Адаптеры Ethernet и Fast Ethernet
9.1. Адаптеры Ethernet и Fast Ethernet
Так как сеть Ethernet/Fast Ethernet в настоящее время распространена наиболее широко, ее аппаратура выпускается наибольшим числом производителей и ее перспективы представляются самыми благоприятными, остановимся подробнее на некоторых особенностях ее аппаратных средств. Впрочем, многое из сказанного в этом разделе относится не только к Ethernet, но и к аппаратуре других, менее популярных сетей.
<
Адаптеры с внешними трансиверами
9.1.2. Адаптеры с внешними трансиверами
Адаптеры Fast Ethernet могут выпускаться с внешним, выносным модулем трансивера для подключения к среде передачи (PHY). В этом случае для присоединения внешнего модуля трансивера к адаптеру используется интерфейс МП (Media-Independent Interface), предусматривающий использование 40-контактного разъема, подобного разъему компьютерного интерфейса SCSI. Сменный модуль трансивера может устанавливаться непосредственно на плате адаптера (в специальный вырез платы), а может связываться с платой адаптера внешним кабелем длиной до 0,5 м (Рисунок 9.1 и 9.2). При вычислении полного времени задержки в сети необходимо учитывать и задержку в этом трансиверном кабеле.
На плате трансивера располагается микросхема приемопередатчика и разъем, зависящий от типа среды (MDI - Medium Dependent Interface), например, RJ-45 для витой пары. Таким образом, один и тот же адаптер может поддерживать обмен с любым типом среды за счет простой замены сравнительно дешевого трансивера. Понятно, что в целом подобные составные адаптеры оказываются дороже обычных адаптеров со встроенными приемопередатчиками, но иногда их применение оправдано, если предполагается постепенная замена среды передачи, например, на оптоволоконные кабели.
Формат сетевого адреса IPX
Рисунок 9.13. Формат сетевого адреса IPX

Каждый абонент (узел), прежде чем послать пакет, определяет, может ли он послать его непосредственно получателю или же ему надо воспользоваться услугами маршрутизатора. Если номер собственной сети передающего абонента совпадает с номером сети абонента, которому должен передаваться пакет, то пакет передается непосредственно, без маршрутизации. Если же адресат находится в другой сети, то передаваемая дейтаграмма должна быть отправлена маршрутизатору, который затем переправит ее в нужную сеть. При этом получается, что пакет в целом адресован маршрутизатору (как одному из абонентов собственной сети), а заключенная в нем дейтаграмма адресована абоненту из другой сети, которому она, собственно, и предназначена. В поле сетевого адреса передатчика абонент в любом случае помещает номер своей собственной сети (4 байта) и свой МАС-адрес (6 байт).
<
Функции маршрутизаторов
9.4.2. Функции маршрутизаторов
Вытесняя мосты, коммутаторы сильно потеснили и маршрутизаторы. Но маршрутизаторы работают на более высоком, третьем уровне модели OSI (мосты и коммутаторы — на втором), они имеют дело с протоколами более высоких уровней. Поэтому им, скорее всего, не грозит полное исчезновение.
Маршрутизаторы, как и мосты и коммутаторы, ретранслируют пакеты из одной части сети в другую (из одного сегмента в другой). Изначально маршрутизатор от моста отличался только тем, что на компьютере, соединяющем две или более части сети, было установлено другое программное обеспечение. Но между маршрутизатором и мостом существуют и принципиальные отличия.
Маршрутизаторы работают не с физическими адресами пакетов (МАС-адресами), а с логическими сетевыми адресами (IP-адресами).
Маршрутизаторы ретранслируют не всю приходящую информацию, а только ту информацию, которая адресована им лично, и отбрасывают широковещательные пакеты, разделяя тем самым широковещательную область сети. (Все абоненты должны знать о существовании в сети маршрутизатора.)
Самое главное — маршрутизаторы поддерживают сети с множеством возможных маршрутов, путей передачи информации, так называемые ячеистые сети (meshed networks). Пример такой сети показан на Рисунок 9.10. Мосты же требуют, чтобы в сети не было петель, чтобы путь распространения информации между двумя любыми абонентами был единственным.
Маршрутизаторы сложнее мостов и коммутаторов и, следовательно, дороже (например, стоимость коммутации примерно в 10 раз ниже стоимости маршрутизации). Маршрутизаторами сложнее управлять, они почти всегда значительно медленнее коммутаторов. Зато они обеспечивают самое глубокое разделение сети на части. Если репитерные концентраторы всего лишь повторяют все поступившие на них пакеты (уровень 1 модели OSI), а коммутаторы и мосты ретранслируют только межсегментные и широковещательные пакеты (уровень 2 модели OSI), то маршрутизаторы соединяют практически самостоятельные, не влияющие друг от друга сети, сохраняя при этом возможность передачи информации между ними (уровень 3 модели OSI).
Размер сети с маршрутизаторами практически ничем не ограничен: ни допустимыми размерами зоны конфликтов, ни допустимым количеством широковещательных пакетов (которые могут просто не оставлять места для обычных, однопунктовых пакетов), ни возможными для коммутаторов и мостов разнообразными перегрузками. При этом легко обеспечиваются альтернативные, дублирующие пути распространения информации для увеличения надежности связи.
Функции мостов
9.4.1. Функции мостов
Мосты до недавнего времени были основными устройствами, применявшимися для разбиения сети на части (для сегментирования сети). Их стоимость меньше, чем маршрутизаторов, а быстродействие выше, к тому же они прозрачны для протоколов второго уровня модели OSI. Абоненты сети могут не знать о наличии в сети мостов, и все их пакеты доходят до нужного адресата по всей сети без всяких проблем.
Мост, как правило, представляет собой компьютер, в который установлено от двух до четырех сетевых адаптеров. Каждый из этих адаптеров соединен с одним из сегментов сети. Конфигурация сети с мостами может быть довольно сложной (Рисунок 9.8), но в ней не должно быть замкнутых маршрутов (петель), альтернативных путей доставки пакетов (Рисунок 9.9). В противном случае в результате многократного прохождения Широкове-
щательных пакетов по замкнутому маршруту возникают перегрузки сети (так называемые широковещательные штормы) и ряд других проблем. Чтобы этого не происходило, в мостах предусматривается алгоритм ос-товного дерева (spanning tree), который позволяет в результате диалога между всеми мостами отключать порты, участвующие в создании петель (например, оба порта моста 2 на Рисунок 9.9).
Функции репитеров и репитерных концентраторов
9.2.1. Функции репитеров и репитерных концентраторов
Репитеры (повторители), как уже отмечалось, ретранслируют приходящие на них (на их порты) сигналы, восстанавливают их амплитуду и форму, что позволяет увеличивать длину сети. То же самое делают и простейшие репитерные концентраторы. Но помимо этой основной функции концентраторы Ethernet и Fast Ethernet обычно выполняют еще ряд функций по обнаружению и исправлению некоторых простейших ошибок сети. К этим ошибкам относятся следующие:
ложная несущая (FCE - False Carrier Event);
множественные коллизии (ЕСЕ - Excessive Collision Error);
затянувшаяся передача (Jabber).
Все эти ошибки могут вызываться неисправностями оборудования абонентов, высоким уровнем шумов и помех в кабеле, плохими контактами в разъемах и т.д.
Под ложной несущей понимается ситуация, когда концентратор получает от одного из своих портов (от абонента или из сегмента) данные, не содержащие ограничителя начала потока данных (то есть признака начала кадра). Если после начала передачи кадр не начался в течение заданного временного интервала (5 мкс для Fast Ethernet, 50 мкс для Ethernet), то концентратор посылает сигнал «Пробка» всем остальным портам, чтобы они гарантированно обнаружили коллизию. Длительность этого сигнала также составляет 5 или 50 мкс. Затем выявленный порт переводится в состояние «Связь неустойчива» (Link Unstable) и отключается. Обратное включение порта концентратором может произойти только при поступлении от него правильного пакета, без ложной несущей.
Ситуация множественных коллизий фиксируется при выявлении в данном порту более 60 коллизий подряд. Концентратор считает количество коллизий в каждом порту и сбрасывает счетчик, если получает пакет без коллизии. Порт, в котором возникают множественные коллизии, отключается и подключается снова, если в течение заданного времени (5 мкс для Fast Ethernet, 50 мкс для Ethernet) не будет зафиксировано коллизий.
Ситуация затянувшейся передачи фиксируется в случае, когда передача продолжается в течение более 400 мкс для Fast Ethernet или 4000 мкс для Ethernet.
Это более чем в три раза превышает максимально возможную длительность пакета. При обнаружении такой затянувшейся передачи соответствующий порт отключается и включается снова только после ее окончания.
Кроме перечисленных функций концентратор также активно способствует обнаружению любых коллизий в сети. При одновременном поступлении на его порты двух и более пакетов он, как и любой абонент, усиливает столкновение путем передачи во все порты сигнала «Пробка» в течение 32 битовых интервалов. В результате все передающие абоненты всех сегментов обязательно обнаруживают факт коллизии и прекращают свою передачу.
Таким образом, даже самый простой репитерный концентратор представляет собой довольно сложное устройство, позволяющее автоматически устранять некоторые неисправности и временные сбои, то есть концентратор не только объединяет точки включения кабелей сети, но и активно улучшает условия обмена, повышает производительность сети, отключая время от времени неисправные или неустойчиво работающие сегменты.
Как и сетевые адаптеры, концентраторы и репитеры могут быть одно-скоростными и двухскоростными. Для большей свободы в проектировании сети лучше выбирать именно двухскоростные (10/100 Мбит/с) концентраторы и репитеры.
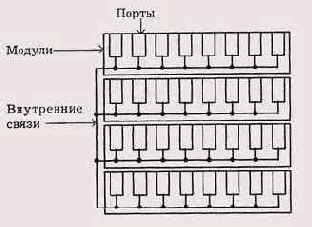
Чаще всего репитеры и концентраторы выполняются в виде отдельных автономных блоков, имеющих внутренний или внешний источник питания. Некоторые концентраторы рассчитаны на подключение жестко заданного количества сегментов определенного типа (например, на четыре сегмента 10BASE2 или же на восемь сегментов 10BASE-T). Другие, более дорогие концентраторы, называемые наращиваемыми (Stackable), имеют модульную структуру и позволяют гибко приспосабливать их к заданной конфигурации сети. В этом случае в каркас (стек) концентратора может быть установлено различное число (обычно до 8) сменных модулей, каждый из которых ориентирован на один или несколько сегментов какого-нибудь типа и имеет соответствующие разъемы для подключения кабеля сети (например, BNC, AUI, RJ-45, ST-разъемы).Как правило, количество подключаемых сегментов (портов концентратора) выбирается кратным четырем: 4, 8,12,16, 24, то есть наращиваемый концентратор может поддерживать, к примеру, 192 порта (восемь модулей, каждый из которых рассчитан на 24 сегмента). Структура такого наращиваемого концентратора показана на Рисунок 9.3.
Оборудование Ethernet и Fast Ethernet
Глава 9. Оборудование Ethernet и Fast Ethernet
Характеристики адаптеров
9.1.1. Характеристики адаптеров
Сетевые адаптеры (NIC, Network Interface Card) Ethernet и Fast Ethernet могут сопрягаться с компьютером через один из следующих стандартных интерфейсов:
шина ISA (Industry Standard Architecture);
шина PCI (Peripheral Component Interconnect);
шина EISA (Enhanced ISA);
шина MCA (Micro Channel Architecture);
шина VLB (VESA Local Bus);
шина PC Card (она же PCMCIA);
параллельный порт Centronics (LPT);
последовательный порт RS232-C (COM).
Наиболее часто встречаются адаптеры, рассчитанные на системную шину (магистраль) ISA, так как эта шина пока еще распространена больше других, ее слоты расширения имеет подавляющее большинство настольных компьютеров. Именно поэтому адаптеры данного типа самые дешевые. Адаптеры для ISA выпускаются 8- и 16-разрядными. 8-разрядные адаптеры дешевле, а 16-разрядные - быстрее. Правда, обмен информацией по шине ISA не может быть слишком быстрым (в пределе - 16 Мбайт/с, реально - не более 8 Мбайт/с). Поэтому адаптеры Fast Ethernet, требующие для эффективной работы больших скоростей обмена, для этой системной шины практически не выпускаются.
Шина PCI сейчас постепенно вытесняет шину ISA и становится основной шиной расширения для компьютеров. Она обеспечивает обмен 32- и 64-разрядными данными и отличается высокой пропускной способностью (теоретически до 264 Мбайт/с), что вполне удовлетворяет требованиям не только Fast Ethernet, но и более быстрой Gigabit Ethernet. Важно еще и то, что шина PCI применяется не только в компьютерах типа IBM PC, но и в компьютерах типа PowerMac, а также то, что она поддерживает режим автоматического конфигурирования оборудования Plug-and-Play. Видимо, в ближайшем будущем именно на шину PCI будет ориентировано большинство сетевых адаптеров. Недостаток PCI по сравнению с шиной ISA в том, что количество ее слотов расширения в компьютере невелико (обычно 3 слота).
Шины MCA, EISA и VLB некоторое время конкурировали с PCI (все они обеспечивают 32-разрядный обмен данными), но не выдержали конкуренции и быстро отмирают.
На вновь выпускаемых компьютерах они уже не предусматриваются. Поэтому исчезают и сетевые адаптеры, рассчитанные на эти шины. Отметим, что адаптеры ISA полностью совместимы с разъемами EISA. Но это единственный пример подобной взаимной совместимости перечисленных интерфейсов.
Шина PC Card (старое название PCMCIA) применяется пока только в портативных компьютерах класса Notebook. В этих компьютерах внутренняя шина PCI обычно не выводится наружу. Интерфейс PC Card предусматривает простое подключение к компьютеру миниатюрных плат расширения, причем скорость обмена с этими платами достаточна высока. Однако все больше портативных компьютеров оснащается встроенными сетевыми адаптерами, так как возможность доступа к сети становится неотъемлемой частью стандартного набора функций. Эти встроенные адаптеры опять же подключены к внутренней шине PCI.
При выборе сетевого адаптера, ориентированного на ту или иную шину, необходимо прежде всего убедиться, что свободные слоты расширения данной шины есть в компьютере, включаемом в сеть. Не мешает также оценить трудоемкость установки приобретаемого адаптера и перспективы выпуска плат данного типа. Последнее может понадобиться в случае выхода адаптера из строя.
Наконец, параллельный (принтерный) порт LPT и последовательный порт СОМ применяются для подключения сетевых адаптеров довольно редко. Главное достоинство такого подхода состоит в том, что для подключения адаптеров не нужно вскрывать корпус компьютера. Кроме того, в данном случае адаптеры не занимают системных ресурсов компьютера, таких как каналы прерываний и ПДП, а также адреса памяти и устройств ввода/ вывода. Однако скорость обмена информацией между ними и компьютером в обоих этих случаях значительно ниже, чем при использовании системной шины. К тому же они требуют больше процессорного времени на обмен с сетью, замедляя тем самым работу компьютера в целом. Важно и то, что адаптерам в этом случае требуется внешний источник питания, так как на разъемы LPT и СОМ питание компьютера не выведено.
Перечислим важнейшие характеристики сетевых адаптеров:
способ конфигурирования адаптера;
размер установленной на плате буферной памяти и режимы обмена с ней;
возможность установки на плату ПЗУ удаленной загрузки (BootROM).
возможность подключения адаптера к разным типам среды передачи (витая пара, тонкий и толстый коаксиальный кабель, оптоволоконный кабель);
используемая адаптером скорость передачи по сети и возможность ее переключения;
возможность использования адаптером полнодуплексного режима обмена;
совместимость адаптера (точнее, драйвера адаптера) с используемыми сетевыми программными средствами.
Конфигурирование адаптера подразумевает настройку на использование системных ресурсов компьютера (адресов ввода/вывода, каналов прерываний и прямого доступа к памяти, адресов буферной памяти и памяти удаленной загрузки). Конфигурирование может осуществляться путем установки в нужное положение переключателей (джамперов) или с помощью прилагаемой к адаптеру DOS-программы конфигурирования (Jumperless, Software configuration). При запуске такой программы
пользователю предлагается установить конфигурацию аппаратуры при помощи простого меню: выбрать параметры адаптера. Эта же программа позволяет произвести самотестирование адаптера. Выбранные параметры хранятся в энергонезависимой памяти адаптера. В любом случае при выборе параметров необходимо избегать конфликтов с системными устройствами компьютера и с другими платами расширения. Конфигурирование может выполняться и автоматически в режиме Plug-and-Play при включении питания компьютера. Адаптеры, поддерживающие этот режим, может легко установить любой неподготовленный пользователь.
В простейших адаптерах обмен с внутренней буферной памятью адаптера (Adapter RAM) осуществляется через адресное пространство устройств ввода/вывода. В этом случае никакого дополнительного конфигурирования адресов памяти не требуется. Базовый адрес буферной памяти, работающей в режиме разделяемой памяти, необходимо задавать. Он приписывается к области верхней памяти компьютера (UMA, Upper Memory Address) в диапазоне адресов AOOOOh-FFFFFh.
В эту же зону адресов помещается и ПЗУ удаленной загрузки (Boot ROM), если предполагается его использование для создания бездисковой рабочей станции. При выборе значений адресов надо следить, чтобы не было конфликтов с другими устройствами компьютера.
Все операции по конфигурированию сетевого адаптера необходимо проводить в строгом соответствии с документацией, поставляемой вместе с ним, так как каждый из многочисленных производителей адаптеров обычно вносит в них что-то свое, оригинальное. Поэтому никакие более подробные универсальные рекомендации попросту невозможны. Впрочем, это относится к любым электронным устройствам.
От размера буферной памяти адаптера зависит как скорость работы адаптера, так и его способность держать высокие информационные нагрузки. Размер памяти обычно составляет от 8 Кбайт до нескольких мегабайт. Чем больше память, тем больше сетевых пакетов может в ней храниться. Для адаптеров, работающих на выделенном сервере, большой объем буферной памяти просто необходим, ведь через него пойдут все информационные потоки сети. Впрочем, самая большая буферная память не поможет, эсли компьютер работает медленно, не успевает перекачивать приходящую по сети информацию.
Все функции по обслуживанию обмена по сети в сетевом адаптере, как правило, выполняет одна специализированная микросхема или неболь-лой комплект микросхем (2-3 штуки). Этим и объясняется достаточно низкая цена адаптеров. Поставщиков подобных комплектов микросхем к так много, поэтому очень многие адаптеры выполнены по сходным схемам. Однако организация обмена шины компьютера с адаптером может быть различной, поэтому показатели производительности адаптеров от разных изготовителей и показатели надежности их работы, особенно в экстремальных условиях, сильно различаются.
Адаптер может быть рассчитан только на один тип среды передачи, к примеру, на витую пару, но может поддерживать возможность подключения и нескольких разных сред передачи, например, тонкий и толстый коаксиальные кабели. Для этого на плате устанавливаются соответствующие разъемы.
Наиболее универсальны так называемые адаптеры «Combo», которые имеют полный набор разъемов (BNC, RJ-45 и AUI для Ethernet). Для выбора конкретного типа среды иногда используются переключатели (джамперы), как правило, их несколько и переключать их надо обязательно все вместе.
Адаптеры Fast Ethernet выпускаются как односкоростными (100 Мбит/ с), так и двухскоростными (10 Мбит/с и 100 Мбит/с). Двухскоростные платы (их обычно помечают «10/100») несколько дороже односкоростных, но зато они могут работать в любой сети Ethernet/Fast Ethernet без всяких проблем. Поэтому лучше в данном случае не экономить на мелочах.
Все сетевые адаптеры должны быть сертифицированы. Сертификат FCC класса А позволяет использовать адаптер в бизнесе, сертификат FCC класса В - в домашних условиях. Стандарт предусматривает безопасный уровень электромагнитного излучения сетевого адаптера.
При выборе адаптера очень важно обращать внимание на совместимость . его драйвера с сетевым программным обеспечением. Все поставщики сетевых программных средств (Novell, Microsoft и др.) проводят работу по сертификации драйверов. Если такой сертификат имеется, то можно быть уверенным, что проблем по совместимости не будет. С другой стороны, все сетевые программные продукты поставляются с набором протестированных драйверов, совместимых с ними. Если драйвер приобретенной платы входит в этот набор, то проблем тоже, скорее всего, не будет. Солидные производители сетевых адаптеров регулярно распространяют обновленные, более быстрые и универсальные версии драйверов для своих плат. Низкая цена некоторых адаптеров может объясняться как раз отсутствием сертификата, плохой совместимостью с программными средствами.
Ячеистая сеть с маршрутизаторами
Рисунок 9.10. Ячеистая сеть с маршрутизаторами

Именно маршрутизаторы чаще всего используются для связи локальных сетей с глобальными, в частности с сетью Internet, которая может рассматриваться как полностью маршрутизируемая сеть. Преобразовать протоколы локальных сетей в протоколы глобальных сетей для маршрутизатора вполне по силам.
Маршрутизаторы часто применяются для объединения опорной (стержневой) сетью типа FDDI множества локальных сетей (Рисунок 9.11) или для связи локальных сетей разных типов. Преобразование формата пакетов, требуемое в данной ситуации, для маршрутизатора не представляет никакой сложности. Например, большие пакеты сети FDDI могут разбиваться (фрагментироваться) на несколько меньших пакетов Ethernet.
Маршрутизаторы также легко преобразуют скорости передачи, связывая, например, между собой сети Ethernet, Fast Ethernet и Gigabit Ethernet. He пропуская широковещательных пакетов, они лучше справляются с этой задачей, чем мосты или коммутаторы, так как защищают медленные сегменты от перегрузок со стороны быстрых сегментов.
Маршрутизаторы иногда объединяют между собой. Множество соединенных друг с другом маршрутизаторов могут образовывать так называемое облако (cloud), представляющее собой, по сути, один гигантский маршрутизатор. Такое соединение обеспечивает исключительно гибкую и
надежную связь между всеми подключенными к нему локальными сетями (Рисунок 9.12).
Коммутаторы Cut-Through
9.3.1. Коммутаторы Cut-Through
Коммутаторы Cut-Through - самые простые и быстрые, они не производят никакого буферирования пакетов и никакой их селекции. Они буфе-рируют только головную часть пакета, чтобы прочитать 6-байтовый адрес приемника пакета и принять решение о коммутации, на которое у некоторых коммутаторов уходит около 10 битовых интервалов. В результате время ожидания ретрансляции (задержка на коммутаторе), включающее как время буферирования, так и время коммутации, может составлять около 150 битовых интервалов. Конечно, это больше задержки репитерного концентратора, но гораздо меньше задержки ретрансляции любого моста.
Недостаток данного типа коммутатора состоит в том, что он ретранслирует любые пакеты с нормальной головной частью, в том числе и заведомо ошибочные пакеты (например, с неправильной контрольной суммой) и карликовые пакеты (длиной менее 512 битовых интервалов). Ошибки одного сегмента ретранслируются в другой сегмент, что приводит к снижению пропускной способности сети в целом.
Еще одна проблема состоит в том, что коммутаторы данного типа часто перегружаются и плохо обрабатывают ситуацию перегрузки. Например, из двух или более сегментов поступают пакеты, адресованные одному и тому же сегменту. Но коммутатор не может одновременно передать несколько пакетов в один сегмент, поэтому часть пакетов пропадает. Не может коммутатор ретранслировать и пакеты, которые приходят из порта, в который коммутатор передает в данный момент.
Именно поэтому коммутаторы Cut-Trough постепенно вытесняются более совершенными.
Одно из усовершенствований коммутаторов получило название Interim Cut-Trough Switching (ICS). Оно направлено на то, чтобы избежать ретрансляции карликовых кадров. Для этого на принимающей стороне коммутатора все порты имеют буферную память FIFO на 512 бит. Если пакет заканчивается раньше, чем заполнится буфер, то содержимое буфера автоматически отбрасывается. Однако все остальные недостатки метода Cut-Through в данном случае сохраняются. Задержка ретрансляции коммутаторов данного типа увеличивается примерно на 400 битовых интервалов по сравнению с обычным Cut-Trough.
<
Коммутаторы Store-and-Forward
9.3.2. Коммутаторы Store-and-Forward
Коммутаторы Store-and-Forward (SAF) представляют собой наиболее дорогие, сложные и совершенные устройства данного типа. Они уже гораздо ближе к мостам и лишены перечисленных недостатков коммутаторов Cut-Trough. Главное их отличие состоит в полном буферировании во внутренней буферной памяти FIFO всех ретранслируемых пакетов. Размер каждого буфера при этом должен быть не меньше максимальной длины пакета. Соответственно значительно возрастает и задержка коммутации, она составляет не менее 12000 битовых интервалов. Карликовые и ошибочные кадры таким коммутатором отфильтровываются. Перегрузки возникают гораздо реже. /
Буферная память может размещаться на принимающей стороне всех портов (накопление перед коммутацией), на передающей стороне портов (накопление перед ретрансляцией), а также может быть общей для всех портов, причем эти методы часто комбинируются для достижения наибольшей гибкости и наивысшей производительности. Чем больше объем памяти, тем лучше коммутатор справляется с перегрузкой. Но с ростом объема памяти возрастает и стоимость оборудования. Иногда в состав коммутатора включается и процессор, но чаще коммутаторы выполняются на специализированных быстродействующих микросхемах, жестко специализированных именно на задачах коммутации пакетов.
Коммутаторы SAF, в отличие от других типов коммутаторов, могут поддерживать одновременно разные скорости передачи (10 Мбит/с и 100 Мбит/с). Полное буферирование пакета вполне позволяет передавать его не с той скоростью, с которой он поступил. В результате часть портов коммутатора может работать с сетью Ethernet, другая часть - с Fast Ethernet, причем некоторые коммутаторы автоматически настраивают свои порты на скорость передачи подключенного к порту сегмента. Поэтому коммутаторы SAF значительно облегчают переход с Ethernet на Fast Ethernet. Существуют уже коммутаторы, поддерживающие обмен с Gigabit Ethernet на скорости 1000 Мбит/с. Но в отличие от мостов коммутаторы, как правило, не меняют формат пакетов, поэтому сети с разными форматами пакетов нельзя объединять с их помощью.
Выпускаются также так называемые гибридные (или адаптивные) коммутаторы, которые могут автоматически переключаться из режима Cut-Through в режим SAF и наоборот. При малой нагрузке и при низком уровне ошибок они работают как более быстрые Cut-Through коммутаторы, а при большой нагрузке и при большом количестве ошибок переходят в более медленный, но более качественный режим SAF.
Наконец, еще одно важное достоинство коммутаторов по сравнению с ре-питерными концентраторами состоит в том, что они могут поддерживать режим полнодуплексной связи. Как уже отмечалось, при этом режиме резко упрощается обмен в сети, а скорость передачи в идеале удваивается (20 Мбит/с для Ethernet, 200 Мбит/с для Fast Ethernet).
Остановимся чуть подробнее на достоинствах и недостатках полнодуплексного режима.
Сегменты на витой паре и на оптоволоконном кабеле в любом случае используют две линии связи, одна из которых передает информацию в одну сторону, а другая - в другую. (Это не относится к сегментам 100BASE-T4, в которых есть двунаправленные витые пары, передающие в обе стороны по очереди). Но в стандартном полудуплексном режиме информация не передается по этим линиям связи одновременно. Однако если и адаптер, и коммутатор, связанные этими линиями связи, поддерживают полнодуплексный режим, то одновременная передача информации возможна. Естественно, аппаратура адаптера и коммутатора должна при этом обеспечивать прием приходящего из сети пакета и передачу своего пакета одновременно.
Полнодуплексный режим в принципе исключает любую возможность коллизии и делает ненужным сложный алгоритм управления обменом CSMA/CD. Каждый из абонентов (адаптер и коммутатор) может передавать в данном случае в любой момент без ожидания освобождения сети. В результате сеть нормально функционирует даже при нагрузке, приближающейся к 100% (в полудуплексном режиме - не более 30-40%). Особенно этот режим удобен для высокоскоростных серверов и высокопроизводительных рабочих станций.
Кроме того, отказ от метода CSMA/CD автоматически снимает ограничения на размер сети, связанные с ограничениями на двойное время распространения сигнала. Особенно это важно для Fast Ethernet и Gigabit Ethernet. При полнодуплексном режиме обмена размер любой сети ограничен только затуханием сигнала в среде передачи. Поэтому, например, сети Fast Ethernet и Gigabit Ethernet могут использовать оптоволоконные сегменты длиной 2 км и даже больше. При стандартном полудуплексном режиме, и методе CSMA/CD это было бы в принципе невозможно, так как двойное время распространения сигнала для Fast Ethernet не должно превышать 5,12 мкс, а для Gigabit Ethernet - 0,512 мкс (а при переходе на минимальную длину пакета в 512 байт - 4,096 мкс).
Полнодуплексный режим можно рассматривать как приближение к топологии классической активной звезды. Как и в активной звезде, здесь не может быть конфликтов, но требования к центру (как по надежности, так и по быстродействию) чрезвычайно велики. Как и при активной звезде, строить сети с большим количеством абонентов затруднительно, необходимо использовать много центров (в нашем случае - коммутаторов). Как и при активной звезде, стоимость оборудования оказывается довольно высокой, так как кроме сетевых адаптеров и соединительных кабелей нужны сложные, быстрые и дорогие коммутаторы. Но, видимо, все это неизбежная плата за повышение скорости обмена. Строго говоря, полнодуплексные сети уже трудно назвать классическими Ethernet и Fast Ethernet, так как в них уже ничего не остается ни от топологии «шина», ни от метода CSMA/CD. Сохраняется только формат пакета и (не всегда) метод кодирования.
Таким образом, в настоящее время коммутирующие концентраторы (коммутаторы) выполняют все больше функций, традиционно относившихся к мостам. Поэтому в пределах одной сети или однотипных сетей с одинаковыми форматами пакетов (Ethernet и Fast Ethernet) коммутаторы все больше и больше вытесняют мосты, так как они более быстрые и более дешевые. На долю мостов остается только соединение разнотипных сетей, что встречается не так уж и часто. Эта тенденция прослеживается и в других областях электроники: узко специализированные быстрые устройства вытесняют универсальные медленные. Универсальные устройства (компьютеры, универсальные контроллеры) сохраняются только там, где без них действительно не обойтись, где нужны очень сложные алгоритмы обработки, которые к тому же могут изменяться в соответствии с требованиями конкретной задачи.
<
Коммутирующие концентраторы Ethernet и Fast Ethernet
9.3. Коммутирующие концентраторы Ethernet и Fast Ethernet
Коммутирующие концентраторы (Switched Hubs), они же коммутаторы или переключатели, могут рассматриваться, как простейший и очень быстрый мост. Они позволяют разделить единую сеть на несколько сетей для увеличения допустимого размера сети или для снижения нагрузки (трафика) в отдельных частях сети.
Как уже отмечалось, в отличие от мостов, коммутирующие концентраторы не принимают приходящие пакеты, а только переправляют из одной части сети в другую те пакеты, которые в этом нуждаются. Они в реальном темпе поступления битов распознают адрес приемника пакета и принимают решение о том, надо ли это пакет переправлять, и если надо, то кому. Никакой обработки пакетов не производится, поэтому коммутаторы практически не замедляют обмена по сети, но они не могут преобразовывать формата пакетов и протоколов обмена по сети. Так как коммутаторы работают с информацией, находящейся внутри кадра, часто говорят, что они ретранслируют кадры, а не пакеты, как репитерные концентраторы.
Коллизии коммутатором не ретранслируются, что выгодно отличает его от более простого репитерного концентратора.
Логическая структура коммутатора довольно проста (Рисунок 9.6). Она включает в себя так называемую перекрестную матрицу (crossbar matrix), во всех точках пересечения которой могут устанавливаться связи на время передачи пакета. В результате пакет, поступающий из любого сегмента, может быть передан в любой другой сегмент (Рисунок 9.6) или, в случае широковещательного пакета, — во все другие сегменты одновременно (Рисунок 9.7).
Коммутаторы выпускаются на различное число портов. Чаще всего встречаются коммутаторы с 6, 8, 12, 16 и 24 портами. Отметим, что мосты, как правило, редко поддерживают более 4 портов. Различаются коммутаторы и допустимым количеством адресов на один порт. Этот показатель определяет предельную сложность подключаемых к порту сегментов (количество компьютеров в каждом сегменте). Некоторые коммутаторы позволяют разбивать порты на группы, работающие независимо друг от друга, то есть один коммутатор может работать как два или три.
Концентраторы класса I и класса II
9.2.2. Концентраторы класса I и класса II
Стандарт IEEE 802.3 определяет два класса репитерных концентраторов, отличающихся друг от друга своими функциональными возможностями и возможными областями применения. Каждый концентратор должен иметь маркировку своего класса в виде римской цифры I или II, заключенной в кружок.
Концентраторы (репитеры) класса II - это классические концентраторы, использовавшиеся с самого начала в сетях Ethernet. Именно поэтому их применение было разрешено и в сетях Fast Ethernet. Эти концентраторы отличаются тем, что непосредственно повторяют приходящие на них из сегмента сигналы и передают их в другие сегменты без какого бы то ни было преобразования. (То есть они не могут преобразовывать методы кодирования сетевых сигналов.) Поэтому к ним можно подключать только сегменты, использующие одну систему сигналов. Например, к концентратору могут подключаться только одинаковые сегменты 10BASE-T или только одинаковые сегменты 100BASE-TX. Могут, правда, подключаться и разные сегменты, но они должны использовать один код передачи, например 10BASE-T и 10BASE-FL или 100BASE-TX и 100BASE-FX. Но данные концентраторы не могут объединять сегменты с разными системами кодирования, например 100BASE-TX и 100BASE-T4.
Задержка сигналов в концентраторах класса II меньше, чем в концентраторах класса I. Согласно стандарту, она должна составлять от 46 битовых интервалов (для 100BASE-TX/FX) до 67 битовых интервалов (для 100BASE-T4). Отсюда следуют ограничения на наращиваемость таких концентраторов и на количество их портов (как правило, оно не превышает 24). Зато меньшая задержка концентратора позволяет использовать кабели большей длины, так как на работоспособность сети влияет суммарная задержка сигнала в сети, включающая в себя как задержки концентраторов, так и задержки в кабелях.
Для соединения концентраторов класса II между собой используется специальный порт расширения (UpLink port). Каждый концентратор подключается этим портом к одному из обычных портов другого концентратора (Рисунок 9.5).
Логическая схема коммутатора
Рисунок 9.6. Логическая схема коммутатора

Коммутаторы характеризуются двумя показателями производительности: максимальной и совокупной скоростью ретрансляции пакетов. Максимальная скорость ретрансляции измеряется при передаче пакетов из одного порта в другой, когда все остальные порты отключены. Совокупная скорость измеряется при активной работе всех имеющихся портов. Совокупная скорость больше максимальной, но максимальная скорость, как правило, не может быть обеспечена на всех портах одновременно, хотя коммутаторы и способны одновременно обрабатывать несколько пакетов (в отличие от моста).
Главное правило, которого надо придерживаться при разбиении сети на части (сегменты) с помощью коммутатора, называется «правило 80/20». Только при его выполнении коммутатор работает эффективно. Согласно этому правилу, надо обеспечить, чтобы не менее 80 процентов всех передач происходило в пределах одной части (одного сегмента) сети. И только 20 процентов всех передач должно быть между разными частями (сегментами) сети, проходить через коммутатор. На практике это обычно сводится к тому, что сервер и активно работающие с ним рабочие станции (клиенты) располагаются на одном сегменте. Это же правило 80/20 применимо и к мостам.
Маршрутизируемая сеть на основе FDDI
Рисунок 9.11. Маршрутизируемая сеть на основе FDDI

Маршрутизируемое облако
Рисунок 9.12. Маршрутизируемое облако

Как уже отмечалось, можно считать, что репитерные концентраторы работают с пакетами, а мосты и коммутаторы — с кадрами. Маршрутизаторы обрабатывают адресную информацию, относящуюся к структуре дейтаграммы IP (IPX), которая вложена в область данных кадра, в свою очередь вложенного в пакет (см. Рисунок 3.3). Поэтому говорят, что они работают с дейтаграммами, ретранслируют дейтаграммы.
В дейтаграмму входят сетевые адреса, которые определяют абонентов (передающего и принимающего) в маршрутизованной сети, состоящей из множества обычных сетей. Например, сетевой адрес дейтаграммы IPX состоит из 10 байт (Рисунок 9.13) и включает в себя поле номера сети (4 байта), а также поле идентификатора абонента (6 байт), повторяющее физический адрес (МАС-адрес) абонента. Маршрутизатор обрабатывает именно поле номера сети из сетевого адреса принимающего абонента. Под сетью в данном случае понимается широковещательная область. То есть сеть, разделенная только мостами, коммутаторами и репитерными концентраторами, считается единой сетью с одним номером сети.
Мосты и маршрутизаторы Ethernet и Fast Ethernet
9.4. Мосты и маршрутизаторы Ethernet и Fast Ethernet
Мосты и маршрутизаторы, строго говоря, не совсем правильно относить к специфическому сетевому оборудованию. В большинстве случаев они представляют собой универсальные компьютеры, работающие в сети и выполняющие специфическую функцию соединения двух и более частей сети, хотя существуют мосты и маршрутизаторы, жестко специализированные на работе в сети. В частности, маршрутизаторы выпускаются рядом фирм в виде модулей, устанавливаемых в концентраторы на базе шасси. Понятно, что их стоимость ниже, чем маршрутизаторов на базе компьютеров.
Несколько слов о производительности адаптера
Несколько слов о производительности адаптера.
Реальная скорость обмена информацией по сети представляет собой интегральный параметр, зависящий не только от адаптера, но и от компьютера (быстродействия процессора и диска, объема памяти), от среды передачи (уровня помех), от программных средств, от величины загрузки сети и т.д. Поэтому выбор самого быстрого (и дорогого) адаптера далеко не всегда гарантирует заметный выигрыш в скорости обмена. Например, переход с 8-разрядного адаптера ISA на 16-разрядный или с ISA адаптера на 32-разрядный PCI адаптер может практически не сказаться на скорости. Тем не менее, нередки ситуации, когда именно адаптер становится самым узким местом в системе и его замена может резко увеличить производительность сети.
Косвенные показатели производительности адаптера уже были перечислены: производительнее всего работают те, которые рассчитаны на PCI, поддерживают режим разделения буферной памяти и имеют буферную память большего объема. Быстрее будут те адаптеры, которые максимальное количество функций выполняют без участия процессора, опираясь на свой собственный встроенный интеллект.
Но получить реальные количественные показатели производительности можно только в результате тестирования всей сети в целом. Для этого существует целый ряд тестовых программ, наиболее известны из которых Performs фирмы Novell и Netbench 3.0 фирмы Ziff-Davis. Любые тестовые программы слабо отражают реальную ситуацию в сети, но позволяют сравнивать между собой различные сетевые адаптеры в условиях, близких к реальным, и в реальной конфигурации аппаратных средств.
<
Петля в сети с мостами
Рисунок 9.9. Петля в сети с мостами

Благодаря этому можно специально дублировать соединение сегментов посредством мостов (создавать петли) для того, чтобы при отказе одной из линий связи автоматически восстанавливать целостность сети по альтернативному маршруту. Кстати, этот же алгоритм остовного дерева поддерживают и некоторые коммутаторы, которые тоже не способны работать в сети с петлями.
Мосты, как и коммутаторы, разделяют зону конфликта (область коллизии), но не разделяют широковещательную область (broadcast domain), то есть часть сети, в которой свободно проходят широковещательные пакеты. В результате нагрузка на каждый сегмент уменьшается, а ограничения на размер сети преодолеваются.
Одновременно мост может обрабатывать (ретранслировать) только один пакет, а не несколько, как коммутатор. Любой пакет, приходящий на один из портов, обрабатывается следующим образом:
1. Мост выделяет адрес источника (отправителя) пакета и ищет его в таблице адресов абонентов, относящейся к данному порту. Если этого адреса в таблицу нет, то он туда добавляется. Таким образом, автоматически формируется таблица адресов всех абонентов каждого сегмента из подключенных к портам моста.
2. Мост выделяет адрес приемника (получателя) пакета и ищет его в таблицах адресов, относящихся ко всем портам. Если пакет адресован в тот же сегмент, из которого он пришел, то он не ретранслируется (отфильтровывается). Если пакет широковещательный или многопунктовый (групповой), то он ретранслируется во все порты, кроме принявшего. Если пакет однопунктовый (адресован одному абоненту), то он ретранслируется только в тот порт, к которому присоединен сегмент с этим абонентом. Наконец, если адрес приемника не обнаружен ни в одной из таблиц адресов, то пакет посылается во все порты, кроме принявшего (как широковещательный).
Таблицы адресов абонентов имеют ограниченный размер, поэтому они формируются так, чтобы иметь возможность автоматического обновления их содержимого. Адреса тех абонентов, которые долго не присылают пакеты, через заданное время (обычно 5 минут) стираются из таблицы. Это гарантирует, что адрес абонента, отключенного от сети или перенесенного в другой сегмент, не будет занимать лишнего места в таблице.
Так как мост, как и коммутатор, анализирует информацию внутри кадра (физические адреса, МАС-адреса), часто говорят, что он ретранслирует кадры, а не пакеты (в отличие от репитера или репитерного концентратора).
Как и в случае коммутаторов, для эффективной работы моста необходимо выполнять упоминавшееся «правило 80/20», то есть большинство передач (не менее 80%) должно быть внутрисегментными, а не межсегментными.
Традиционно мосты подразделяются на внутренние и внешние.
Внутренние мосты выполняются на основе компьютера-сервера, в который устанавливают сетевые адаптеры (обычно до четырех), подключенные к разным сегментам сети. Строго говоря, именно эти сетевые адаптеры и соответствующие программные средства и называются внутренним мостом.
Внешний мост представляет собой рабочую станцию, в которую установлены два сетевых адаптера. В этом случае, в отличие от внутреннего моста, сегменты могут быть только однотипными (например, Ethernet-Ethernet).
Внешний мост может быть выделенным (dedicated) или невыделенным (non-dedicated) в зависимости от того, выполняет ли компьютер рабочей станции еще какие-нибудь функции, кроме сетевых. Термин «внешний» употребляется в этом случае по отношению к серверу, как основному компьютеру сети. В любой сети может присутствовать одновременно как внешний, так и внутренний мост или несколько мостов.
Как и коммутаторы Store-and-Forward, мосты могут поддерживать обмен между сегментами с разной скоростью передачи (Ethernet и Fast Ethernet), а также обеспечивать сопряжение полудуплексных и полнодуплексных сегментов. Полный прием пакетов в буферную память моста и их последующая передача легко решают подобные проблемы. Но мосты могут также сопрягать сети Ethernet и Fast Ethernet с сетями любых других типов, например, FDDI или Token-Ring, что не по силам большинству коммутаторов.
<
Репитеры и концентраторы Ethernet и Fast Ethernet
9.2. Репитеры и концентраторы Ethernet и Fast Ethernet
Использование репитеров и концентраторов в сети Ethernet не является обязательным. Небольшие сети на основе сегментов 10BASE2 или 10BASE5 вполне могут обойтись без них. Для сетей из нескольких таких сегментов необходимы простейшие репитеры. А при выборе в качестве среды передачи витой пары или оптоволоконного кабеля уже необходимы концентраторы (если, конечно, в сеть объединяются не два компьютера, а хотя бы три). Для сети Fast Ethernet концентраторы совершенно необходимы.
<
Ретрансляция широковещательного пакета
Рисунок 9.7. Ретрансляция широковещательного пакета

Существует два класса коммутаторов, отличающихся уровнем интеллек^-та и способами коммутации:
коммутаторы со сквозным вырезанием (Cut-Through);
коммутаторы с накоплением и ретрансляцией (Store-and-Forward, SAF).
Рассмотрим кратко их особенности.
<
Сетевой адаптер с внешним трансивером, устанавливаемым на плату
Рисунок 9.2. Сетевой адаптер с внешним трансивером, устанавливаемым на плату

<
Сетевой адаптере внешнимтрансивером на МП-кабеле
Рисунок 9.1. Сетевой адаптере внешнимтрансивером на МП-кабеле

Соединение двух концентраторов класса II
Рисунок 9.5. Соединение двух концентраторов класса II

Концентраторы класса II сложнее в производстве, чем концентраторы класса I, так как временные требования, предъявляемые к ним, жестче. Но при этом возможности их меньше, поэтому в настоящее время их постепенно вытесняют концентраторы класса I.
Концентраторы (репитеры) класса I характеризуются тем, что они преобразуют приходящие по сегментам сигналы в цифровую форму, прежде чем передавать их во все другие сегменты. В отличие от концентраторов класса II, они способны преобразовывать коды, применяемые в разных сегментах, поэтому к ним можно одновременно подсоединять сегменты разных типов, например 100BASE-TX, 100BASE-T4 и 100BASE-FX. Но этот процесс преобразования требует времени, поэтому данные концентраторы оказываются медленнее (по стандарту, их задержка составляет не более 140 битовых интервалов).
Концентраторы класса I более гибкие, они имеют более широкие возможности по наращиваемости. Именно из них строятся сложные концентраторы на базе шасси. К тому же благодаря внутренним цифровым шинам сигналов они допускают управление с удаленных рабочих станций, позволяющих контролировать нагрузку сети, состояние портов, интенсивность ошибок в сети, а также автоматически отключать неисправные сегменты. При этом для обмена с управляющей станцией применяется специально разработанный протокол обмена SNMP (Simple Network Management Protocol — простой протокол управления сетью). Такой концентратор, допускающий удаленное управление, называется интеллектуальным (Intelligent Hub).
Протокол SNMP был предложен в 1988 году комиссией IAB (Internet Activities Board). Он описывается документами RFC 1067, RFC 1098, RFC 1157. Комиссия IAB определила также и метод описания данных для этого протокола под названием ASN.l (Abstract Syntax Notation). Протокол SNMP относится к прикладному уровню, он работает с протоколами IP и IPX. Он позволяет как собирать информацию о сети, так и управлять устройствами сети.
Протокол SNMP подразумевает хранение информации об устройствах сети в формате ASN.1 в виде текстовых файлов, каждый из которых называется MIB (Management Information Base - база управляющей информации). Например, в случае интеллектуального концентратора с него можно считать информацию о количестве пакетов, переданных и полученных каждым из портов, можно также включить и выключить каждый порт. Но это далеко не все возможности управления с помощью SNMP.
Чтобы управлять устройством сети, контроллер этого устройства должен выполнять программу агента SNMP. Программа агента собирают данные о системе, в которой они запущены и управляют объектами данных системы.
Рабочая станция, управляющая сетью (NMS - Network Management Station) - это один из компьютеров, подключенных к сети, на котором запущен специальный пакет прикладных программ, которые в удобном графическом виде отображают состояние сетевых устройств и позволяют управлять ими.
Протокол SNMP поддерживает три типа команд:
Команда GET читает значения объектов данных устройства (из MIB) в произвольном порядке.
Команда GET NEXT читает следующее по порядку значение объекта данных устройства.
Команда SET применяется для изменений (записи) значений объектов данных устройства.
Команды и реакции протокола SNMP передаются посредством модулей данных в составе дейтаграмм (PDU - Protocol Data Unit). Протокол предусматривает также передачу информации о типе кодирования MIB, поэтому в разных устройствах MIB может иметь различный формат. Существует ряд фирменных и стандартных форматов MIB для сетевых адаптеров (MIB-II), концентраторов, мостов и сети в целом (RMON MIB), поддерживаемых SNMP.
<
Структура наращиваемого концентратора
Рисунок 9.3. Структура наращиваемого концентратора
Самые сложные концентраторы на базе единого шасси (Рисунок 9.4) позволяют путем перекоммутации связей на контактной задней панели строить сложные конфигурации сетей. Например, они могут одновременно поддерживать несколько типов сетей (Token-Ring, Ethernet и FDDI), допускают включение не только модулей репитерных концентраторов, но и модулей маршрутизаторов и коммутаторов. На основе такого концентратора можно также организовывать одновременно несколько независимых однотипных сетей (например,'Ethernet) для разделения информационных потоков между ними, снижения нагрузки на сеть.
Как правило, концентраторы на базе шасси предусматривают возможность довольно сложного управления обменом. Количество портов таких концентраторов может доходить до 288. Правда, этот тип концентратора оказывается обычно самым дорогим в расчете на один порт. Считается, что их применение становится экономически оправданным только в случае необходимости поддержки большого количества портов (около 100).
Существуют также совсем простые и самые дешевые репитеры и концентраторы, выполненные в виде платы, вставляемой в разъем системной шины ISA компьютера (из компьютера они берут при этом только питание). Недостаток такого решения состоит в том, что для работы сети необходимо, чтобы компьютер, в который включена плата репитера (концентратора), был постоянно включен (в идеале - круглосуточно). При выключении питания этого компьютера связь по сети становится невозможной.
Двухточечное соединение без концентратора
Рисунок 10.4. Двухточечное соединение без концентратора

Модель 1 выделяет три возможных конфигурации сети Fast Ethernet:
1. Соединение двух абонентов (узлов) сети напрямую, без репитера или концентратора (Рисунок 10.4). Абонентами при этом могут выступать не только компьютеры, но и сетевой принтер, порт коммутатора, моста или маршрутизатора. Это соединение называется соединением DTE—DTE или двухточечным.
2. Соединение двух абонентов сети с помощью одного репитер-ного концентратора класса I или класса II (Рисунок 10.5).
3. Соединение двух абонентов сети с помощью двух репитер-ных концентраторов класса II (Рисунок 10.6). При этом предполагается, что для связи концентраторов всегда используется электрический кабель длиной не более 5 м. Концентраторы класса II имеют меньшую задержку, поэтому их может быть два. Использование трех концентраторов не допускается в соответствии с моделью 1 ни в коем случае.
Выбор конфигурации сетей Ethernet и Fast Ethernet
Глава 10. Выбор конфигурации сетей Ethernet и Fast Ethernet
Первая модель формулирует набор простых
10.1.1. Правила модели 1
Первая модель формулирует набор простых правил, которые необходимо соблюдать проектировщику сети при соединении отдельных компьютеров и сегментов.
1. Репитер или концентратор, подключенный к сегменту, снижает на единицу максимально допустимое число абонентов, подключаемых к сегменту.
2. Полный путь между двумя любыми абонентами должен включать в себя не более пяти сегментов, четырех концентраторов (репитеров) и двух трансиверов (MAU) для сегментов 10 BASES.
З.Если путь между абонентами состоит из пяти сегментов и четырех концентраторов (репитеров), то количество сегментов, к которым подключены компьютеры, не должно превышать трех, а остальные сегменты должны просто связывать между собой концентраторы (репитеры). Это так называемое «правило 5-4-3».
4. Если путь между абонентами состоит из четырех сегментов и трех концентраторов (репитеров), то должны выполняться следующие условия:
максимальная длина оптоволоконного кабеля сегмента 10BASE-FL, соединяющего между собой концентраторы (репитеры), не должна превышать 1000 м;
максимальная длина оптоволоконного кабеля сегмента 10BASE-FL, соединяющего концентраторы (репитеры) с компьютерами, не должна превышать 400 м;
ко всем сегментам могут подключаться компьютеры.
10.2.1. Правила модели 1
В соответствии с первой моделью, при выборе конфигурации в любом случае надо руководствоваться следующими принципами:
Сегменты, выполненные на электрических кабелях (витых парах) не должны быть длиннее 100 м. Это относится к кабелям всех возможных категорий - 3, 4 и 5, к сегментам 100BASE-T4 и 100BASE-TX.
Сегменты, выполненные на оптоволоконных кабелях, не должны быть длиннее 412м.
Если используются адаптеры с внешними (выносными) трансиверами, то трансиверные кабели (МП) не должны быть длиннее 50 см.
Пример максимальной конфигурации сети Fast Ethernet
Рисунок 10.7. Пример максимальной конфигурации сети Fast Ethernet
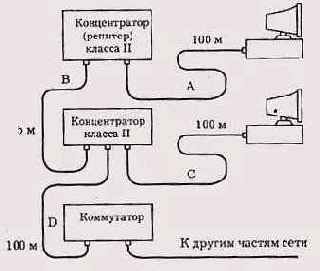
Здесь максимальный размер зоны конфликта складывается из сегментов А, В и С, то есть составляет:
100 + 5 + 100 = 205 метров,
что удовлетворяет условию работоспособности сети (табл. 10.4, верхняя строчка). Отметим, что сегмент D также входит в зону конфликта, так как коммутатор тоже является полноправным передатчиком пакетов сети. Поэтому длина сегмента D также не может превышать в нашем случае 100 м, чтобы суммарная длина сегментов А, В и D не превысила все тех же 205 м. Сегменты, отделенные от рассматриваемой зоны конфликта коммутатором, никак не влияют на ее работоспособность.
<
Пример максимальной конфигурации в соответствии с первой моделью
Рисунок 10.1. Пример максимальной конфигурации в соответствии с первой моделью
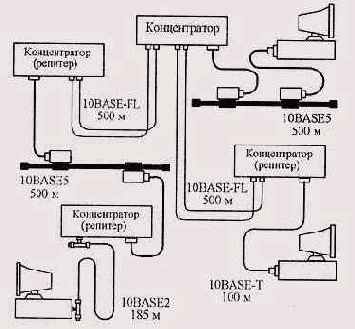
При выполнении этих правил можно быть уверенным, что сеть будет работоспособной. Никаких дополнительных расчетов в данном случае не требуется. Считается, что соблюдение данных правил гарантирует допустимую величину задержки сигнала в сети.
На Рисунок 10.1 показан пример максимальной конфигурации, удовлетворяющей этим правилам. Здесь максимально возможный путь (диаметр сети) проходит между двумя нижними по рисунку абонентами: он включает в себя пять сегментов (10BASE2, 10BASE5, 10BASE-FL, 10BASE-FL и 10BASE-T), четыре концентратора (репитера) и два трансивера MAU.
<
Пример работоспособной конфигурации сети, нарушающей
Рисунок 10.8. Пример работоспособной конфигурации сети, нарушающей правила модели 1
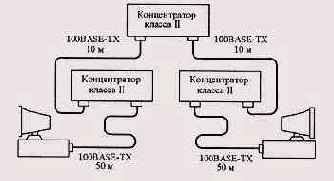
4. Для двух абонентов ТХ задержка будет равна 100 битовым интервалам.
5. Итого суммарная задержка будет составлять:
276 + 22,24+ 111,2 + 100 = 509,44 битовых интервала. Данная сеть работоспособна, но при этом надо учитывать, что каждый дополнительный концентратор класса II уменьшает общую допустимую длину кабеля на величину 92/1,112 = 82,7 м. Сеть с четырьмя концентраторами уже не будет иметь смысла, так как на задержку в кабеле уже не остается почти никакого запаса (четыре концентратора дадут суммарную задержку в 92 • 4 = 368 битовых интервалов).
Вторая модель, применяемая для оценки
10.1.2. Расчет по модели 2
Вторая модель, применяемая для оценки конфигурации Ethernet, основана на точном расчете временных характеристик выбранной конфигурации сети. Она иногда позволяет выйти за пределы жестких ограничений модели 1. Применение модели 2 совершенно необходимо в том случае, когда размер проектируемой сети близок к максимально допустимому.
В модели 2 используются две системы расчетов:
первая система предполагает вычисление двойного (кругового) времени прохождения сигнала по сети и сравнение его с максимально допустимой величиной;
вторая система проверяет допустимость величины получаемого межкадрового временного интервала, межпакетной щели (IPG - InterPacket Gap) в сети.
При этом вычисления в обеих системах расчетов ведутся для наихудшего случая, для пути максимальной длины, то есть для такого пути передаваемого по сети пакета, который требует для своего прохождения максимального времени. При первой системе расчетов выделяются три типа сегментов:
начальный сегмент — это сегмент, соответствующий началу пути максимальной длины;
конечный сегмент — это сегмент, расположенный в конце пути максимальной длины;
промежуточный сегмент - это сегмент, входящий в путь максимальной длины, но не являющийся ни начальным, ни конечным.
10.2.2. Расчет по модели 2
Вторая модель для сети Fast Ethernet, как и в случае Ethernet, основана на вычислении суммарного двойного времени прохождения сигнала по сети. В отличие от второй модели, используемой для оценки конфигурации Ethernet, здесь не проводится расчетов величины сокращения межкадрового интервала (межпакетной щели, IPG). Это связано с тем, что даже максимальное количество репитеров и концентраторов, допустимых в Fast Ethernet, в принципе не может вызвать недопустимого сокращения межкадрового интервала.
Сеть Ethernet максимально возможной длины
Рисунок 10.2. Сеть Ethernet максимально возможной длины

Из таблицы 10.1 видно, что при выборе максимальной длины обоих сегментов по 2000 метров (один из них будет начальным, а другой - конечным) суммарная двойная задержка распространения составит:
212,3 + 356,5 = 568,8,
сто значительно больше допустимой величины 512. То есть реальная длина :ети будет даже меньше, чем 4 км. Элементарный расчет показывает, что три двух одинаковых сегментах 10BASE-FL длина каждого из них не дол-
жна превышать 1716 м. Двойная задержка распространения при этом будет вычисляться так (табл. 10.1):
12,3 + 1716 • 0,1+ 156,5 + 1716 • 0,1 = 512.
И общая длина сети будет при этом составлять 3432 м, что значительно меньше теоретически возможной длины в 6500 м. Отметим, что сегменты в конфигурации на Рисунок 10.2 могут быть и разной длины, но их общая длина не должна превышать все тех же 3432 м. При этом стоит еще учитывать, что мы не включали в расчет задержки трансиверных кабелей. Если используются внешние трансиверы, то необходимо еще уменьшить длину оптоволоконных кабелей.
Попробуем теперь оценить максимально возможный размер сети при использовании только электрического кабеля, например, наиболее популярной сейчас витой пары.
Допустим, мы имеем конфигурацию из пяти сегментов 10BASE-T предельно допустимой длины (100 м), соединенных между собой четырьмя концентраторами. Задержка начального сегмента составит (из табл. 10.1) 26,6 битовых интервалов. Задержка конечного сегмента будет равна 176,3 битовых интервалов. Задержка трех промежуточных сегментов будет 53,3 битовых интервала на каждый сегмент. Итого суммарная задержка равняется:
26,6 + 176,3 + 3 • 53,3 = 362,8, что меньше предельной величины 512.
Мы можем добавить еще два промежуточных 100-метровых сегмента, которые дадут еще 106,6, увеличив количество сегментов до 7, а количество концентраторов до 6. И еще останется запас в 42,6 битовых интервалов. Всего получаем, что сегментов может быть даже 8 при семи концентраторах, а общая длина всех кабелей может достигать 705,3 м. Это значительно превышает ограничения модели 1.
Но подсчитаем, какая величина сокращения межкадрового интервала получается при такой конфигурации. Один начальный сегмент даст 16 битовых интервалов (см. табл. 10.2). Шесть промежуточных сегментов дадут 77 битовых интервалов. В сумме получится 93 битовых интервала, что значительно превышает разрешенные 49 битовых интервалов. Поэтому в данном случае предельная длина сети будет ограничена пятью сегментами, которые сократят межкадровый интервал на величину 16+11 • 3 = 49 битовых интервалов.
В результате сеть максимального размера на витой паре будет состоять из пяти сегментов по 100 м (Рисунок 10.3), что совпадает с требованиями модели 1. Полная длина сети составит 500 м.
Сеть Ethernet максимального размера на витой паре
Рисунок 10.3. Сеть Ethernet максимального размера на витой паре

Интересно, что пути максимальной длины для расчета круговой задержки и для расчета IPG могут быть различными. Вполне возможна ситуация, когда максимальную задержку прохождения дает один путь в сети, а максимальное сокращение IPG дает другой путь. Например, если один путь состоит из пяти коротких сегментов (электрических и оптоволоконных) и четырех концентраторов, а другой путь имеет всего два оптоволоконных сегмента, но зато с суммарной длиной, близкой к максимально возможной, то первый даст максимальное сокращение IPG, а второй — максимальную задержку прохождения сигнала.
Значит, в идеале необходимо рассчитывать как круговую задержку, так и сокращение IPG для каждого из возможных путей в данной топологии сети. А условие работоспособности сети будет состоять в том, что все задержки всех путей должны быть меньше 512 битовых интервалов, а все величины сокращения IPG для всех путей должны быть меньше 49 битовых интервалов. Правда, неоднозначность пути максимальной длины надо учитывать только в том случае, когда в сети присутствует больше четырех концентраторов, так как четыре концентратора (пять сегментов) в принципе не могут уменьшить APG больше, чем на 49 битовых интервалов при выборе любых возможных сегментов (см. табл. 10.2).
Таким образом, для оценки работоспособности той или иной конфигурации можно использовать обе модели (модель 1 и модель 2), хотя для сложных топологий и предельно длинных сегментов предпочтительнее вторая (числовая) модель, позволяющая количественно оценить временные характеристики сети. В случае же более простых топологий вполне достаточно проверить выполнение элементарных правил первой модели, что не требует никаких расчетов.
<
Сеть Fast Ethernet максимальной длины
Рисунок 10.9. Сеть Fast Ethernet максимальной длины

А теперь посмотрим, какова может быть максимальная величина сети Fast Ethernet. Для этого надо взять сеть с одним концентратором класса II и два сегмента 100BASE-FX. Элементарный расчет показывает, что при одинаковых сегментах длина каждого из них может достигать 160 метров (Рисунок 10.9), а общая длина сети составит 320 метров. Расчет двойного времени прохождения для этого случая будет выглядеть так:
92 + 100 + 2 • 1,0 • 160 = 512.
Получается, что сеть работоспособна, хотя и на пределе. Естественно, в данном случае важна только суммарная длина обоих кабелей. При уменьшении длины какого-нибудь из сегментов можно без потери работоспособности увеличить на точно такую же величину длину другого сегмента.
Если в приведенной на Рисунок 10.9 конфигурации используется концентратор класса I, а не концентратор класса II, то допустимая суммарная длина сегментов сокращается с 320 м до 272 м (расчет для этого случая очевиден). А с учетом рекомендуемого стандартом запаса лучше еще уменьшить суммарную длину кабеля на 1-4 м, что даст снижение круговой задержки на 1-4 битовых интервала.
В заключение отметим, что модель 2 целесообразно применять в основном при наличии в сети оптоволоконных сегментов. На электрическом кабеле даже при большом желании довольно трудно создать сеть слишком большого размера.
<
Соединение сдвумя концентраторами
Рисунок 10.6. Соединение сдвумя концентраторами

В случае первой конфигурации правила модели 1 предельно простые: электрический кабель не должен быть длиннее 100 м, полудуплексный оптоволоконный не должен быть длиннее 412м, полнодуплексный оптоволоконный - 2000 м (при этом задержка сигнала в кабеле уже не имеет значения, так как метод CSMA/CD не работает).
В случае применения конфигурации с одним концентратором надо ограничивать длину кабелей сети в соответствии с таблицей 10.3.
В случае выбора конфигурации с двумя концентраторами надо ограничивать длину кабелей А и В в соответствии с таблицей 10.4 (по умолчанию предполагается, что кабель С имеет длину 5 м).
Величины задержек
Таблица 10.1. Величины задержек для расчета двойного времени прохождения сигнала (задержки даны в битовых интервалах)
| Тип сегмента Ethernet | Макс, длина м | Начальный сегмент | Промежуточный сегмент | Конечный сегмет
tm | Задержка на метр длины, | ||||||||||
| 10BASE5 | 500 | 11,8 | 55,0 | 46,5 89,8 | 169,5 | 212,8 | 0,087 | ||||||||
| 10BASE2 | 185 | 11,8 | 30,8 | 46,5 65,5 | 169,5 | 188,5 | 0,103 | ||||||||
| 10BASE-T | 100 | 15,3 | 26,6 | 42,0 53,3 | 165,0 | 176,3 | 0,113 | ||||||||
| 10BASE-FL | 2000 | 12,3 | 212,3 | 33,5 233,5 | 156,5 | 356,5 | 0,100 | ||||||||
| FOIRL | 1000 | 7,8 | 107,8 | 29,0 129,0 | 152,0 | 252,0 | 0,100 | ||||||||
| AUI | 50 | 0 | 5,1 | 0 5,1 | 0 | 5,1 | 0,103 |
Промежуточных сегментов в выбранном пути может быть несколько, а начальный и конечный сегменты при разных расчетах могут меняться местами друг с другом. Выделение трех типов сегментов позволяет автоматически учитывать задержки сигнала на всех концентраторах, входящих в путь максимальной длины, а также в приемопередающих узлах адаптеров.
Для расчетов используются величины задержек, представленные в таблице 10.1. Методика расчета сводится к следующему.
1. В сети выделяется путь максимальной длины. Все дальнейшие расчеты ведутся для него. Если этот путь не очевиден, то расчеты ведутся для всех возможных путей, и на основании этих расчетов выбирается путь максимальной длины.
2. Если длина сегмента, входящего в выбранный путь, не максимальна, то рассчитывается двойное (круговое) время прохождения в каждом сегменте выделенного пути по формуле: ts = LtL + to, где L — длина сегмента в метрах (при этом надо учитывать тип сегмента: начальный, промежуточный или конечный).
3. Если длина сегмента равна максимально допустимой, то из таблицы для него берется величина максимальной задержт ки t .
4. Суммарная величина задержек всех сегментов выделенного пути не должна превышать предельной величины 512 битовых интервалов (51,2 мкс).
5. Выполняются те же действия для обратного направления выбранного пути (то есть конечный сегмент считается начальным, и наоборот).
Из-за разных задержек передающих и принимающих узлов концентраторов величины задержек в разных направлениях могут отличаться (правда, не слишком сильно).
6. Если задержки в обоих случаях не превышают величины 512 битовых интервалов, то сеть считается работоспособной.
Например, для конфигурации, показанной на Рисунок 10.1, путь наибольшей длины - это путь между двумя нижними по рисунку компьютерами. В данном случае это довольно очевидно. Этот путь включает в себя пять сегментов (слева направо): 10BASE2,10BASE5,10BASE-FL (два сегмента) и 10BASE-T.
Произведем расчет, считая начальным сегментом 10BASE2, а конечным -10BASE-T.
1. Начальный сегмент 10BASE2 имеет максимально допустимую длину (185 м), следовательно, для него берем из таблицы величину задержки 30,8.
2. Промежуточный сегмент 1 OBASE5 также имеет максимально допустимую длину (500 м), поэтому для него берем из таблицы величину задержки 89,8.
3. Оба промежуточных сегмента 10BASE-FL имеют длину 500 м, следовательно, задержка каждого из них будет вычисляться по формуле:
500 • 0,100 + 33,5 = 83,5.
1. Конечный сегмент 10BASE-T имеет максимально допустимую длину (100 м), поэтому из таблицы берем для него величину задержки 176,3.
2. В путь наибольшей длины входят также шесть АШ-кабе-лей: два из них (в сегменте 10BASE5) показаны на рисунке, а четыре (в двух сегментах 10BASE-FL) не показаны, но в реальности вполне могут присутствовать. Будем считать, что суммарная длина всех этих кабелей равна 200 м, то есть четырем максимальным длинам. Тогда задержка на всех АШ-кабелях будет равна
4 • 5,1 = 20,4.
1. В результате суммарная задержка для всех пяти сегментов составит:
30,8 + 89,8 + 83,5 + 83,5 + 176,3 + 20,4 = 484,3,
что меньше, чем предельно допустимая величина 512, то есть сеть работоспособна.
произведем теперь расчет суммарной задержки для того же пути, но в )братном направлении. При этом начальным сегментом будет 10BASE-T, i конечным - 10BASE2. В конечной сумме изменятся только два слагаемых (промежуточные сегменты остаются промежуточными).
Для началь-гого сегмента 10BASE- T максимальной длины задержка составит 26,6 >итовых интервалов, а для конечного сегмента 10BASE2 максимальной (лины задержка составит 188,5 битовых интервалов. Суммарная задер-кка будет равняться
26,6 + 83,5 + 83,5 + 89,8 + 188,5 + 20,4 = 492,3, то опять же меньше 512.
Работоспособность сети подтверждена.
Однако расчета двойного времени прохождения, в соответствии со стандартом, еще не достаточно, чтобы сделать окончательный вывод о работоспособности сети.
Второй расчет, применяемый в модели 2, проверяет соответствие стандарту величины межкадрового интервала (IPG). Эта величина изначально не должна быть меньше, чем 96 битовых интервалов (9,6 икс), то есть только через 9,6 мкс после освобождения сети абоненты могут начать свою передачу. Однако при прохождении пакетов (кадров) через репитеры и концентраторы межкадровый интервал может сокращаться, вследствие чего два пакета могут в конце концов восприниматься абонентами как один. Допустимое сокращение IPG определено стандартом в 49 битовых интервалов (4,9 мкс).
Величины сокращения межкадрового интервала (IPG) для разных сегментов Ethernet
Таблица 10.2. Величины сокращения межкадрового интервала (IPG) для разных сегментов Ethernet
| Сегмент | Начальный | Промежуточный | |||
| 10BASE2 | 16 | 11 | |||
| 10BASE5 | 16 | 11 | |||
| 10BASE-T | 16 | 11 | |||
| 10BASE-FL | 11 | 8 |
Для вычислений здесь так же, как и в предыдущем случае, используются понятия начального сегмента и промежуточного сегмента. Конечный сегмент не вносит вклада в сокращение межкадрового интервала, так как пакет доходит по нему до принимающего компьютера без прохождения репитеров и концентраторов.
Вычисления здесь очень простые. Для них используются данные табл. 10.2.
Для получения полной величины сокращения IPG надо просуммировать величины из таблицы для сегментов, входящих в путь максимальной длины, и сравнить сумму с предельной величиной 49 битовых интервалов. Если сумма меньше 49, мы можем сделать вывод о работоспособности сети. Для гарантии расчет производится в обоих направлениях выбранного пути.
Для примера обратимся все к той же конфигурации, показанной на Рисунок 10.1. Максимальный путь здесь — между двумя нижними по рисунку компьютерами. Берем в качестве начального сегмента 10BASE2. Для него сокращение межкадрового интервала равно 16. Далее следуют промежуточные сегменты: 10BASE5 (величина сокращения составит 11) и два сегмента 10BASE-FL (каждый из них внесет свой вклад по 8 битовых интервалов). В результате суммарное сокращение межкадрового интервала составит:
16 + 11+8 + 8 = 43,
что меньше предельной величины 49. Следовательно, данная конфигурация и по этому показателю будет работоспособна.
Вычисления для обратного направления по этому же пути дадут в данном случае тот же результат, так как начальный сегмент 10BASE-T даст ту же величину, что и начальный сегмент 10BASE2 (16 битовых интервалов), а все промежуточные сегменты опять же останутся промежуточными.
Попробуем теперь с помощью второй модели расчетов оценить, каков может быть максимальный размер сети Ethernet. Теоретически возможный размер сети составляет 6,5 км - в предположении, что вся сеть выполнена на одном сегменте. Однако в реальности это невозможно, ведь предельная длина сегмента не превышает 2 км (для 10BASE-FL). Поэтому присутствие репитеров или концентраторов в сети максимального размера обязательно, а они внесут свой вклад в задержку прохождения сигнала по сети.
Возьмем простейшую конфигурацию сети из двух сегментов 10BASE-FL, соединенных концентратором (Рисунок 10.2).
Максимальная длина кабелей в конфигурации с одним концентратором
Таблица 10.3. Максимальная длина кабелей в конфигурации с одним концентратором
| Вид кабеля А | Вид кабеля В | Класс концентратора | Макс, длина кабеля А | Макс, длина кабеля В | Макс, размер сети, м | ||||||
| ТХ, Т4 | ТХ.Т4 | I или II | 100 | 100 | 200 | ||||||
| тх | FX | I | 100 | 160,8 | 260,8 | ||||||
| Т4 | FX | I | 100 | 131 | 231 | ||||||
| FX | FX | I | 136 | 136 | 272 | ||||||
| ТХ | FX | II | 100 | 208,8 | 308,8 | ||||||
| Т4 | FX | II | 100 | 204 | 304 | ||||||
| FX | FX | II | 160 | 160 | 320 |
Максимальная длина кабелей в конфигурации с двумя концентраторами
Таблица 10.4. Максимальная длина кабелей в конфигурации с двумя концентраторами
| Вид кабеля А | Вид кабеля В | Макс, длина кабеля А, м | Макс, длина кабеля В, м | Макс, размер сети | |||||
| ТХ,Т4 | ТХ,Т4 | 100 | 100 | 205 | |||||
| ТХ | FX | 100 | 116,2 | 221,2 | |||||
| Т4 | FX | 100 | 136,3 | 241,3 | |||||
| FX | FX | 114 | 114 | 233 |
В обеих конфигурациях с концентраторами при использовании одновременно электрического и оптоволоконного кабелей можно за счет уменьшения длины электрического кабеля увеличить длину оптоволоконного кабеля. Причем уменьшению длины электрического кабеля на 1 м соответствует увеличение длины оптоволоконного кабеля на 1,19 м. Например, уменьшив кабель ТХ на 10 м, можно увеличить кабель FX на 11,9 м, и его предельная длина составит при двух концентраторах 128,1 м. Немного увеличится и предельный размер сети (в нашем примере на 1,9 м).
В случае использования двух оптоволоконных кабелей можно уменьшать один из кабелей за счет увеличения другого. При уменьшении одного кабеля на 10 м можно увеличить другой тоже на 10м. Если же используется два электрических кабеля, то увеличивать один из них за счет уменьшения другого нельзя, так как их длина в принципе не может превышать 100 м из-за затухания сигнала в кабеле.
Отметим, что концентратор класса II в принципе не может одновременно поддерживать сегменты с разными методами кодирования TX/FX и Т4. Поэтому варианты, соответствующие вторым снизу строкам обеих таблиц 10.3 и 10.4 никогда не реализуются на практике, но стандарт почему-то дает цифры и для них.
Во всех перечисленных случаях под размером сети понимается размер зоны конфликта (области коллизии, collision domain). При этом надо учитывать, что включение в сеть одного коммутатора позволяет увеличить полный размер сети вдвое.
Пример сети максимальной конфигурации в соответствии с первой моделью для витой пары показан на Рисунок 10.7.
Двойные задержки компонентов
Таблица 10.5. Двойные задержки компонентов сети Fast Ethernet (величины задержек даны в битовых интервалах)
| Тип сегмента | Задержка на метр | Макс, задержка | |||
| Два абонента TX/FX | — | 100 | |||
| Два абонента Т4 | - | 138 | |||
| Один абонент Т4 и один TX/FX | — | 127 | |||
| Сегмент на кабеле категории 3 | 1,14 | 114 (100м) | |||
| Сегмент на кабеле категории 4 | 1,14 | 114 (100м) | |||
| Сегмент на кабеле категории 5 | 1,112 | 111,2 (100м) | |||
| Экранированная витая пара | 1,112 | 111, 2 (100м) | |||
| Оптоволоконный кабель | 1,0 | 412 (412м) | |||
| Репитер (концентратор) класса I | - | 140 | |||
| Репитер (концентратор) класса II с портами TX/FX | _ | 92 | |||
| Репитер (концентратор) класса II с портами Т4 | _ | 67 |
Для расчетов в соответствии со второй моделью сначала надо выделить в сети путь с максимальным двойным временем прохождения и максимальным числом репитеров (концентраторов) между компьютерами, то есть путь максимальной длины. Если таких путей несколько, то расчет должен производиться для каждого из них.
Расчет в данном случае ведется на основании таблицы 10.5.
Для вычисления полного двойного (кругового) времени прохождения для сегмента сети необходимо умножить длину сегмента на величину задержки на метр, взятую из второго столбца таблицы. Если сегмент имеет максимально возможную длину, то можно сразу взять величину максимальной задержки для данного сегмента из третьего столбца таблицы. Затем задержки сегментов, входящих в путь максимальной длины, надо просуммировать и прибавить к этой сумме величину задержки для приемопередающих узлов двух абонентов (это три верхние строчки таблицы) и величины задержек для всех репитеров (концентраторов), входящих в данный путь (это три нижние строки таблицы). Суммарная задержка должна быть меньше, чем 512 битовых интервалов. При этом надо помнить, что стандарт IEEE 802.3u рекомендует оставлять запас в пределах 1-4 битовых интервалов для учета кабелей внутри соединительных шкафов и погрешностей измерения, то есть лучше сравнивать суммарную задержку с величиной 508 битовых интервалов, а не 512 битовых интервалов.
Все задержки, приведенные в таблице, даны для наихудшего случая. Если известны временные характеристики конкретных кабелей, концентраторов и адаптеров, то практически всегда лучше использовать именно их. В ряде случаев это может дать заметную прибавку к допустимому размеру сети.
Рассмотрим пример расчета по второй модели для сети, показанной на Рисунок 10.7. Здесь существуют два максимальных пути: между компьютерами (сегменты А, В и С) и между верхним (по рисунку) компьютером и коммутатором (сегменты А, В и D). Оба эти пути включают в себя два 100-метровых сегмента и один 5-метровый. Предположим, что все сегменты представляют собой 100BASE-TX и выполнены на кабеле категории 5. Произведем расчет работоспособности сети.
1. Для двух 100-метровых сегментов (максимальной длины) из таблицы берем величину задержки 111,2 битовых интервалов.
2. Для 5-метрового сегмента высчитываем задержку, умножая 1,112 (задержка на метр) на длину кабеля (5 метров): 1,112 • 5 = 5,56 битовых интервалов.
3. Берем из таблицы задержку для двух абонентов ТХ - 100 битовых интервалов.
4. Берем из таблицы величины задержек для двух репитеров класса II - по 92 битовых интервала.
5.Суммируем все перечисленные задержки и получаем: 111,2 + 111,2 + 5,56 + 100 + 92 + 92 = 511,96, что меньше 512, следовательно, данная сеть будет работоспособна, хотя и на пределе, что, вообще говоря, не рекомендуется.
Для гарантии лучше несколько уменьшить длину кабелей или взять кабели, имеющие меньшую задержку (см. табл. 2.3). Например, при использовании кабеля AT&T 1061 (NVP = 0,7, t3= 0,477) мы получим следующие величины задержек для 100-метровых сегментов: (0,477 • 2) • 100 = 95,4 битовых интервалов (умножение на два необходимо, чтобы получить двойное время прохождения), а для 5-метрового сегмента - 4,77 битовых интервалов. Суммарная задержка при этом составит:
95,4 + 95,4 + 4,77 + 100 + 92 + 92 = 483,57,
то есть гораздо меньше 512 и даже 508, что означает полностью работоспособную сеть.
Пользуясь моделью 2, можно обойти некоторые ограничения модели 1, так как модель 1 рассчитывается для наихудшего случая.
Например, в сети может присутствовать больше двух концентраторов класса II или больше одного концентратора класса I, а кабель, соединяющий концентраторы, может быть длиннее 5 м.
Для примера на Рисунок 10.8 показана сеть, содержащая три концентратора класса II, соединенных между собой отрезками кабеля длиной по 10 м. Компьютеры присоединены к концентраторам сегментами 100BASE-TX длиной по 50 м. Произведем расчет двойного времени прохождения для этого случая.
1. Каждый из трех концентраторов класса II с портами ТХ даст задержку 92 битовых интервала. Суммарная задержка концентраторов будет равна 276 битовым интервалам.
2. Для двух соединительных кабелей между концентраторами задержка равна 2 • 1,112 • 10 = 2,24 битовых интервала.
3. Для двух сегментов ТХ по 50 метров задержка составит 2 • 1,112 • 50 = 111,2 битовых интервала.
Выбор конфигурации Ethernet
10.1. Выбор конфигурации Ethernet
При выборе конфигурации сети Ethernet, состоящей из сегментов различных типов, возникает много вопросов, связанных прежде всего с максимально допустимым размером (диаметром)4сети и максимально возможным числом различных элементов. Сеть будет работоспособной только в том случае, если максимальная задержка распространения сигнала в ней не превысит предельной величины. Эта величина определяется выбранным методом управления обменом CSMA/CD, основанным на обнаружении и разрешении коллизий.
Прежде всего отметим, что для получения сложных конфигураций Ethernet из отдельных сегментов применяются концентраторы двух уже упоминавшихся основных типов:
репитерные концентраторы, которые представляют собой набор репитеров и никак логически не разделяют сегменты, подключенные к ним;
коммутирующие (switching) концентраторы или коммутаторы, которые передают информацию между сегментами, но не передают конфликты с сегмента на сегмент.
В случае более сложных коммутирующих концентраторов конфликты в отдельных сегментах решаются на месте, в самих сегментах, и не распространяются по сети, как в случае более простых репитерных
концентраторов. Это имеет принципиальное значение для выбора топологии сети Ethernet, так как используемый в ней метод доступа CSMA/ CD предполагает наличие конфликтов и их разрешение, причем общая длина сети как раз и определяется размером зоны конфликта, области коллизии (collision domain). Таким образом, применение репитерного концентратора не разделяет зону конфликта, в то время как каждый коммутирующий концентратор делит зону конфликта на части. В случае коммутатора оценивать работоспособность надо для каждой части сети отдельно, а в случае репитерных концентраторов надо оценивать работоспособность всей сети в целом.
На практике репитерные концентраторы применяются гораздо чаще, так как они проще и дешевле. Поэтому мы будем в основном говорить в дальнейшем именно о них.
При выборе и оценке конфигурации Ethernet используются две основные модели. Остановимся кратко на их особенностях.
<
Выбор конфигурации Fast Ethernet
10.2. Выбор конфигурации Fast Ethernet
Точно так же, как и в случае Ethernet, для определения работоспособности сети Fast Ethernet стандарт IEEE 802.3 предлагает две модели, называемые Transmission System Model 1 и Transmission System Model 2. При этом первая модель основана на нескольких несложных правилах, а вторая использует систему точных расчетов. Первая модель исходит из того, что все компоненты сети (в частности, кабели) имеют наихудшие из возможных временные характеристики, поэтому она всегда дает результат со значительным запасом. Во второй модели можно использовать реальные временные характеристики кабелей, поэтому ее применение позволяет иногда преодолеть жесткие ограничения модели 1.
<
