграммами между двумя хостами. При этом требуется, чтобы на удаленном хосте была запись в ARP кэше. Даже если ARP кэш был пуст перед исполнением команды rsh, можно гарантировать, что запись для нашего хоста в ARP кэше появится, перед тем как сервер rsh исполнит команду arp. Убедитесь, что ваш хост не имеет записи в своем ARP кэше для какого-либо другого хоста в той же Ethernet сети, скажем foo. Убедитесь, что foo посылает "беспричинный" ARP запрос при загрузке. Это можно сделать, запустив tcpdump на другом хосте, когда загружается foo. Затем погасите хост foo и внесите неверный пункт в ARP кэш на вашей системе для foo. Используйте команду arp и не забудьте указать опцию temp. Загрузите foo, и когда он загрузился, посмотрите ваш ARP кэш на предмет того, была ли исправлена неверная запись. Прочитайте раздел 2.3.2.2 в требованиях к хостам Host Requirements RFC и раздел "Взаимодействие между UDP и ARP" главы 11 этой книги. Допустим, у клиента существовала полная ARP запись для сервера, когда сервер был выключен. Если мы будем продолжать попытки подсоединиться к серверу (выключенному), тайм-аут ARP будет продлен еще на 20 минут. Когда сервер окончательно перезагрузится с новым аппаратным адресом, и если он не разошлет "беспричинный" ARP, старая неверная ARP запись будет все еще останется у клиента. У нас не будет возможности подсоединиться к серверу на его новый аппаратный адрес до тех пор, пока мы вручную не удалим запись в ARP кэше или прекратим на 20 минут попытки достучаться до сервера.
Глава 5 Разные типы фреймов это не абсолютное требование, так как поле op на рисунке 4.3 имеет различные значения для всех четырех операций (ARP запрос, ARP отклик, RARP запрос и RARP отклик). Однако отличить реализацию RARP сервера от ARP сервера, находящегося в ядре, значительно легче с разными полями в поле типа фрейма. Каждый RARP сервер может осуществить маленькую задержку на случайный момент времени, перед тем как отправить ответ. В качестве усовершенствования, один RARP сервер может быть назначен как первичный, а все остальные как вторичные. Первичный сервер может отвечать без задержки, а вторичные со случайными задержками. Еще одно усовершенствование. В случае использования первичных и вторичных серверов, вторичные сервера могут быть запрограммированы таким образом, чтобы отвечать только на повторные запросы, принятые за короткие промежутки времени. При этом подразумевается, что причина появления повторных запросов заключается в том, что первичный сервер выключен.
Глава 6 Если бы на одном локальном кабеле находилась сотня хостов, каждый попробовал бы послать ICMP ошибку о недоступности порта примерно в одно и то же время. Это привело бы к коллизиям (если используется Ethernet), при этом сеть станет практически бесполезной в течение секунды или двух. В этом случае "следует". ICMP ошибка всегда отправляется с TOS равным 0, как показано на рисунке 3.2. ICMP запрос может быть отправлен с любым TOS, но соответствующий отклик должен быть отправлен с тем же самым TOS. Команда netstat -s обычно используется для того, чтобы посмотреть статистику по протоколам. На хосте SunOS 4.1.1 (gemini), который получил 48 миллионов IP датаграмм, ICMP статистика следующая:
Output histogram: echo reply: 1757 destination unreachable: 700 time stamp reply: 1 Input histogram: echo reply: 211 destination unreachable: 3071 source quench: 249 routing redirect: 2789 echo: 1757 #10: 21 time exceeded: 56 time stamp: 1
21 входное сообщение с типом 10 - это требования к маршрутизатору, которые не поддерживаются SunOS 4.1.1.
При использовании SNMP (рисунок 25.26) некоторые системы, как, например, Solaris 2.2, генерируют вывод netstat -s, который использует имена переменных SNMP.
Глава 7 86 байт поделенные на 960 байт/сек, умноженные на 2 дают 179,2 миллисекунды. Когда ping запущен с этой скоростью, печатаются значения равные 180 миллисекундам. (86 + 48) байт поделенные на 960 байт/сек, умноженные на 2 дают 279,2 миллисекунды. Появление дополнительных 48 байт объясняются тем, что последние 48 байт из 56 байт в части данных должны быть экранированы: 0xc0 это символ END в протоколе SLIP. CSLIP сжимает только TCP и IP заголовки в TCP сегментах. Он не влияет на ICMP сообщения, которые используются программой ping. На SPARCstation ELC ping на loopback адрес дает RTT равное 1,310 миллисекунды, тогда как ping на Ethernet адрес хоста дает RTT равное 1,460 милисекунды. Эта разница объясняется дополнительной обработкой, осуществляемой Ethernet драйвером, который определяет, что датаграмма действительно предназначена локальному хосту. Вам потребуется версия ping, которая дает микросекундное разрешение, чтобы оценить подобную разницу.
Глава 8 Если входящая датаграмма имеет TTL равное 0, вычитание единицы и затем проверка могут установить TTL в значение 255 и продлить существование датаграммы. Несмотря на то, что маршрутизатор никогда не должен получать датаграммы с TTL равным 0, это может произойти. Мы заметили, что traceroute сохраняет 12 байт данных из раздела данных UDP датаграммы, которые содержат время отправки датаграммы. Однако, из рисунка 6.9 видно, что ICMP возвращает только первые 8 байт IP датаграммы, которая вызвала ошибку, там находилось 8 байт UDP заголовка. То есть, значение времени, сохраненное traceroute, не возвратилось в ICMP сообщение об ошибке. traceroute сохранила время, при отправке пакета, а когда был получен ICMP отклик, определила текущее время и, использовав эти два значения, получила RTT. Из главы 7 мы видим, что ping сохраняет время в исходящем ICMP эхо запросе, а сервер отражает эти данные. Это позволяет ping напечатать корректный RTT, даже если пакеты вернулись беспорядочно. Первая строка вывода корректна и указывает на R1. Следующая проба стартует с TTL равным 2, оно уменьшается на единицу в R1. Когда R2 получает датаграмму с уменьшенным на единицу TTL (от 1 до 0), то некорректно перенаправляет ее в R3. R3 видит, что входящий TTL равен 0 и отправляет назад ошибку об истечении времени. Это означает, что вторая строка вывода (для TTL равного 2) указывает на R3, а не на R2. Третья строка вывода корректно указывает на R3. Ошибка присутствует в двух последовательных строках вывода, которые указывают на один и тот же маршрутизатор. В данном случае TTL равное 1 указывает на R1, TTL равное 2 указывает на R2, а TTL равное 3 указывает на R3; однако, когда TTL равно 4, UDP датаграммы достигает пункта назначения со входящим TTL равным 1. Генерируется ICMP ошибка о недоступности порта, однако TTL сообщение об ошибке равно 1 (некорректно скопировано из входящего TTL). ICMP сообщение идет на R3, где TTL уменьшается на единицу, и сообщение отбрасывается. ICMP ошибка об истечении времени не генерируется, так как датаграмма, которая была отброшена, - это ICMP сообщение об ошибке (порт недоступен). Тоже происходит и с пробой, TTL которой равен 5, однако на этот раз исходящая ошибка о недоступности порта стартует с TTL равным 2 (скопировано из входящего TTL), и доходит до R2, где отбрасывается. Ошибка о недоступности порта, соответствующая пробе с TTL равным 6, доходит до R1, где тоже отбрасывается. И, в конце концов, ошибка о недоступности порта для пробы с TTL равным 7 проходит полный путь и возвращается назад с входящим TTL равным 1. (traceroute считает, что прибывающее ICMP сообщение с TTL равным 0 или 1 это одно и то же, поэтому она печатает восклицательный знак после RTT.) И в завершение, строки с TTL равными 1, 2 и 3 корректно идентифицируют R1, R2 и R3, затем следуют три строки, каждая из которых содержит три тайм-аута, за которым следует строка для TTL равного 7, которая идентифицирует пункт назначения. Все эти маршрутизаторы установили исходящий TTL ICMP сообщения в значение 255. Это общепринятая практика. Как мы и ожидали, входящее значение от netb равно 255, однако значение равное 253 от butch означает, что возможно где-то есть "невидимый" маршрутизатор. Иначе в этой точке появился бы входящий TTL равный 254. Точно так же, от enss142.UT.westnet.net мы ожидаем значение равное 252, а не 249. Это означает, что и здесь есть "невидимые" маршрутизаторы, которые некорректно обработали UDP датаграмму, однако они корректно уменьшили TTL и вернули ICMP сообщение.
Необходимо достаточно внимательно просматривать исходящий TTL, так как иногда значение отличается от ожидаемого. Это может объясняться тем, что ICMP сообщение возвращается по другому пути, нежели ушла исходящая UDP датаграмма. В этом примере, однако, существуют именно "невидимые" маршрутизаторы, которые traceroute не нашла при использовании опции свободной маршрутизации от источника.
Клиент ping устанавливает в поле идентификатора в ICMP эхо запросе (рисунок 7.1) свой идентификатор процесса. ICMP эхо отклик содержит это поле идентификатора. Каждый клиент просматривает возвращенное поле идентификатора и обрабатывает только те, которые он послал.Клиент traceroute устанавливает номер порта источника UDP в логическое ИЛИ со своим идентификатором процесса и 32768. Так как возвращенное ICMP сообщение всегда содержит первые 8 байт IP датаграммы, на которую сгенерирована ошибка (рисунок 6.9), что включает целиком UDP заголовок, этот номер порта источника возвращается в ICMP ошибке.
Клиент ping помещает в необязательную часть данных ICMP эхо запроса время, когда был отправлен пакет. Эти необязательные данные должны быть возвращены в ICMP эхо отклике. Это позволяет ping рассчитать точное время возврата, даже если пакеты пришли в беспорядке.Клиент traceroute не может поступить подобным образом, потому что все, что возвращается в ICMP ошибке, - это UDP заголовок (рисунок 6.9), а не UDP данные. Таким образом, traceroute должна помнить, когда она посылает запрос, дождаться отклика и рассчитать разницу во времени.
Это иллюстрирует еще одно различие между Ping и Traceroute: Ping отправляет один пакет в секунду, вне зависимости от того, получены ли какие-либо отклики, тогда как Traceroute отправляет запрос и затем ожидает, придет ли отклик или будет отработан тайм-аут перед отправкой следующего запроса.
Так как Solaris 2.2 стартует на динамически назначаемом UDP порте с номером равным 32768 по умолчанию, существует значительно большая вероятность того, что будет занят порт назначения на хосте назначения.
Глава 9 Когда впервые был разработан стандарт ICMP, RFC 792 [Postel 1981b], разделение на подсети не использовалось. Также, использование перенаправления в одну сеть вместо перенаправления на N хостов (для всех N хостов, находящихся в сети назначения) сохраняет некоторое пространство в таблице маршрутизации. Эта запись не требуется, однако если она удалена, все IP датаграммы, предназначенные slip, посылаются на маршрутизатор по умолчанию (sun), который затем перенаправляет их на маршрутизатор bsdi. Так как sun перенаправляет датаграммы по тому же интерфейсу, по которому они были получены, он отправляет ICMP перенаправление хосту svr4. При этом создается та же самая запись в таблице маршрутизации хоста svr4, которая была удалена, однако в этот раз она создается путем перенаправления, вместо того чтобы создаваться в момент загрузки машины. Когда хост 4.2BSD получает датаграмму, предназначаемую для 140.1.255.255, он определяет, что у него есть маршрут к сети (140.1), поэтому он старается направить датаграмму. Чтобы сделать это, он посылает широковещательный запрос ARP в поисках 140.1.255.255. Так как на запрос не приходит отклик, датаграмма отбрасывается. Если на кабеле существует несколько хостов 4.2BSD, каждый отправляет этот ARP широковещательный запрос в одно и то же время, при этом сеть временно становится практически недоступной. В этом случае отклик приходит на каждый ARP запрос, где сообщается, что каждому хосту 4.2BSD необходимо послать датаграмму на указанный аппаратный адрес (широковещательный запрос Ethernet). Если существует k хостов 4.2BSD на этом кабеле, все получают свой собственный ARP отклик, в результате чего, каждый из них генерирует еще один широковещательный запрос. Каждый хост получает каждую широковещательную IP датаграмму, направляемую на 140.1.255.255, а так как каждый хост сейчас имеет запись в ARP кэше, датаграмма снова направляется на широковещательный адрес. Это продолжается и генерирует так называемое половодье Ethernet (meltdown). [Manber 1990] описывает другие формы цепных реакций в сетях.
Глава 10 Тринадцать из этих маршрутов пришли от kpno: все, за исключением 140.252.101.0 и 140.252.104.0 - это сети, к которым gateway подключен непосредственно. Перед тем как 25 маршрутов, объявленных в потерянной датаграмме, будут обновлены пройдет шестьдесят секунд. В этом нет никакой проблемы, потому что RIP объявляет маршрут умершим только в том случае, если в течение 3-х минут не было обновлений. RIP работает поверх UDP, а UDP предоставляет необязательную контрольную сумму для данных, находящихся в UDP датаграмме (глава 11, раздел "Контрольная сумма UDP"). OSPF, однако, работает поверх IP. Контрольная сумма IP охватывает только IP заголовок, таким образом, OSPF должен добавлять свое собственное поле контрольной суммы. Балансировка загруженности уменьшает вероятность того, что пакеты будут доставлены в беспорядке, что может исказить времена возврата, рассчитанные транспортным уровнем. Это называется простым "расщепленным горизонтом" (технология расщепленных горизонтов основывается на том факте, что бессмысленно отправлять информацию о маршрутах в том направлении, откуда она пришла). На рисунке 12.1 мы показали, что каждый из ста хостов обрабатывает широковещательную UDP датаграмму через драйвер устройства, IP уровень и UDP уровень, где она будет окончательно отброшена, когда будет обнаружено, что UDP порт 520 не обслуживается.
Глава 11 Так как при использовании инкапсуляции IEEE 802 в заголовке находится 8 дополнительных байт, 1465 байт пользовательских данных - это наименьший размер, который вызовет фрагментацию. Для IP посылается 8200 байт, 8192 байта пользовательских данных и 8 байт UDP заголовка. Используя форму записи tcpdump, первый фрагмент это 1480@+ (1480 байт данных, смещение 0 и установлен бит "дальше следуют еще фрагменты"). Второй это 1480@1480+, третий 1480@2960+, четвертый 1480@4440+, пятый 1480@5920+ и шестой 800@7400. 1480 x 5 + 800 = 8200 это количество байт, которые необходимо отправить. Каждый фрагмент размером 1480 байт поделен на три части: два фрагмента по 528 байт и один фрагмент 424 байта. Максимальное число кратное 8, меньшее чем 532 (552 - 20), это 528. Фрагмент размером 800 байт делится на две части: фрагмент размером 528 байт и фрагмент размером 272 байта. Таким образом, из исходной датаграммы размером 8192 байта получается 17 фреймов, которые передаются по SLIP каналу. Нет. Проблема заключается в том, что когда приложение осуществляет тайм-аут и повторную передачу, IP датаграмма, сгенерированная при повторной передаче, имеет новое поле идентификации. Промежуточная сборка осуществляется только для фрагментов, которые имеют одинаковое поле идентификации. Поле идентификации в IP заголовке одно и то же (47942). Во-первых, из рисунка 11.4 мы видим, что у gemini выключен расчет исходящей контрольной суммы UDP. Вполне возможно, что операционная система на этом хосте (SunOS 4.1.1) это одна из тех, что никогда не проверяют входящую контрольную сумму UDP, если не включен расчет исходящей контрольной суммы UDP. Во-вторых, вполне возможно, что большинство UDP траффика это локальный траффик, а не траффик по глобальным сетям. Поэтому нет необходимости исполнять все прихоти свойственные глобальным сетям. Опции свободной и жесткой маршрутизации от источника копируются в каждый фрагмент. Опция временной марки и опция записи маршрута не копируются в каждый фрагмент - они присутствуют только в первом фрагменте. Нет. Мы видели в разделе "Сервер UDP" главы 11, что большинство реализаций могут фильтровать входящие датаграммы, направляемые на заданный номер порта UDP, на основании IP адреса назначения, IP адреса источника и номера порта источника.
Глава 12 Широковещательные запросы сами по себе не увеличивают сетевой траффик, однако они требуют дополнительной обработки на хостах. Широковещательные запросы могут вызвать увеличение сетевого траффика, если получающие хосты некорректно отвечают с помощью ошибок, таких как ICMP ошибки о недоступности порта. Маршрутизаторы обычно не перенаправляют широковещательные пакеты, однако их перенаправляют мосты, таким образом, широковещательные запросы в сетях, построенных на основе мостов, могут уйти значительно дальше, чем в сетях, построенных на маршрутизаторах. Каждый хост получает копию каждого широковещательного запроса. Интерфейсный уровень получает фрейм и передает его в драйвер устройства. Если поле типа принадлежит какому-либо другому протоколу, драйвер устройства отбрасывает фрейм. Сначала исполним netstat -r, чтобы посмотреть таблицу маршрутизации. Она покажет имена всех интерфейсов. Затем запустим ifconfig (глава 3, раздел "Команда ifconfig") для каждого интерфейса: флаги расскажут нам, поддерживает ли интерфейс широковещательные запросы, и если да, то в выводе также будут показаны широковещательные адреса. Berkeley реализации не позволяют фрагментировать широковещательные датаграммы. Когда мы указываем длину равную 1472 байта, результирующая IP датаграмма будет длиной ровно 1500 байт, что равно MTU Ethernet. Запрет на фрагментацию широковещательных датаграмм это политическое решение. Технической причины не существует (а именно, никакой другой причины, нежели просто уменьшить количество широковещательных пакетов). В зависимости от того, поддерживается ли групповая рассылка в различных сетевых платах Ethernet на 100 хостах, групповая датаграмма может быть игнорирована сетевой платой или отброшена драйвером устройства.
Глава 13 Используйте некоторые уникальные значения для хоста при генерации случайных значений. IP адрес и адрес канального уровня это два значения, которые должны отличаться на каждом хосте. Время дня это плохой выбор, особенно если все хосты используют, например, протокол NTP для синхронизации своих часов. Они добавляют заголовок протокола приложения, который включает номер последовательности и временную марку.
Глава 14 Разборщик - это всегда клиент, однако сервер имен это и клиент, и сервер. Возвращенный вопрос, он рассчитан для первых 44 байт. Единственный ответ занимает оставшийся 31 байт: 2-байтный указатель на имя домена (указатель на имя домена в вопросе), 10 байт на поля фиксированного размера (тип, класс, TTL и длина ресурса) и 19 байт для данных ресурса (имя домена). Обратите внимание, что имя домена в данных ресурса (svr4.tuc.noao.edu.) не делит суффикс с именем домена в вопросе (34.13.252.140.in-addr.arpa.), таким образом, указатель не может быть использован. Использование обратного порядка означает использование, во-первых, DNS, и затем, если это не сработает, попытку конвертировать аргумент в номер, состоящий из десятичных чисел, разделенных точками (форма записи IP адреса). Это означает, что каждый раз, когда используется адрес в виде десятичных цифр, разделенных точками, используется DNS, при этом привлекается DNS сервер. На это тратятся дополнительные ресурсы. Раздел 4.2.2 RFC 1035 указывает, что перед реальным DNS сообщением должна стоять 2-байтовая длина. Когда сервер имен стартует, он обычно читает (вполне возможно, устаревший) список корневых серверов из дискового файла. Затем он старается установить контакт с одним из этих корневых серверов, запрашивая записи сервера имен (тип запроса NS) для корневого домена. При этом возвращается текущий список корневых серверов. Минимум, что необходимо для этого, это чтобы хотя бы одна запись в стартовом файле на диске соответствовала текущему положению. Регистрационный сервер InterNIC обновляет корневые сервера три раза в неделю. Разборщик функционирует как приложение; если система сконфигурирована таким образом, чтобы использовать несколько DNS серверов, разборщик не может отслеживать времена возврата до различных DNS серверов. Это может привести к возникновению тайм-аутов на слишком короткие запросы разборщика, при этом будут происходить ненужные повторные передачи. Сортировка записей А должна осуществляться разборщиком, а не сервером имен, так как разборщик обычно знает больше, чем сервер, о топологии сети клиента. (Новые релизы BIND предоставляют разборщику возможность сортировать А записи.)
Глава 15 TFTP запросы, посылаемые на широковещательный адрес, должны быть игнорированы. Как указывается в требованиях к хостам Host Requirements RFC, ответы на широковещательные запросы могут создать значительные проблемы в безопасности. Проблема, однако, заключается в том, что не все реализации и API предоставляют адрес назначения для UDP датаграмм для процессов, которые получают датаграммы (глава 11, раздел "Сервер UDP"). По этой причине многие TFTP серверы не следуют этому ограничению. К сожалению, RFC ничего не говорит о подобном переходе номера блоков. Реализации должны иметь возможность передавать файлы размером до 33553920 байт (65535 x 512). Большинство реализаций выдают ошибку, когда размер файла превышает 16776704 (32767 x 512), так как они некорректно определяют количество блоков в виде 16-битного целого со знаком, вместо того чтобы использовать целое без знака. Это упрощает реализацию TFTP клиента, что позволяет поместить его в ПЗУ, потому что сервер является отправителем загрузочных файлов, таким образом, сервер должен осуществлять тайм-ауты и повторные передачи. Так как TFTP - протокол с остановкой и ожиданием отклика, он может передавать максимум 512 байт за одну посылку от клиента серверу. Максимальная пропускная способность TFTP составляет в таком случае 512 байт, поделенных на время возврата между клиентом и сервером. В случае Ethernet (представим время возврата равное 3 миллисекундам), максимальная пропускная способность будет составлять примерно 170000 байт в секунду.
Глава 16 Маршрутизатор должен перенаправлять RARP запросы на какой-либо другой хост, находящийся в другой сети, подключенной к маршрутизатору, однако отправка отклика может вызвать некоторые проблемы. Маршрутизатор также должен перенаправлять RARP отклики.
BOOTP не имеет этих проблем с откликами, так как адрес отклика это обычный IP адрес, причем маршрутизатор всегда знает, как перенаправить информацию на этот адрес. Проблема заключается в том, что RARP использует адреса только канального уровня, а маршрутизаторы обычно не знают этих значений для хостов, находящихся в других, не подключенных непосредственно, сетях.
Он должен использовать свой собственный аппаратный адрес, который должен быть уникальным и который устанавливается в запросе и возвращается в отклике.Глава 17 Все обязательные, за исключением UDP контрольной суммы. Контрольная сумма IP охватывает только IP заголовок, тогда как остальные захватывают все непосредственно после IP заголовка. IP адрес источника, номер порта источника или поле протокола должны быть повреждены. Большинство приложений Internet используют возврат каретки и пропуск строки, чтобы указать на конец каждой записи от приложения. Это кодирование NVT ASCII (глава 26, раздел "Протокол Telnet"). Альтернативным способом является установка префикса перед каждой записью, содержащего счетчик байтов, который используется в DNS (упражнение 4 главы 14) и Sun RPC (глава 29, раздел "Вызов удаленной процедуры Sun"). Как мы видели в разделе "ICMP ошибка недоступности порта" главы 6, ICMP ошибка должна вернуть по крайней мере первые 8 байт, находящиеся позади IP заголовка в IP датаграмме, которая вызвала ошибку. Когда TCP получает ICMP ошибку, он должен проверить два номера порта, чтобы определить какому соединению соответствует ошибка, поэтому номер порта должен находиться в первых 8 байтах TCP заголовка. Существуют опции, находящиеся в конце TCP заголовка, однако в UDP заголовке не существует опций.
Глава 18 ISN это 32-битный счетчик, который перескакивает со значения примерно 4294912000 на 8704, приблизительно через 9,5 часов после того, как система была загружена. По прошествию еще примерно 9,5 часов он перескакивает на 17408, затем на 26112 еще после 9,5 часов, и так далее. Так как ISN стартует с 1, когда система загружается, и так как минимальный порядок циклов цифр через 4, 8, 2, 6 и 0, ISN всегда должен быть нечетным числом. В первом случае мы использовали нашу программу sock, а она по умолчанию передает Unix символ новой строки так, как он есть - один ASCII символ 012 (восьмеричный). Во втором случае мы использовали Telnet клиента, а он конвертирует Unix символ новой строки в два ASCII символа - возврат каретки (восьмеричный 015), за которым следует пропуск строки (восьмеричный 012). В случае полузакрытого соединения один конец отправляет FIN и ожидает данные или FIN с удаленного конца. Полуоткрытое соединение это когда один конец вышел из строя, но это неизвестно удаленному концу. Соединение может войти в состояние ожидания 2MSL только в том случае, если оно уже было в состоянии ESTABLISHED. Во-первых, сервер дневного времени осуществляет активное закрытие TCP соединения после того, как он выдал дату и время клиенту. Это ясно из сообщения, напечатанного нашей программой sock: "connection closed by peer" (соединение закрыто удаленным концом). Клиент в этом соединении прошел через состояние пассивного закрытия. Это помещает пару сокетов в состояние TIME_WAIT на сервере, но не на клиенте. Затем, как показано на рисунке 18.6, большинство Berkeley реализаций позволяют прибыть новому запросу на соединение на пару сокетов, находящуюся в состоянии TIME_WAIT, это как раз то, что произошло в данном случае. Сброс посылается в ответ на FIN, потому что FIN прибывает для соединения, которое было в состоянии CLOSED. Сторона, которая набирает номер, осуществляет активное открытие. Сторона, на которой звонит телефон, осуществляет пассивное открытие. Одновременное открытие не разрешено, однако разрешено одновременное закрытие. Мы бы увидели только ARP запросы, а не TCP сегменты SYN, однако ARP запросы имеют то же временное расписание, как и на рисунке. Клиент это хост solaris, а сервер это хост bsdi. Подтверждение клиента (ACK) на SYN сервера комбинируется с первым сегментом данных от клиента (строка 3). Это полностью допустимо по правилам TCP, однако большинство реализаций так не поступают. Затем клиент посылает свой FIN (строка 4) не дождавшись ACK на свои данные. Это позволяет серверу подтвердить и данные, и FIN в строке 5. Этот обмен (отправка одного сегмента данных от клиента к серверу) требует 7 сегментов. Обычное установление и прекращение соединения (рисунок 18.13), вместе с одним сегментом данных и его подтверждением, требуют 9 сегментов. Во-первых, подтверждение сервера (ACK) на FIN клиента обычно не задерживается (мы обсуждаем задержанные ACK в разделе "Задержанные подтверждения" главы 19), а отправляется сразу же, по прибытию FIN. В этом случае, когда приложение получает EOF, оно сообщает своему TCP о необходимости закрыть свой конец соединения. Во-вторых, сервер, который получил FIN, не должен закрывать свой конец соединения по получении FIN от клиента. Как мы видели в разделе "Наполовину закрытый TCP" главы 18, данные все еще могут быть отправлены. Если прибывающий сегмент, на который сгенерирован RST, имеет поле ACK, номер последовательности RST берется из поле ACK прибывшего сегмента. Значение ACK равное 1 в строке 6 соответствует ISN равному 26368001 в строке 2. См. [Crowcroft et al. 1992] для получения комментариев о создании уровней. Выдается пять запросов. Представьте, что три пакета используются для установления соединения, один для запроса, один для подтверждения (ACK) запроса, один для отклика, один для ACK на отклик и четыре для того, чтобы закрыть соединение. Это означает, что используется 11 пакетов на один запрос, то есть всего 55 пакетов. При использовании UDP это значение уменьшается до 10 пакетов.
Оно может быть уменьшено до 10 пакетов на запрос, если ACK на запрос комбинируется с откликом (глава 19, раздел "Задержанные подтверждения").
Предел составляет примерно 268 соединений в секунду: максимальное количество номеров TCP порта (65536 - 1024 = 64512, игнорируя заранее известные порты) поделенное на продолжительность состояния TIME_WAIT 2MSL. Дублированный FIN подтверждается, и перестартовывается таймер 2MSL. Получение RST, пока соединение находится в состоянии TIME_WAIT, приводит к тому, что это состояние преждевременно разрывается. Это называется убийство TIME_WAIT. RFC 1337 [Braden 1992a] обсуждает это более подробно и показывает потенциальные проблемы. Простое решение этой проблемы, предложенное в RFC, заключается в том, чтобы игнорировать сегменты RST, пока соединение находится в состоянии TIME_WAIT. Это когда реализация не поддерживает полузакрытое состояние. Если приложение требует, чтобы был отправлен FIN, приложение уже не может больше читать из соединения. Нет. Входящие сегменты данных демультиплексируются с использованием IP адреса источника, номера порта источника, IP адреса назначения и номера порта назначения. Для входящих запросов на соединение, мы видели в разделе "Реализация TCP сервера" главы 18, что TCP сервер обычно может не принять соединение, основываясь на IP адресе назначения.
Глава 19 Две записи приложения, за которыми следует чтение, вызывают задержку, потому что, скорее всего, используется алгоритм Нагла. Первый сегмент (с 8 байтами данных) отправляется, на него ожидается ACK перед отправкой 12 байт данных. Если сервер поддерживает задержанные ACK, он может осуществить задержку до 200 миллисекунд (плюс RTT), перед тем как этот ACK будет получен. В случае 5-байтовых CSLIP заголовков (IP и TCP) и 2-х байт данных, RTT по SLIP каналу для этих сегментов составит примерно 14,5 миллисекунды. Это RTT по Ethernet (обычно 5-10 миллисекунд), к которому необходимо добавить время маршрутизации на sun и bsdi. Таким образом, приведенное время выглядит вполне правдоподобно. На рисунке 19.6 разница во времени между сегментами 6 и 9 составляет примерно 533 миллисекунды. На рисунке 19.8 разница во времени между сегментами 8 и 12 составляет 272 миллисекунды. (Мы рассчитали время для клавиши F2, а не для клавиши F1, так как первое эхо для клавиши F1 на втором рисунке было потеряно.)
Глава 20 Байт с номером 0 это SYN, а байт с номером 8193 это FIN. SYN и FIN занимают по одному байту в пространстве номеров последовательности. Первая запись, которую осуществляет приложение, вызывает отправку первого сегмента с флагом PUSH. Так как BSD/386 всегда использует медленный старт, она ожидает первый ACK перед отправкой остальных данных. В течение этого времени приложение осуществляет следующие три записи, в это же время в TCP буферы записываются данные, которые необходимо отправить. Следующие три сегмента не содержат флага PUSH, так как в буфере данных достаточно для отправки. Здесь к записям приложения начинается применяться медленный старт, при этом каждая запись приложения вызывает отправку сегмента, а так как этот сегмент является последним в буфере, устанавливается флаг PUSH. Необходимо определить емкость, для чего надо решить уравнения ширины пропускания в зависимости от задержки. Результаты будут следующими: 1920 байт в первом случае и 2062 для спутникового канала. Похоже, принимающий TCP объявляет окно равное всего лишь 2048 байт.
Насытить спутниковый канал можно при использовании окна большего, чем 16000 байт.
Нет, потому что TCP может пересобрать пакеты данных после тайм-аута, как мы увидим в разделе "Пересборка пакетов" главы 21. Сегмент 15 это обновление окна, которое посылается TCP модулем автоматически, так как приложение считало данные, поэтому окно было открыто. Это напоминает сегмент 9 на этом же рисунке. Появление сегмента 16 вызвано тем, что приложение закрыло свой конец соединения. При этом отправитель может направить пакеты в сеть с большей скоростью, чем сеть может в действительности обработать. Это называется компрессией ACK или пустым ACK [Mogul 1993, Sec. 15.8.13]. Эта ссылка означает, что в Internet использовалась компрессия ACK, хотя это редко приводит к переполнению.
Глава 21 Следующий тайм-аут устанавливается в 48 секунд: 0 + 4 x 12. Коэффициент равный 4 это следующий множитель при экспотенциальном наращивании. Похоже, что SVR4 все еще использует коэффициент 2D вместо 4D при расчете RTO. Протокол с остановкой и ожиданием подтверждения, который используется в TFTP, ограничен отправкой 512 байт данных за время возврата. 32768/512 x 1,5 это 96 секунд. Показано четыре сегмента, пронумерованные как 1, 2, 3 и 4. Представьте, что они приняты в следующем порядке: 1, 3, 2 и 4. Подтверждения, сгенерированные получателем, будут ACK 1 (нормальный ACK), ACK 1 (дублированный ACK, когда принят сегмент 3, который пришел не в свое время), ACK 3, когда принят сегмент 2 (подтверждающий оба сегмента 2 и 3), и затем ACK 4. В этом случае сгенерирован один дублированный ACK. Если порядок приема будет 1, 3, 4, 2, то будет сгенерировано два дублированных ACK. Нет, потому что наклон все еще вправо-вверх, а не вниз. См. рисунок E.1. На рисунке 21.2 сегменты содержат 256 байт данных, передача по по CSLIP каналу со скоростью 9600 бит/сек между slip и bsdi, занимает примерно 250 миллисекунд. Представим, что сегменты данных не были поставлены в очередь где-нибудь между bsdi и vangogh, они прибыли на vangogh примерно через 250 миллисекунд. Так как это больше чем 200 миллисекунд (величина таймера задержанного ACK), каждый сегмент подтверждается, когда истекает следующий таймер задержанного ACK.
Глава 22 Подтверждения (ACK), возможно, все задержаны на хосте bsdi, потому что нет необходимости посылать их немедленно. Именно поэтому соответственные времена имеют 0,170 и 0,370 в дробной части. Также, похоже на то, что 200-миллисекундный таймер на bsdi запущен примерно на 18 миллисекунд позже, чем тот же самый таймер на sun. Флаг FIN, так же как флаг SYN, занимает 1 байт в пространстве номеров последовательности. Объявленное окно будет на 1 байт меньше, потому что TCP предоставляет место для 1 байта номера последовательности занятого флагом FIN.
Глава 23 Обычно легче активизировать опцию "оставайся в живых", нежели пробы из приложения; пробы "оставайся в живых" требуют меньшей ширины пропускания сети, нежели пробы приложения (так как пробы "оставайся в живых" и ответы не содержат данных); пробы не посылаются, если соединение используется для передачи. Опция "оставайся в живых" может привести к тому, что абсолютно нормальное соединение будет разорвано, потому что сеть временно вышла из строя; интервал между пробами (2 часа) обычно не конфигурируется с точки зрения приложений;
Глава 24 Это означает, что отправляющий TCP поддерживает опцию масштабирования окна, однако не нуждается в том, чтобы масштабировать свое окно для этого соединения. Удаленная сторона (которая получила этот SYN) может затем установить коэффициент масштабирования окна (который может быть равен 0 или нет). 64000: размер принимающего буфера (128000) сдвигается вправо на 1 бит. 55000: размер принимающего буфера (220000) сдвигается вправо на 2 бита. Нет. Проблема заключается в том, что подтверждения доставляются ненадежно (за исключением тех случаев, когда они двигаются вместе с данными), поэтому изменение шкалы, находящееся в ACK, может быть потеряно. 232 x 8 / 120 равно 286 Мбит/сек, что в 2,86 раза больше чем скорость данных FDDI. Каждый TCP должен помнить последнюю временную марку, полученную по любому соединению от каждого хоста. Прочитайте приложение B.2 в RFC 1323 для получения более подробной информации. Приложение должно установить размер принимающего буфера перед установлением соединения с удаленным концом, так как опция масштабирования окна посылается в исходном SYN сегменте. Если получатель подтверждает каждый второй сегмент данных, пропускная способность составляет 1118881 байт в секунду. При использовании окна размером 62 сегмента, с подтверждением каждого 31 сегмента, значение составляет 1158675. Когда опция временной марки отражается эхом в ACK, она всегда берется из сегмента, который подтверждается. В данном случае нет никакой двусмысленности по поводу того, какому повторно переданному сегменту принадлежит ACK, однако другая часть алгоритма Karnа, имеющая отношение к экспотенциальному наращиванию передачи, все еще требуется. Получающий TCP ставит данные в очередь, однако они не могут быть переданы приложению до тех пор, пока не завершится трехразовое рукопожатие: когда получающий TCP переходит в состояние ESTABLISHED. Осуществляется обмен пятью сегментами: От клиента к серверу: SYN, данные (запрос) и FIN. Сервер должен поставить в очередь данные, как описано в предыдущем упражнении. От сервера к клиенту: SYN и ACK на SYN клиента. От клиента к серверу: ACK на SYN сервера и FIN клиента (снова). Это приводит к тому, что сервер переходит в состояние ESTABLISHED, а данные, поставленные в очередь с сегмента 1, передаются приложению сервера. От сервера к клиенту: ACK на FIN клиента (который также подтверждает данные клиента), данные (отклик сервера) и FIN сервера. Здесь подразумевается, что SPT достаточно короток, чтобы позволить этот задержанный ACK. Когда TCP клиент получает этот сегмент, отклик передается приложению клиента, однако полное время будет равно удвоенному RTT плюс SPT. От клиента к серверу: ACK на FIN сервера. 16128 транзакций в секунду (64512 поделено на 4). Время транзакций, используемое T/TCP, не может быть меньше, чем время, необходимое для обмена UDP датаграммами между двумя хостами. T/TCP всегда работает дольше, так как он еще осуществляет обработку состояний, чего не делает UDP.
Глава 25 Если система запускает и менеджера, и агента, это скорее всего разные процессы. Менеджер слушает UDP порт 162 на предмет прихода ловушек, а агент слушает UDP порт 161 для запросов. Если один и тот же порт используется и для ловушек, и для запросов, отделить менеджера от агента будет достаточно сложно. Обратитесь к разделу "Таблица доступа" в разделе "Простые примеры" главы 25.
Глава 26 Мы ожидаем, что сегменты 2, 4 и 9 от сервера будут задержаны. Разница во времени между сегментами 2 и 4 составляет 190,7 миллисекунды, а разница во времени между сегментами 2 и 9 составляет 400,7 миллисекунды.
Все ACK от клиента к серверу будут задержаны: сегменты 6, 11, 13, 15, 17 и 19. Разница во времени последних пяти от сегмента 6 составляет 400,0; 600,0; 800,0; 1000,0 и 2600 миллисекунд.
Если один конец соединения находится в режиме срочности TCP, то каждый раз, когда сегмент принимается, один отправляется. Этот сегмент не сообщает получателю ничего нового (он не подтверждает новые данные, например) и не содержит данных, а всего лишь подтверждает, что соединение находится в срочном режиме. Наличие 512 зарезервированных портов (512-1023) ограничивают количество Rlogin клиентов. Их может быть не больше 512. В реальной жизни значение меньше чем 512, так как некоторые из портов в этом диапазоне используются в качестве заранее известных портов различными сервисами, такими, например, как Rlogin сервер.Ограничение TCP заключается в том, что пара сокетов, выделенная для соединения, должна быть уникальной. Так как Rlogin сервер всегда использует один и тот же заранее известный порт (513), несколько Rlogin клиентов на данном хосте могут использовать один и тот же зарезервированный порт, только если они подсоединены к различным серверам. Клиенты Rlogin, однако, не используют эту технику повторного использования зарезервированных портов. Если эта техника используется, теоретический лимит максимального количества соединений составляет 512 Rlogin клиентов, в одно и то же время подсоединенных к одному и тому же хосту сервера.
Глава 27 Теоретически соединение не может быть установлено, пока пара сокетов находится в состоянии ожидания 2MSL на каком-либо из концов. В действительности, однако, мы видели в разделе "Диаграмма состояний передачи TCP" главы 18, что большинство Berkeley реализаций принимают все-таки новый SYN для соединения, находящегося в состоянии TIME_WAIT. Эти строки не являются частью отклика сервера, который всегда начинается с 3-циферного кода отклика.
Глава 28 domain literal это IP адрес в виде десятичных цифр, разделенных точками, внутри квадратных скобок. Например: mail rstevens@ [140.252.1.54]. Шесть: команда HELO, MAIL, RCPT, DATA, тело сообщения и QUIT. Это вполне законно и называется pipelining [Rose 1993, Sec. 4.4.4]. К сожалению, существуют "сумасшедшие" реализации SMTP, которые очищают свой входной буфер после обработки каждой команды, из-за чего подобная техника не работает. Если эта техника используется, клиент не может отбросить сообщение до тех пор, пока все отклики не будут проверены на предмет того, что сообщение было принято сервером. Рассмотрим первые пять сетевых обменов из упражнения 28.2. Каждый является маленькой командой (возможно, одним сегментом), который совсем немножко загружает сеть. Если все пять пройдут на сервер без повторных передач, окно переполнения должно быть равно шести сегментам, когда отправляется тело. Если тело большое, клиент может послать первые шесть сегментов за раз, что сеть, может быть, не сможет обработать. Новые реализации BIND смешивают MX записи с тем же самым значением, что и форма балансировки загрузки.
Глава 29 Нет, потому что tcpdump не может отличить RPC запрос или отклик от любой другой UDP датаграммы. Единственное случай, когда интерпретируется содержание UDP датаграммы как NFS пакет, это когда номер порта источника или назначения равен 2049. Случайные RPC запросы и отклики могут использовать номер динамически назначаемого порта на каждом конце. Из раздела "Номера портов" главы 1 известно, что процесс должен иметь привилегии суперпользователя, чтобы назначить самому себе номер порта меньше чем 1024 (заранее известный порт). Несмотря на то, что это нормально для серверов, запускаемых системой, таких как Telnet сервер, FTP сервер и Port Mapper сервер, нет необходимости использовать это ограничение для всех RPC серверов. Две концепции, заложенные в этом примере, заключаются в том, что клиент игнорирует любые отклики от сервера, которые не имеют XID, ожидаемые клиентом, а UDP ставит в очередь полученные датаграммы (до определенного предела) до тех пор, пока приложение считывает эти датаграммы. XID не изменяются при тайм-аутах и повторных передачах, они изменяются только когда вызывается еще одна процедура сервера.
События, осуществляемые stubом клиента, следующие: момент времени 0: отправка запроса 1; момент времени 4: тайм-аут и повторная передача запроса 1; момент времени 5: получение отклика 1 от сервера, возвращение отклика приложению; момент времени 5: отправка запроса 2; момент времени 9: тайм-аут и повторная передача запроса 2; момент времени 10: получение отклика 1 от сервера, однако он игнорируется, так как мы ожидаем отклик 2; момент времени 11: получение отклика 2 от сервера, возвращение отклика приложению.
События на сервере следующие: момент времени 0: получение запроса 1, начало операции; момент времени 5: отправка отклика 1; момент времени 5: получение запроса 1 (от повторной передачи клиента в момент времени 4), начало операции; момент времени 10: отправка отклика 1; момент времени 10: получение запроса 2 (от передачи клиента в момент времени 5), начало операции; момент времени 11: отправка отклика 2; момент времени 11: получение запроса 2 (от повторной передачи клиента в момент времени 9), начало операции; момент времени 12: отправка отклика 2. Этот последний отклик сервера просто поставлен клиентским UDP в очередь для следующего приема, осуществляемого клиентом. Когда клиент считывает его, XID будет неверен, и клиент его проигнорирует.
Замена сетевой платы Ethernet меняет физический адрес сервера. Даже несмотря на то, что мы видели в разделе "Беспричинный ARP" главы 4, что SVR4 не посылает "беспричинный" ARP при загрузке, он все равно должен отправить ARP запрос, чтобы узнать физический адрес sun, перед тем как сможет отправить отклик на его NFS запросы. Так как sun уже имеет ARP запись для svr4, он обновит эту запись новым аппаратным адресом сервера из ARP запроса. Второй блок демона ввода-вывода клиента (считывание со смещением 73728) не синхронизирован с первым примерно на 0,74 секунды. Таким образом, второй демон отработает тайм-аут размером 0,74 секунды после первого в строках 131-145. Сервер никогда видел запрос в строке 167, однако увидел запрос в строке 168. Второй блок демона ввода-вывода не будет передан до тех пор, пока не пройдет 0,74 секунды после строки 168, и в это определенное время первый блок демона ввода-вывода продолжает выдавать запросы. Если используется TCP, и TCP сегмент, содержащий отклик от сервера, потерян в сети, TCP модуль сервера осуществит тайм-аут и повторную передачу отклика, когда он не получит ACK от TCP модуля клиента. Возможно, сегмент прибудет в клиентскую часть TCP. Отличие здесь в том, что два TCP модуля осуществляют тайм-аут и повторную передачу, а не NFS клиент и сервер. (Когда используется UDP, NFS клиент осуществляет тайм-аут и повторную передачу.) Тем не менее, NFS клиент никогда не знает, что отклик был потерян и должен быть повторно передан. NFS сервера может получить другой номер порта после перезагрузки. Это может запутать клиента, потому что он должен знать, что сервер вышел из строя, установить контакт с преобразователем портов сервера после перезагрузки, чтобы найти новый номер порта NFS сервера.Подобное, когда сервер выходит из строя и перезагружается, а приложение RPC сервера получает новый динамически назначаемый порт, может возникнуть с любым RPC приложением, которое не использует заранее известный порт.
Нет. NFS клиент может повторно использовать тот же самый локальный зарезервированный номер порта для различных серверов. TCP требует, чтобы локальный IP адрес, локальный порт, удаленный IP адрес и удаленный порт были уникальными, а удаленный IP адрес отличаться от каждого хоста сервера.
Глава 30 Напечатайте whois "net 88". Идентификаторы сети класса А 64-95 зарезервированы. Напечатайте whois whitehouse-dom. И команда host, и nslookup могут запросить DNS. Нет, xscope можно запустить на другом хосте (не на сервере). Если хосты разные, xscope может использовать TCP порт 6000 для входящих соединений.
Назад
Компания | Услуги | Для клиентов | Библиотека | Галерея | Cофт | Линки
На главную
Е.1 Интерпретация переменной ядра subnetsarelocal.
Рисунок Е.1 Интерпретация переменной ядра subnetsarelocal.
Это влияет на MSS, который выбирается TCP. Когда происходит отправка на локальный пункт назначения, TCP выбирает MSS, основываясь на MTU исходящего интерфейса. Когда происходит отправка на нелокальный пункт назначения, TCP использует значение переменной tcp_mssdflt как MSS.
IPSENDREDIRECTS
Значение этой константы инициализирует переменную ядра ipsendredirects. Если равно 1 (по умолчанию), хост будет отправлять ICMP перенаправления при перенаправлении IP датаграмм. Если установлено в 0, ICMP перенаправления не отправляются.DIRECTED_BROADCAST
Если равно 1 (по умолчанию), полученные датаграммы, адреса назначения которых это широковещательные адреса подключенных интерфейсов, перенаправляются как широковещательные запросы канального уровня. Если равно 0, эти датаграммы молча отбрасываются.
Следующие переменные также могут быть модифицированы. Эти переменные рассеяны в различных файлах в директории /usr/src/sys/netinet.
tcprexmtthresh
Количество последовательно принятых подтверждений, которое включает алгоритм быстрой повторной передачи и быстрого восстановления. По умолчанию равно 3.tcp_ttl
Это значение устанавливается по умолчанию в поле TTL в TCP сегментах. Значение по умолчанию 60.tcp_mssdflt
Значение MSS TCP по умолчанию для нелокальных пунктов назначения. Значение по умолчанию 512.tcp_keepidle
Количество 500-миллисекундных тиков часов перед отправкой пробы "оставайся в живых". Значение по умолчанию 14400 (2 часа).tcp_keepintvl
Количество 500-миллисекундных тиков часов между последовательными пробами "оставайся в живых", когда не получен ответ. Значение по умолчанию 150 (75 секунд).tcp_sendspace
Размер по умолчанию отправляющего буфера TCP. Значение по умолчанию 4096.tcp_recvspace
Размер по умолчанию приемного буфера TCP. Он оказывает влияние на предлагаемый размер окна. Значение по умолчанию 4096.udpcksum
Если не равно 0, рассчитывается контрольная сумма UDP для исходящих UDP датаграмм, и если входящие UDP датаграммы содержат ненулевую контрольную сумму, эти контрольные суммы проверяются. Если равно 0, исходящие UDP датаграммы не содержат контрольную сумму, и не осуществляется проверка контрольных сумм для входящих UDP датаграмм, даже если отправитель рассчитал контрольную сумму. По умолчанию равно 1.udp_ttl
Значение по умолчанию для поля TTL в UDP датаграммах. По умолчанию равно 30.udp_sendspace
Размер по умолчанию для отправляющего буфера UDP. Определяет максимальный размер UDP датаграммы, которая может быть отправлена. По умолчанию 9216.udp_recvspace
Размер по умолчанию приемного буфера UDP. По умолчанию равно 41600, что означает 40 датаграмм размером 1024 байта.
С.1 Функционирование программы
Рисунок С.1 Функционирование программы sock как интерактивного клиента.

Мы должны указать имя хоста сервера и имя сервиса, к которому необходимо подсоединиться. Хост может быть указан в виде IP адреса, а сервис может быть указан в виде целого номера порта. Подсоединение к стандартному эхо серверу (глава 1, раздел "Стандартные простые сервисы"), от sun к bsdi, отражает эхом все, что введено:
sun % sock bsdi echo a test line вводим строку a test line эхо сервер вернул копию ^D вводим символ конца файла, чтобы прекратить работу программы Интерактивный сервер: указана опция -s. Необходимо указать имя сервиса (или номер порта):
sun % sock s 5555 работает как сервер, слушает порт 5555
Программа ожидает соединения от клиента и затем копирует стандартный ввод клиенту и копирует все, что получено от клиента, на стандартный вывод. В командной строке перед номером порта может стоять Internet адрес, чтобы указать, с какого локального интерфейса будет принято соединение:
sun % sock -s 140.252.13.33 5555 принимает соединения только по Ethernet
По умолчанию запрос на соединение принимается с любого локального интерфейса.
Клиент источник: указана опция -i. По умолчанию, буфер размером 1024 байта записывается в сеть 1024 раза. С помощью опций -n и -w можно изменить эти значения. Например, командаsun % sock -i -n12 -w4096 bsdi discard
запишет 12 буферов, каждый из которых по 4096 байт, на discard сервис хоста bsdi.
Сервер приемник: указаны опции -i и -s. Данные читаются из сети и отбрасываются.
Несмотря на то, что в этих примерах использовался TCP (по умолчанию), с помощью опции -u можно использовать UDP.
Существует большое количество опций, что позволяет полностью контролировать функционирование программы. С помощью этих опций можно реализовать практически все, что было показано в тексте.
-b n
Воспринимает n как номер локального порта клиента. (По умолчанию используется динамический номер порта, назначенный системой клиента.)-c
Конвертирует символы новой строки, которые прочитаны из стандартного ввода, в символы возврата каретки и пропуска строки. Когда осуществляется чтение из сети, конвертирует последовательность <возврат каретки, пропуск строки> в единственный символ новой строки. Большинство Internet приложений работают с NVT ASCII (глава 26, раздел "Протокол Telnet"), где возврат каретки и пропуск строки используются для завершения каждой строки.-f a.b.c.d.p
Указывает удаленный IP адрес (a.b.c.d) и удаленный номер порта (p) для конечной точки UDP (глава 11, раздел "Сервер UDP").-h
Переводит TCP соединение в наполовину закрытое состояние (глава 18, раздел "Наполовину закрытый TCP"). То есть, соединение не разрывается при появлении в стандартном вводе символа конца файла. Вместо этого, соединение наполовину закрывается, при этом чтение из сети продолжается до тех пор, пока сам хост не закроет соединение.-i
Клиент источник или сервер приемник. Либо пишет данные в сеть (по умолчанию), либо, если используется с опцией -s, читает данные из сети. Опция -n указывает количество буферов, которые необходимо записать (или считать), опция -w указывает размер каждой записи, а опция -r указывает размер каждого чтения.-n n
Когда используется с опцией -i, n указывает количество буферов, которые необходимо считать или записать. По умолчанию n равно 1024.-p n
Указывает количество секунд, в течение которых необходимо выдержать паузу, перед каждым чтением или записью. Это может быть использовано в случае клиента источника (-i) или сервера приемника (-is), чтобы вставить задержку между каждым чтением или записью в сеть. Также существует опция -P, которая позволяет вставить паузу перед первым чтением или записью.-q n
Указывает размер очереди ожидания соединения для TCP сервера: разрешенное количество соединений, которое TCP может поставить в очередь для приложения (рисунок 18.23). По умолчанию равно 5.-r n
Когда используется с опциями -is, n определяет размер каждого чтения из сети. По умолчанию 1024 байта за одно чтение.-s
Функционирует как сервер, а не как клиент.-u
Использует UDP вместо TCP.-v
Отладочный режим. Печатает дополнительные подробности (как, например, динамически назначаемые номера портов клиента и сервера) в стандартный вывод ошибок.-w n
Когда используется с опцией -i, определяет размер каждой записи в сеть. По умолчанию 1024 байта за запись.-A
Включает опцию сокета SO_REUSEADDR. В случае TCP это позволяет процессу назначить самому себе номер порта, который является частью соединения, находящегося в состоянии ожидания 2MSL. В случае UDP, если система поддерживает групповую адресацию, это позволяет нескольким процессам использовать один и тот же локальный порт для получения широковещательных или групповых датаграмм.-B
Включает опцию сокета SO_BROADCAST, что позволяет UDP датаграммам быть отправленным на широковещательный IP адрес.-D
Включает опцию сокета SO_DEBUG. При этом выводится дополнительная отладочная информация, которую содержит ядро для этого TCP соединения (приложение A, раздел "Опция отладки сокета"). Эта информация может быть получена позже, с помощью запуска программы trpt(8).-E
Включает опцию сокета IP_RECVDSTADDR, если она поддерживается реализацией (глава 11, раздел "Сервер UDP"). Это предназначено для UDP серверов, чтобы печатать IP адреса назначения полученных UDP датаграмм.-F
Будет использоваться конкурентный TCP сервер. В этом случае сервер создает новый процесс с использованием программы fork для каждого соединения клиента.-K
Включает опцию TCP сокета SO_KEEPALIVE (глава 23).-L n
Устанавливает время задержки (опция сокета SO_LINGER) для конечной точки TCP в значение n. Время задержки равное 0 означает, что когда соединение закрывается, любые данные, оставшиеся в очереди для отправки, отбрасываются, а удаленному хосту посылается сброс (глава 18, раздел "Сегменты сброса (Reset)"). Положительное время задержки - это время (в сотых долях секунды), в течение которого соединение не закрывается, пока все данные не будут отправлены и подтверждены. Если, после закрытия сетевого соединения, не все данные были отправлены и подтверждены в момент истечения этого таймера, закрытие вернет ошибочный код возврата.-N
Устанавливает опцию сокета TCP_NODELAY, чтобы выключить алгоритм Нагла (глава 19, раздел "Алгоритм Нагла").-O n
Сообщает TCP серверу количество секунд, в течение которых тот должен выдержать паузу, перед приемом первого соединения от клиента.-P n
Указывает количество секунд, в течение которых необходимо выдержать паузу, перед тем как будет осуществлено первое чтение или запись в сеть. Это может быть использовано с сервером приемником (-is), чтобы осуществить задержку после приема запроса на соединение от клиента, однако перед тем, как осуществить первое чтение из сети. При использовании с клиентом источником или сервером приемником (-i), эта величина определяет промежуток времени между установлением соединения и перед первой записью в сеть. Опция -p определяет паузу между каждыми соседними чтениями или записями.-Q n
Указывает количество секунд для TCP клиента или сервера, в течение которых необходимо выдержать паузу, после получения символа конца файла с удаленного конца, перед тем как закрыть соединение со своей стороны.-R n
Устанавливает приемный буфер сокета (опция сокета SO_RCVBUF) в значение n. Это может непосредственно повлиять на размер приемного окна, объявляемого TCP. В случае UDP определяет максимальный размер UDP датаграммы, которая может быть принята.-S n
Устанавливает отправляющий буфер сокета (опция сокета SO_SNDBUF) в значение n. В случае UDP определяет максимальный размер UDP датаграммы, которая может быть отправлена.-U n
Переводит TCP в режим срочности после осуществления записи номер n в сеть. Для входа в режим срочности записывается один байт данных (глава 20, раздел "Режим срочности (Urgent Mode)").Назад
Компания | Услуги | Для клиентов | Библиотека | Галерея | Cофт | Линки
На главную
В.1 Распределение времени
Рисунок В.1 Распределение времени, необходимое для вызова gettimeofday 10000 раз в SPARC ELC.
Полное время, необходимое для запуска программы, составило 0,38 секунды, при практически свободной системе. Отсюда можно сделать вывод, что процессу потребовалось для вызова gettimeofday примерно 37 микросекунд. Так как ELC имеет скорость примерно 21 MIPS (миллион инструкций в секунду), 37 микросекунд соответствуют примерно 800 инструкциям. Ядро принимает системный вызов от пользовательского процесса, исполняет системный вызов, копирует назад 8 байт в качестве результата и возвращает управление пользовательскому процессу. (Скорость MIPS достаточно спорная величина, поэтому на современных системах сложно оценить время исполнения инструкций. Все что мы попробуем сделать, это получить примерное представление и увидеть, могут ли полученные значения иметь какой-то определенный смысл.)
Из этого простого эксперимента мы можем сказать, что значения, возвращенные gettimeofday, содержат микросекундную точность.
Если мы запустим подобный тест в SVR4/386, результаты будут отличны от приведенных выше. Это объясняется тем, что большинство 386 Unix систем, таких как SVR4, имеют только 10-миллисекундные прерывания часов и даже не стараются предоставить более высокое разрешение часов. На рисунке В.2 показано распределение 9999 отрезков времени для компьютера 25Мгц 80386, работающего под управлением операционной системы SVR4.
| Микросекунды | Счетчик |
| 0 | 9871 |
| 10000 | 128 |
В.2 Время, необходимое
Рисунок В.2 Время, необходимое для вызова gettimeofday 10000 раз в случае SVR4/386.
Эти значения менее точны, разница во времени обычно меньше чем 10 миллисекунд, что воспринимается как 0. Практически все, что мы можем сделать на подобных системах, это рассчитать время часов на свободной машине и поделить его на количество циклов. При этом мы получим верхний предел, так как сюда входит время, необходимое, чтобы 9999 раз вызвать printf и записать результаты в файл. (В случае SPARC, рисунок В.1, промежутки времени не включают в себя время, необходимое для работы функции printf, так как все 10000 значений были сначала получены, а затем был напечатан результат.) Под управлением SVR4 время часов составило 3,15 секунды, что дает примерно 315 микросекунд на один системный вызов. Время системного вызова в 8,5 раз медленнее, чем в SPARC, что выглядит похожим на правду.
BSD/386 Version 1.0 предоставляет микросекундную точность, такую же как SPARC. Она читает регистр часов 8253 и рассчитывает количество микросекунд, прошедшее с последнего тика часов. Это разрешение доступно для процессов вызывающих gettimeofday и для модулей ядра, таких как пакетный фильтр BSD.
В случае tcpdump эти цифры означают, что мы можем доверять миллисекундным значениям и значениям, равным частям миллисекунд, которые напечатаны в системах SPARC и BSD/386, однако значения, напечатанные tcpdump под управлением SVR4/386, всегда будут кратны 10 миллисекундам. Для других программ, которые печатают время возврата, таких как ping (глава 7) и traceroute (глава 8), в случае SPARC и BSD/386 систем мы можем верить миллисекундным значениям вывода, однако значения, напечатанные под управлением SVR4/386, будут всегда кратны 10. Чтобы оценить время возврата ping в локальной сети, что мы показывали в главе 7, равное примерно 3 миллисекундам, требуется запустить ping на SPARC или BSD/386.
В некоторых примерах запущенных под BSD/386 Version 0.9.4 получена 10-миллисекундная точность часов (как под SVR4). Когда мы показывали вывод команды tcpdump с этих систем, то приводили только две цифры справа от десятичной точки, в соответствии с предоставляемой точностью часов.
Назад
Компания | Услуги | Для клиентов | Библиотека | Галерея | Cофт | Линки
На главную
Сервер BOOTP (глава 16)
Сервер BOOTP (глава 16)
Различные версии широкоиспользуемого BOOTP сервера для Unix находятся на хосте ftp.lancaster.andrew.cmu.edu в директории pub.
Сервер имен BIND (глава 14)
Сервер имен BIND (глава 14)
Сервер имен BIND, демон named , доступен с хоста ftp.uu.net в файле networking/ip/dns/bind/bind.4.8.3.tar.Z. Более новая версия, 4.9, доступна с хоста ftp.gatekeeper.dec.com в директории pub/BSD/bind/4.9.
SLIP (глава 2, раздел "SLIP
SLIP (глава 2, раздел "SLIP: IP по последовательной линии")
Версия SLIP, используемая в тексте, находится на ftp.ee.lbl.gov. Имя файла начинается с cslip, так как он поддерживает сжатый SLIP (глава 2, раздел "SLIP с компрессией (CSLIP)").
Соглашения о безопасности
Соглашения о безопасности
Необходимо обратить внимание на то, что просмотр сетевого траффика позволяет нам увидеть многие вещи, которые мы видеть вообще-то не должны. Например, пароли, печатаемые пользователями для приложений, таких как Telnet или FTP, передаются по сети именно так, как их ввел пользователь. (Это называется представлением пароля в виде открытого текста (cleartext), в отличие от зашифрованного представления (encrypted). Именно в зашифрованном виде пароли хранятся в файле паролей Unix, обычно /etc/passwd или /etc/shadow.) Тем не менее, существует множество моментов, когда администратору сети необходимо использовать средство, подобное tcpdump, чтобы диагностировать проблемы в сети.
Мы используем tcpdump как обучающее средство, чтобы посмотреть, что в действительности передается по сети. Доступ к tcpdump и подобным ей утилитам зависит от системы (и может быть от воли системного администратора). В случае SunOS, например, доступ к NIT устройству разрешен только суперпользователю. Пакетный фильтр BSD использует другую технику: доступ контролируется доступом к устройству /dev/bpfXX. Обычно эти устройства может читать и писать только владелец (который должен быть суперпользователем), а также они доступны для чтения членам группы (группа системного администратора). Это означает, что обычный пользователь не может запускать программы, подобные tcpdump, без санкции на то системного администратора (например, с помощью setUID).
Solaris 2.2
Solaris 2.2
Solaris 2.2 это типичная Unix система нового поколения. Она предоставляет программу, которая позволяет администратору изменить опции конфигурации для системы TCP/IP. Это позволяет осуществлять переконфигурацию без модификации файлов с исходными текстами и перестройки ядра. Конфигурационная программа называется ndd(1) . Мы можем запустить программу, чтобы посмотреть, какие параметры могут быть просмотрены или модифицированы в UDP модуле:
solaris % ndd /dev/udp \? udp_wroff_extra (read and write-чтение и запись) udp_def_ttl (read and write-чтение и запись) udp_first_anon_port (read and write-чтение и запись) udp_trust_optlen (read and write-чтение и запись) udp_do_checksum (read and write-чтение и запись) udp_status (read only-только чтение)
Мы можем указать пять модулей: /dev/ip, /dev/icmp, /dev/arp, /dev/udp и /dev/tcp. Знак вопроса в качестве аргумента (перед которым необходимо поставить обратный слэш, чтобы предотвратить интерпретацию вопросительного знака интерпретатором команд) сообщает программе о необходимости показать список всех параметров для этого модуля. В качестве примера, который запрашивает значение переменной, можно привести следующее:
solaris % ndd /dev/tcp tcp_mss_def
536
Чтобы изменить значение переменной, необходимо с привилегиями суперпользователя ввести следующее:
solaris # ndd -set /dev/ip ip_forwarding 0
Эти переменные могут быть поделены на три категории: Переменные конфигурации, которые могут быть изменены системным администратором (например, ip_forwarding). Переменные статуса, которые могут быть только просмотрены (например, ARP кэш). Обычно, эта информация предоставляется в формате, пригодном для чтения, командами ifconfig, netstat и arp. Отладочные переменные, предназначенные для исходного кода ядра. Включение некоторых из них генерирует отладочный вывод ядра, что может значительно снизить производительность.
Сейчас мы опишем эти параметры для каждого модуля. Все параметры могут быть считаны и записаны, если они не помечены "только для чтения" (Read only). Эти параметры только для чтения являются переменными статуса (см. выше, пункт 2). Переменные, упомянутые в пункте 3, помечены как "отладочные" (Debug). Все временные характеристики приведены в миллисекундах, что отличается от других систем, которые обычно указывают время в некотором количестве 500-миллисекундных тиков часов.
Sun NFS (глава 29)
Sun NFS (глава 29)
Свободно распространяемые реализации NFS клиента и сервера являются частью BSD Net/2 Source Code, который описан раньше в этом приложении.
Sun RPC (глава 29, раздел "Вызов
Sun RPC (глава 29, раздел "Вызов удаленной процедуры Sun")
Версия исходных текстов RPC 4.0 (которая использует сокеты API) находится на хосте ftp.uu.net в директории systems/sun/sextape/rpc4.0. Версию исходных текстов TI-RPC (которая использует TLI API) можно получить с хоста ftp.uu.net в директории networking/rpc.
SunOS 4.1.3
SunOS 4.1.3
Метод, используемый с SunOS 4.1.3, напоминает тот, что мы видели в случае BSD/386. Так как большинство кодов ядра не распространяются, все установки С переменных содержатся в одном файле С кода, который поставляется в системе. Из файла конфигурации ядра администратора (см. страницы помощи config(8)) можно определить следующие переменные. После модификации конфигурационного файла должно быть создано новое ядро, и система должна быть перезагружена.
IPFORWARDING
Значение этой константы инициализирует переменную ядра ip_forwarding. Если равно -1, IP датаграммы никогда не перенаправляются. Более того, переменная не может быть изменена. Если равно 0 (по умолчанию), IP датаграммы не перенаправляются, однако значение переменной изменяется в 1, если "поднято" несколько интерфейсов. Если равно 1, перенаправление всегда включено.SUBNETSARELOCAL
Эта константа инициализирует переменную ядра ip_subnetsarelocal. Если равно 1 (по умолчанию), IP адрес назначения с тем же самым идентификатором сети, как и у отправляющего хоста, однако с другим идентификатором подсети, считается локальным. Если равно 0, только IP адреса назначения, подключенные непосредственно к этой подсети, считаются локальными. Подобный подход кратко описан на рисунке Е.1. Когда осуществляется отправка на локальные пункты назначения, TCP выбирает MSS на основе MTU исходящего интерфейса. Когда происходит отправка на нелокальный пункт назначения, TCP использует для этой цели переменную tcp_default_mss.IPSENDREDIRECTS
Значение этой константы инициализирует переменную ядра ip_sendredirects. Если равно 1 (по умолчанию), хост будет отправлять ICMP перенаправления при перенаправлении IP датаграмм. Если равно 0, ICMP перенаправления не отправляются.DIRECTED_BROADCAST
Значение этой константы инициализирует переменную ядра ip_dirbroadcast . Если равно 1 (по умолчанию), принятые датаграммы, адрес назначения которых это широковещательный адрес непосредственно подключенного интерфейса, перенаправляются как широковещательные запросы канального уровня. Если равно 0, эти датаграммы молча отбрасываются.
Файл /usr/kvm/sys/netinet/in_proto.c определяет следующие переменные, которые могут быть изменены. Если переменные изменены, должно быть собрано новое ядро и система перезагружена.
tcp_default_mss
Значение по умолчанию MSS TCP для нелокальных пунктов назначения. Значение по умолчанию 512.tcp_sendspace
Размер по умолчанию отправляющего буфера TCP. Значение по умолчанию 4096.tcp_recvspace
Размер по умолчанию приемного буфера TCP. Оказывает влияние на предлагаемый размер окна. Значение по умолчанию 4096.tcp_keeplen
Проба "оставайся в живых" на хост 4.2BSD должна содержать один байт данных, для того чтобы получить отклик. Установка переменной в 1 осуществляет совместимость с этими более старыми реализациями. Значение по умолчанию 1.tcp_ttl
Значение по умолчанию для поля TTL TCP сегментов. По умолчанию 60.tcp_nodelack
Если не равно 0, подтверждения не задерживаются. Значение по умолчанию 0.tcp_keepidle
Количество 500-миллисекундных тиков часов перед отправкой пробы "оставайся в живых". Значение по умолчанию 14400 (2 часа).tcp_keepintvl
Количество 500-миллисекундных тиков часов между последовательными пробами "оставайся в живых", если не получен отклик. Значение по умолчанию 150 (75 секунд).udp_cksum
Если не равно 0, UDP контрольные суммы рассчитываются для исходящих UDP датаграмм, а для входящих UDP датаграмм, содержащих ненулевую контрольную сумму, контрольная сумма проверяется. Если равно 0, исходящие UDP датаграммы не содержат контрольную сумму, и не осуществляется проверка контрольной суммы для входящих UDP датаграмм, даже если отправитель рассчитал контрольную сумму. По умолчанию 0.udp_ttl
Значение по умолчанию для поля TTL в UDP датаграммах. По умолчанию 60.udp_sendspace
Размер по умолчанию для отправляющего буфера UDP. Определяет максимальный размер UDP датаграммы, которая может быть отправлена. По умолчанию 9000.udp_recvspace
Размер по умолчанию приемного буфера UDP. Значение по умолчанию 18000, что означает две датаграммы размером 9000 байт.
System V Release 4
System V Release 4
Конфигурация TCP/IP в SVR4 напоминают две предыдущие системы, однако доступно значительно меньше опций. В файле /etc/conf/pack.d/ip/space.c определены две константы, которые могут быть изменены, после чего ядро должно быть перестроено, а система перезагружена.
IPFORWARDING
Значение этой константы инициализирует переменную ядра ipforwarding . Если равно 0 (по умолчанию), IP датаграммы не перенаправляются. Если равно 1, перенаправление всегда включено.IPSENDREDIRECTS
Значение этой константы инициализирует переменную ядра ipsendredirects. Если равно 1 (по умолчанию), хост будет отправлять ICMP перенаправления при перенаправлении IP датаграмм. Если равно 0, ICMP перенаправления не отправляются.
Большинство из переменных, которые мы описали в двух предыдущих разделах, определены в ядре, однако необходимо иметь patch (patch (англ.) - заплата; исправления, поставляемые производителями к программному обеспечению), чтобы модифицировать их. В качестве примера можно привести переменную tcp_keepidle со значением 14400.
Высокоскоростные расширения TCP (глава 24)
Высокоскоростные расширения TCP (глава 24)
Общедоступные исходные тексты реализаций TCP опции масштабирования окна, опции временной марки и алгоритма PAWS доступны как patch набор для релиза BSD Net/2 с хоста ftp.uxc.cso.uiuc.edu в файле pub/tcplw.shar.Z.
Вывод tcpdump
Вывод tcpdump
Вывод команды tcpdump - "символьный" (raw). Мы будем модифицировать и дополнять его, чтобы сделать вывод более читаемым.
Во-первых, tcpdump всегда вводит имя сетевого интерфейса, который "слушает". Мы удалим эту строку.
Затем вывод времени, осуществляемый tcpdump, осуществляется в формате 09:11:22.642008 для систем с точностью до микросекунд, или в формате 09:11:22.64 для систем с точностью часов до 10 миллисекунд. (В приложении В мы расскажем более подробно о точности компьютерных часов.) В любом случае формат HH:MM:SS это не то, что мы хотим. В данном случае хочется видеть относительное время для каждого пакета с момента начала мониторинга сети (dump), а также разницу во времени между последовательно приходящими пакетами. Мы модифицировали вывод, чтобы показать эти временные показатели. Первый показатель мы показываем в виде шести цифр справа от десятичной точки, когда можно получить точность разрешения времени в микросекундах (в случае 10-миллисекундной точности показано две цифры), а второй показатель мы показываем в виде четырех или двух цифр справа от десятичной точки (в зависимости от точности часов).
В этом тексте большинство вывода команды tcpdump было получено на хосте sun, который имеет точность часов до одной микросекунды. Некоторый вывод был получен на хосте bsdi, на котором работает операционная система BSD/386 Version 0.9.4, и который предоставляет 10-миллисекундную точность часов (рисунок 5.1). Некоторый вывод был также получен на хосте bsdi, который работает под управлением операционной системы BSD/386 Version 1.0, которая предоставляет микросекундную точность.
tcpdump всегда печатает имя отправляющего хоста, затем знак "больше", затем имя хоста назначения. Из-за этого довольно сложно отслеживать поток пакетов между двумя хостами. Так как в нашем случае вывод tcpdump часто выглядит подобным образом, мы строим на его основе временную диаграмму. (Впервые это было сделано в тексте на рисунке 6.11.) В наших временных диаграммах один хост находится слева, а другой справа. При этом значительно легче увидеть, какая сторона посылает, а какая получает каждый пакет.
Мы добавляем номера строк в вывод команды tcpdump, что позволяет делать сноски на конкретные строки в тексте. Мы также добавляем дополнительные пробелы между строками, чтобы отделить один пакет от другого.
И в завершение, вывод tcpdump может не помещаться в страницу. Мы обрезаем длинные строки, для того чтобы их удобней было читать.
В качестве примера можно показать вывод, осуществленный командой tcpdump, соответствующий рисунку 4.4, который показан на рисунке А.3, при этом мы считаем, что используется окно терминала с 80 колонками.
Мы не показываем ввод символа прерывания (который прекращает работу tcpdump) и не показываем количество пакетов, полученных, но отброшенных. (Отброшенные пакеты это те, которые прибывают быстрее, чем их может обработать tcpdump. Так как примеры в тексте обычно запускаются в довольно свободных сетях, эта величина всегда равна 0.)
sun % tcpdump -e tcpdump: listening on le0 09:11:22.642008 0:0:c0:6f:2d:40 ff:ff:ff:ff:ff:ff arp 60: arp who-has svr4 tell bsdi 09:11:22.644182 0:0:c0:c2:9b:26 0:0:c0:6f:2d:40 arp 60: arp reply svr4 is-at 0:0:c0:c2:9b:26 09:11:22.644839 0:0:c0:6f:2d:40 0:0:c0:c2:9b:26 ip 60: bsdi.1030 > svr4.discard: S 596459521:596459521 (0) win 4096 <mss 1024> [tos 0x10] 09:11:22.649842 0:0:c0:c2:9b:26 0:0:c0:6f:2d:40 ip 60: svr4.discard > bsdi.1030: S 3562228225:3562228225 (0) ack 596459522 win 4096 <mss 1024> 09:11:22.651623 0:0:c0:6f:2d:40 0:0:c0:c2:9b:26 ip 60: bsdi.1030 > svr4.discard: . ack 1 win 4096 [tos 0x10] ^? 9 packets received by filter 0 packets dropped by kernel
